
22 15. Bivariate analysis
Matthew DeCarlo
Chapter Outline
- What is bivariate data analysis? (5 minute read)
- Chi-square (4 minute read)
- Correlations (5 minute read)
- T-tests (5 minute read)
- ANOVA (6 minute read)
Content warning: examples in this chapter include discussions of anxiety symptoms.
So now we get to the math! Just kidding. Mostly. In this chapter, you are going to learn more about bivariate analysis, or analyzing the relationship between two variables. I don’t expect you to finish this chapter and be able to execute everything you just read about—instead, the big goal here is for you to be able to understand what bivariate analysis is, what kinds of analyses are available, and how you can use them in your research.
Take a deep breath, and let’s look at some numbers!
15.1 What is bivariate analysis?
Learning Objectives
Learners will be able to…
- Define bivariate analysis
- Explain when we might use bivariate analysis in social work research
Did you know that ice cream causes shark attacks? It’s true! When ice cream sales go up in the summer, so does the rate of shark attacks. So you’d better put down that ice cream cone, unless you want to make yourself look more delicious to a shark.

Ok, so it’s quite obviously not true that ice cream causes shark attacks. But if you looked at these two variables and how they’re related, you’d notice that during times of the year with high ice cream sales, there are also the most shark attacks. Despite the fact that the conclusion we drew about the relationship was wrong, it’s nonetheless true that these two variables appear related, and researchers figured that out through the use of bivariate analysis. (For a refresher on correlation versus causation, head back to Chapter 8.)
Bivariate analysis consists of a group of statistical techniques that examine the relationship between two variables. We could look at how anti-depressant medications and appetite are related, whether there is a relationship between having a pet and emotional well-being, or if a policy-maker’s level of education is related to how they vote on bills related to environmental issues.
Bivariate analysis forms the foundation of multivariate analysis, which we don’t get to in this book. All you really need to know here is that there are steps beyond bivariate analysis, which you’ve undoubtedly seen in scholarly literature already! But before we can move forward with multivariate analysis, we need to understand whether there are any relationships between our variables that are worth testing.
A study from Kwate, Loh, White, and Saldana (2012) illustrates this point. These researchers were interested in whether the lack of retail stores in predominantly Black neighborhoods in New York City could be attributed to the racial differences of those neighborhoods. Their hypothesis was that race had a significant effect on the presence of retail stores in a neighborhood, and that Black neighborhoods experience “retail redlining”—when a retailer decides not to put a store somewhere because the area is predominantly Black.
The researchers needed to know if the predominant race of a neighborhood’s residents was even related to the number of retail stores. With bivariate analysis, they found that “predominantly Black areas faced greater distances to retail outlets; percent Black was positively associated with distance to nearest store for 65 % (13 out of 20) stores” (p. 640). With this information in hand, the researchers moved on to multivariate analysis to complete their research.
Statistical significance
Before we dive into analyses, let’s talk about statistical significance. Statistical significance is the extent to which our statistical analysis has produced a result that is likely to represent a real relationship instead of some random occurrence. But just because a relationship isn’t random doesn’t mean it’s useful for drawing a sound conclusion.
We went into detail about statistical significance in Chapter 5. You’ll hopefully remember that there, we laid out some key principles from the American Statistical Association for understanding and using p-values in social science:
- P-values can indicate how incompatible the data are with a specified statistical model. P-values can provide evidence against the null hypothesis or the underlying assumptions of the statistical model the researchers used.
- P-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone. Both are inaccurate, though common, misconceptions about statistical significance.
- Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold. More nuance is needed to interpret scientific findings, as a conclusion does not become true or false when it passes from p=0.051 to p=0.049.
- Proper inference requires full reporting and transparency, rather than cherry-picking promising findings or conducting multiple analyses and only reporting those with significant findings. For the authors of this textbook, we believe the best response to this issue is for researchers make their data openly available to reviewers and general public and register their hypotheses in a public database prior to conducting analyses.
- A p-value, or statistical significance, does not measure the size of an effect or the importance of a result. In our culture, to call something significant is to say it is larger or more important, but any effect, no matter how tiny, can produce a small p-value if the study is rigorous enough. Statistical significance is not equivalent to scientific, human, or economic significance.
- By itself, a p-value does not provide a good measure of evidence regarding a model or hypothesis. For example, a p-value near 0.05 taken by itself offers only weak evidence against the null hypothesis. Likewise, a relatively large p-value does not imply evidence in favor of the null hypothesis; many other hypotheses may be equally or more consistent with the observed data. (adapted from Wasserstein & Lazar, 2016, p. 131-132).[1]
A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. The word significant can cause people to interpret these differences as strong and important, to the extent that they might even affect someone’s behavior. As we have seen however, these statistically significant differences are actually quite weak—perhaps even “trivial.” The correlation between ice cream sales and shark attacks is statistically significant, but practically speaking, it’s meaningless.
There is debate about acceptable p-values in some disciplines. In medical sciences, a p-value even smaller than 0.05 is often favored, given the stakes of biomedical research. Some researchers in social sciences and economics argue that a higher p-value of up to 0.10 still constitutes strong evidence. Other researchers think that p-values are entirely overemphasized and that there are better measures of statistical significance. At this point in your research career, it’s probably best to stick with 0.05 because you’re learning a lot at once, but it’s important to know that there is some debate about p-values and that you shouldn’t automatically discount relationships with a p-value of 0.06.

A note about “assumptions”
For certain types of bivariate, and in general for multivariate, analysis, we assume a few things about our data and the way it’s distributed. The characteristics we assume about our data that makes it suitable for certain types of statistical tests are called assumptions. For instance, we assume that our data has a normal distribution. While I’m not going to go into detail about these assumptions because it’s beyond the scope of the book, I want to point out that it is important to check these assumptions before your analysis.
Something else that’s important to note is that going through this chapter, the data analyses presented are merely for illustrative purposes—the necessary assumptions have not been checked. So don’t draw any conclusions based on the results shared.
For this chapter, I’m going to use a data set from IPUMS USA, where you can get individual-level, de-identified U.S. Census and American Community Survey data. The data are clean and the data sets are large, so it can be a good place to get data you can use for practice.
Key Takeaways
- Bivariate analysis is a group of statistical techniques that examine the relationship between two variables.
- You need to conduct bivariate analyses before you can begin to draw conclusions from your data, including in future multivariate analyses.
- Statistical significance and p-values help us understand the extent to which the relationships we see in our analyses are real relationships, and not just random or spurious.
Exercises
- Find a study from your literature review that uses quantitative analyses. What kind of bivariate analyses did the authors use? You don’t have to understand everything about these analyses yet!
- What do the p-values of their analyses tell you?
15.2 Chi-square
Learning Objectives
Learners will be able to…
- Explain the uses of Chi-square test for independence
- Explain what kind of variables are appropriate for a Chi-square test
- Interpret results of a Chi-square test and draw a conclusion about a hypothesis from the results
The first test we’re going to introduce you to is known as a Chi-square test (sometimes denoted as χ2) and is foundational to analyzing relationships between nominal or ordinal variables. A Chi-square test for independence (Chi-square for short) is a statistical test to determine whether there is a significant relationship between two nominal or ordinal variables. The “test for independence” refers to the null hypothesis of our comparison—that the two variables are independent and have no relationship.
A Chi-square can only be used for the relationship between two nominal or ordinal variables—there are other tests for relationships between other types of variables that we’ll talk about later in this chapter. For instance, you could use a Chi-square to determine whether there is a significant relationship between a person’s self-reported race and whether they have health insurance through their employer. (We will actually take a look at this a little later.)
Chi-square tests the hypothesis that there is a relationship between two categorical variables by comparing the values we actually observed and the value we would expect to occur based on our null hypothesis. The expected value is a calculation based on your data when it’s in a summarized form called a contingency table, which is a visual representation of a cross-tabulation of categorical variables to demonstrate all the possible occurrences of your categories. I know that sounds complex, so let’s look at an example.
Earlier, we talked about looking at the relationship between a person’s race and whether they have health insurance through an employer. Based on 2017 American Community Survey data from IPUMS, this is what a contingency table for these two variables would look like.
| Race | No insurance through employer/union | Has insurance through employer/union | Total |
| White | 1,037,071 | 1,401,453 | 2,438,524 |
| Black/African American | 177,648 | 177,648 | 317,308 |
| American Indian or Alaska Native | 24,123 | 12,142 | 36,265 |
| Asian or Pacific Islander | 71,155 | 105,596 | 176,751 |
| Another race | 75,117 | 46,699 | 121,816 |
| Two or more major races | 46,107 | 53,269 | 87,384 |
| Total | 1,431,221 | 1,758,819 | 3,190,040 |
So now we know what our observed values for these categories are. Next, let’s think about our expected values. We don’t need to get so far into it as to put actual numbers to it, but we can come up with a hypothesis based on some common knowledge about racial differences in employment. (We’re going to be making some generalizations here, so remember that there can be exceptions.)
An applied example
Let’s say research shows that people who identify as black, indigenous, and people of color (BIPOC) tend to hold multiple part-time jobs and have a higher unemployment rate in general. Given that, our hypothesis based on this data could be that BIPOC people are less likely to have employer-provided health insurance. Before we can assess a likelihood, we need to know if these to variables are even significantly related. Here’s where our Chi-square test comes in!
I’ve used SPSS to run these tests, so depending on what statistical program you use, your outputs might look a little different.

There are a number of different statistics reported here. What I want you to focus on is the first line, the Pearson Chi-Square, which is the most commonly used statistic for larger samples that have more than two categories each. (The other two lines are alternatives to Pearson that SPSS puts out automatically, but they are appropriate for data that is different from ours, so you can ignore them. You can also ignore the “df” column for now, as it’s a little advanced for what’s in this chapter.)
The last column gives us our statistical significance level, which in this case is 0.00. So what conclusion can we draw here? The significant Chi-square statistic means we can reject the null hypothesis (which is that our two variables are not related). There is likely a strong relationship between our two variables that is probably not random, meaning that we should further explore the relationship between a person’s race and whether they have employer-provided health insurance. Are there other factors that affect the relationship between these two variables? That seems likely. (One thing to keep in mind is that this is a large data set, which can inflate statistical significance levels. However, for the purposes of our exercises, we’ll ignore that for now.)
What we cannot conclude is that these two variables are causally related. That is, someone’s race doesn’t cause them to have employer-provided health insurance or not. It just appears to be a contributing factor, but we are not accounting for the effect of other variables on the relationship we observe (yet).
Key Takeaways
- The Chi-square test is designed to test the null hypothesis that our two variables are not related to each other.
- The Chi-square test is only appropriate for nominal and/or ordinal variables.
- A statistically significant Chi-square statistic means we can reject the null hypothesis and assume our two variables are, in fact, related.
- A Chi-square test doesn’t let us draw any conclusions about causality because it does not account for the influence of other variables on the relationship we observe.
Exercises
Think about the data you could collect or have collected for your research project. If you were to conduct a chi-square test, consider:
- Which two variables would you most like to use in the analysis?
- What about the relationship between these two variables interests you in light of what your literature review has shown so far?
15.3 Correlations
Learning Objectives
Learners will be able to…
- Define correlation and understand how to use it in quantitative analysis
- Explain what kind of variables are appropriate for a correlation
- Interpret a correlation coefficient
- Define the different types of correlation—positive and negative
- Interpret results of a correlation and draw a conclusion about a hypothesis from the results
A correlation is a relationship between two variables in which their values change together. For instance, we might expect education and income to be correlated—as a person’s educational attainment (how much schooling they have completed) goes up, so does their income. What about minutes of exercise each week and blood pressure? We would probably expect those who exercise more have lower blood pressures than those who don’t. We can test these relationships using correlation analyses. Correlations are appropriate only for two interval/ratio variables.

It’s very important to understand that correlations can tell you about relationships, but not causes—as you’ve probably already heard, correlation is not causation! Go back to our example about shark attacks and ice cream sales from the beginning of the chapter. Clearly, ice cream sales don’t cause shark attacks, but the two are strongly correlated (most likely because both increase in the summer for other reasons). This relationship is an example of a spurious relationship, or a relationship that appears to exist between to variables, but in fact does not and is caused by other factors. We hear about these all the time in the news and correlation analyses are often misrepresented. As we talked about in Chapter 4 when discussing critical information literacy, your job as a researcher and informed social worker is to make sure people aren’t misstating what these analyses actually mean, especially when they are being used to harm vulnerable populations.
An applied example
Let’s say we’re looking at the relationship between age and income among indigenous people in the United States. In the data set we’ve been using so far, these folks generally fall into the racial category of American Indian/Alaska native, so we’ll use that category because it’s the best we can do. Using SPSS, this is the output you’d get with these two variables for this group. We’ll also limit the analysis to people age 18 and over since children are unlikely to report an individual income.

Here’s Pearson again, but don’t be confused—this is not the same test as the Chi-square, it just happens to be named after the same person. First, let’s talk about the number next to Pearson Correlation, which is the correlation coefficient. The correlation coefficient is a statistically derived value between -1 and 1 that tells us the magnitude and direction of the relationship between two variables. A statistically significant correlation coefficient like the one in this table (denoted by a p-value of 0.01) means the relationship is not random.
The magnitude of the relationship is how strong the relationship is and can be determined by the absolute value of the coefficient. In the case of our analysis in the table above, the correlation coefficient is 0.108, which denotes a pretty weak relationship. This means that, among the population in our sample, age and income don’t have much of an effect on each other. (If the correlation coefficient were -0.108, the conclusion about its strength would be the same.)
In general, you can say that a correlation coefficient with an absolute value below 0.5 represents a weak correlation. Between 0.5 and 0.75 represents a moderate correlation, and above 0.75 represents a strong correlation. Although the relationship between age and income in our population is statistically significant, it’s also very weak.
The sign on your correlation coefficient tells you the direction of your relationship. A positive correlation or direct relationship occurs when two variables move together in the same direction—as one increases, so does the other, or, as one decreases, so does the other. Correlation coefficients will be positive, so that means the correlation we calculated is a positive correlation and the two variables have a direct, though very weak, relationship. For instance, in our example about shark attacks and ice cream, the number of both shark attacks and pints of ice cream sold would go up, meaning there is a direct relationship between the two.
A negative correlation or inverse relationship occurs when two variables change in opposite directions—one goes up, the other goes down and vice versa. The correlation coefficient will be negative. For example, if you were studying social media use and found that time spent on social media corresponded to lower scores on self-esteem scales, this would represent an inverse relationship.
Correlations are important to run at the outset of your analyses so you can start thinking about how variables relate to each other and whether you might want to include them in future multivariate analyses. For instance, if you’re trying to understand the relationship between receipt of an intervention and a particular outcome, you might want to test whether client characteristics like race or gender are correlated with your outcome; if they are, they should be plugged into subsequent multivariate models. If not, you might want to consider whether to include them in multivariate models.
A final note
Just because the correlation between your dependent variable and your primary independent variable is weak or not statistically significant doesn’t mean you should stop your work. For one thing, disproving your hypothesis is important for knowledge-building. For another, the relationship can change when you consider other variables in multivariate analysis, as they could mediate or moderate the relationships.
Key Takeaways
- Correlations are a basic measure of the strength of the relationship between two interval/ratio variables.
- A correlation between two variables does not mean one variable causes the other one to change. Drawing conclusions about causality from a simple correlation is likely to lead to you to describing a spurious relationship, or one that exists at face value, but doesn’t hold up when more factors are considered.
- Correlations are a useful starting point for almost all data analysis projects.
- The magnitude of a correlation describes its strength and is indicated by the correlation coefficient, which can range from -1 to 1.
- A positive correlation, or direct relationship, occurs when the values of two variables move together in the same direction.
- A negative correlation, or inverse relationship, occurs when the value of one variable moves one direction, while the value of the other variable moves the opposite direction.
Exercises
Think about the data you could collect or have collected for your research project. If you were to conduct a correlation analysis, consider:
- Which two variables would you most like to use in the analysis?
- What about the relationship between these two variables interests you in light of what your literature review has shown so far?
15.4 T-tests
Learning Objectives
Learners will be able to…
- Describe the three different types of t-tests and when to use them.
- Explain what kind of variables are appropriate for t-tests.
At a very basic level, t-tests compare the means between two groups, the same group at two points in time, or a group and a hypothetical mean. By doing so using this set of statistical analyses, you can learn whether these differences are reflective of a real relationship or not (whether they are statistically significant).
Say you’ve got a data set that includes information about marital status and personal income (which we do!). You want to know if married people have higher personal (not family) incomes than non-married people, and whether the difference is statistically significant. Essentially, you want to see if the difference in average income between these two groups is down to chance or if it warrants further exploration. What analysis would you run to find this information? A t-test!
A lot of social work research focuses on the effect of interventions and programs, so t-tests can be particularly useful. Say you were studying the effect of a smoking cessation hotline on the number of days participants went without smoking a cigarette. You might want to compare the effect for men and women, in which case you’d use an independent samples t-test. If you wanted to compare the effect of your smoking cessation hotline to others in the country and knew the results of those, you would use a one-sample t-test. And if you wanted to compare the average number of cigarettes per day for your participants before they started a tobacco education group and then again when they finished, you’d use a paired-samples t-test. Don’t worry—we’re going into each of these in detail below.
So why are they called t-tests? Basically, when you conduct a t-test, you’re comparing your data to a theoretical distribution of data known as the t distribution to get the t statistic. The t distribution is normal, so when your data are not normally distributed, a t distribution can approximate a normal distribution well enough for you to test some hypotheses. (Remember our discussion of assumptions in section 15.1—one of them is that data be normally distributed.) Ultimately, the t statistic that the test produces allows you to determine if any differences are statistically significant.
For t-tests, you need to have an interval/ratio dependent variable and a nominal or ordinal independent variable. Basically, you need an average (using an interval or ratio variable) to compare across mutually exclusive groups (using a nominal or ordinal variable).
Let’s jump into the three different types of t-tests.
Paired samples t-test
The paired samples t-test is used to compare two means for the same sample tested at two different times or under two different conditions. This comparison is appropriate for pretest-post-test designs or within-subjects experiments. The null hypothesis is that the means at the two times or under the two conditions are the same in the population. The alternative hypothesis is that they are not the same.
For example, say you are testing the effect of pet ownership on anxiety symptoms. You have access to a group of people who have the same diagnosis involving anxiety who do not have pets, and you give them a standardized anxiety inventory questionnaire. Then, each of these participants gets some kind of pet and after 6 months, you give them the same standardized anxiety questionnaire.
To compare their scores on the questionnaire at the beginning of the study and after 6 months of pet ownership, you would use paired samples t-test. Since the sample includes the same people, the samples are “paired” (hence the name of the test). If the t-statistic is statistically significant, there is evidence that owning a pet has an effect on scores on your anxiety questionnaire.
Independent samples/two samples t-test
An independent/two samples t-test is used to compare the means of two separate samples. The two samples might have been tested under different conditions in a between-subjects experiment, or they could be pre-existing groups in a cross-sectional design (e.g., women and men, extroverts and introverts). The null hypothesis is that the means of the two populations are the same. The alternative hypothesis is that they are not the same.
Let’s go back to our example related to anxiety diagnoses and pet ownership. Say you want to know if people who own pets have different scores on certain elements of your standard anxiety questionnaire than people who don’t own pets.
You have access to two groups of participants: pet owners and non-pet owners. These groups both fit your other study criteria. You give both groups the same questionnaire at one point in time. You are interested in two questions, one about self-worth and one about feelings of loneliness. You can calculate mean scores for the questions you’re interested in and then compare them across two groups. If the t-statistic is statistically significant, then there is evidence of a difference in these scores that may be due to pet ownership.
One-sample t-test
Finally, let’s talk about a one sample t-test. This t-test is appropriate when there is an external benchmark to use for your comparison mean, either known or hypothesized. The null hypothesis for this kind of test is that the mean in your sample is different from the mean of the population. The alternative hypothesis is that the means are different.
Let’s say you know the average years of post-high school education for Black women, and you’re interested in learning whether the Black women in your study are on par with the average. You could use a one-sample t-test to determine how your sample’s average years of post-high school education compares to the known value in the population. This kind of t-test is useful when a phenomenon or intervention has already been studied, or to see how your sample compares to your larger population.
Key Takeaways
- There are three types of t-tests that are each appropriate for different situations. T-tests can only be used with an interval/ratio dependent variable and a nominal/ordinal independent variable.
- T-tests in general compare the means of one variable between either two points in time or conditions for one group, two different groups, or one group to an external benchmark variable..
- In a paired-samples t-test, you are comparing the means of one variable in your data for the same group, either at two different times or under two different conditions, and testing whether the difference is statistically significant.
- In an independent samples t-test, you are comparing the means of one variable in your data for two different groups to determine if any difference is statistically significant.
- In a one-sample t-test, you are comparing the mean of one variable in your data to an external benchmark, either observed or hypothetical.
Exercises
Think about the data you could collect or have collected for your research project. If you were to conduct a t-test, consider:
- Which t-test makes the most sense for your data and research design? Why?
- Which variable would be an appropriate dependent variable? Why?
- Which variable would be an interesting independent variable? Why?
15.5 ANOVA (ANalysis Of VAriance)
Learning Objectives
Learners will be able to…
- Explain what kind of variables are appropriate for ANOVA
- Explain the difference between one-way and two-way ANOVA
- Come up with an example of when each type of ANOVA is appropriate
Analysis of variance, generally abbreviated to ANOVA for short, is a statistical method to examine how a dependent variable changes as the value of a categorical independent variable changes. It serves the same purpose as the t-tests we learned in 15.4: it tests for differences in group means. ANOVA is more flexible in that it can handle any number of groups, unlike t-tests, which are limited to two groups (independent samples) or two time points (dependent samples). Thus, the purpose and interpretation of ANOVA will be the same as it was for t-tests.
There are two types of ANOVA: a one-way ANOVA and a two-way ANOVA. One-way ANOVAs are far more common than two-way ANOVAs.
One-way ANOVA
The most common type of ANOVA that researchers use is the one-way ANOVA, which is a statistical procedure to compare the means of a variable across three or more groups of an independent variable. Let’s take a look at some data about income of different racial and ethnic groups in the United States. The data in Table 15.2 below comes from the US Census Bureau’s 2018 American Community Survey[2]. The racial and ethnic designations in the table reflect what’s reported by the Census Bureau, which is not fully representative of how people identify racially.
| Race | Average income |
| American Indian and Alaska Native | $20,709 |
| Asian | $40,878 |
| Black/African American | $23,303 |
| Native Hawaiian or Other Pacific Islander | $25,304 |
| White | $36,962 |
| Two or more races | $19,162 |
| Another race | $20,482 |
Off the bat, of course, we can see a difference in the average income between these groups. Now, we want to know if the difference between average income of these racial and ethnic groups is statistically significant, which is the perfect situation to use one-way ANOVA. To conduct this analysis, we need the person-level data that underlies this table, which I was able to download from IPUMS. For this analysis, race is the independent variable (nominal) and total income is the dependent variable (interval/ratio). Let’s assume for this exercise that we have no other data about the people in our data set besides their race and income. (If we did, we’d probably do another type of analysis.)
I used SPSS to run a one-way ANOVA using this data. With the basic analysis, the first table in the output was the following.

Without going deep into the statistics, the column labeled “F” represents our F statistic, which is similar to the T statistic in a t-test in that it gives a statistical point of comparison for our analysis. The important thing to noticed here, however, is our significance level, which is .000. Sounds great! But we actually get very little information here—all we know is that the between-group differences are statistically significant as a whole, but not anything about the individual groups.
This is where post hoc tests come into the picture. Because we are comparing each race to each other race, that adds up to a lot of comparisons, and statistically, this increases the likelihood of a type I error. A post hoc test in ANOVA is a way to correct and reduce this error after the fact (hence “post hoc”). I’m only going to talk about one type—the Bonferroni correction—because it’s commonly used. However, there are other types of post hoc tests you may encounter.
When I tell SPSS to run the ANOVA with a Bonferroni correction, in addition to the table above, I get a very large table that runs through every single comparison I asked it to make among the groups in my independent variable—in this case, the different races. Figure 15.4 below is the first grouping in that table—they will all give the same conceptual information, though some of the signs on the mean difference and, consequently the confidence intervals, will vary.
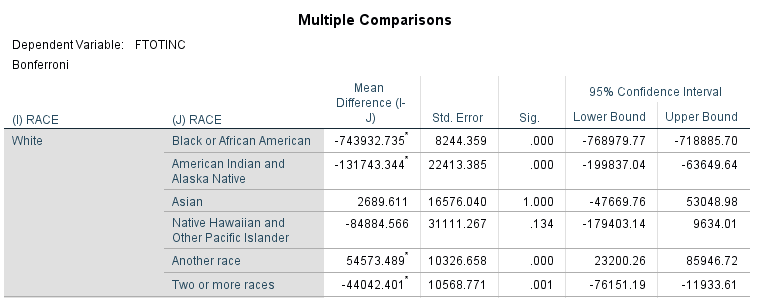
Now we see some points of interest. As you’d expect knowing what we know from prior research, race seems to have a pretty strong influence on a person’s income. (Notice I didn’t say “effect”—we don’t have enough information to establish causality!) The significance levels for the mean of White people’s incomes compared to the mean of several races are .000. Interestingly, for Asian people in the US, race appears to have no influence on their income compared to White people in the US. The significance level for Native Hawaiians and Pacific Islanders is also relatively high.
So what does this mean? We can say with some confidence that, overall, race seems to influence a person’s income. In our hypothetical data set, since we only have race and income, this is a great analysis to conduct. But do we think that’s the only thing that influences a person’s income? Probably not. To look at other factors if we have them, we can use a two-way ANOVA.
Two-way ANOVA and n-way ANOVA
A two-way ANOVA is a statistical procedure to compare the means of a variable across groups using multiple independent variables to distinguish among groups. For instance, we might want to examine income by both race and gender, in which case, we would use a two-way ANOVA. Fundamentally, the procedures and outputs for two-way ANOVA are almost identical to one-way ANOVA, just with more cross-group comparisons, so I am not going to run through an example in SPSS for you.
You may also see textbooks or scholarly articles refer to n-way ANOVAs. Essentially, just like you’ve seen throughout this book, the n can equal just about any number. However, going far beyond a two-way ANOVA increases your likelihood of a type I error, for the reasons discussed in the previous section.
A final note
You may notice that this book doesn’t get into multivariate analysis at all. Regression analysis, which you’ve no doubt seen in many academic articles you’ve read, is an incredibly complex topic. There are entire courses and textbooks on the multiple different types of regression analysis, and we did not think we could adequately cover regression analysis at this level. Don’t let that scare you away from learning about it—just understand that we don’t expect you to know about it at this point in your research learning.
Key Takeaways
- One-way ANOVA is a statistical procedure to compare the means of a variable across three or more categories of an independent variable. This analysis can help you understand whether there are meaningful differences in your sample based on different categories like race, geography, gender, or many others.
- Two-way ANOVA is almost identical to one-way ANOVA, except that you can compare the means of a variable across multiple independent variables.
Exercises
Think about the data you could collect or have collected for your research project. If you were to conduct a one-way ANOVA, consider:
- Which variable would be an appropriate dependent variable? Why?
- Which variable would be an interesting independent variable? Why?
- Would you want to conduct a two-way or n-way ANOVA? If so, what other independent variables would you use, and why?
- Wasserstein, R. L., & Lazar, N. A. (2016). The ASA statement on p-values: context, process, and purpose. The American Statistician, 70, p. 129-133. ↵
- Steven Ruggles, Sarah Flood, Ronald Goeken, Josiah Grover, Erin Meyer, Jose Pacas and Matthew Sobek. IPUMS USA: Version 10.0 [dataset]. Minneapolis, MN: IPUMS, 2020. https://doi.org/10.18128/D010.V10.0 ↵
A type of reliability in which multiple forms of a tool yield the same results from the same participants.
The extent to which scores obtained on a scale or other measure are consistent across time
Context is the circumstances surrounding an artifact, event, or experience.
variables whose values are mutually exclusive and can be used in mathematical operations
Variables with finite value choices.
“a planned process that involves consideration of target audiences and the settings in which research findings are to be received and, where appropriate, communicating and interacting with wider policy and…service audiences in ways that will facilitate research uptake in decision-making processes and practice” (Wilson, Petticrew, Calnan, & Natareth, 2010, p. 91)
the tendency for a pattern to occur at regular intervals
the process by which the researcher informs potential participants about the study and attempts to get them to participate
In nonequivalent comparison group designs, the process in which researchers match the population profile of the comparison and experimental groups.
In nonequivalent comparison group designs, the process by which researchers match individual cases in the experimental group to similar cases in the comparison group.
The bias that occurs when those who respond to your request to participate in a study are different from those who do not respond to you request to participate in a study.
Chapter outline
- 15.1 Alternative paradigms: Interpretivism, critical paradigm, and pragmatism
- 15.2 Multiparadigmatic research: An example
- 15.3 Idiographic causal relationships
- 15.4 Qualitative research questions
Now let's change things up! In the previous chapters, we explored steps to create and carry out a quantitative research study. Quantitative studies are great when we want to summarize or test relationships between ideas using numbers and the power of statistics. However, qualitative research offers us a different and equally important tool. Sometimes the aim of research projects is to explore meaning and lived experience. Instead of trying to arrive at generalizable conclusions for all people, some research projects establish a deep, authentic description of a specific time, place, and group of people.
Qualitative research relies on the power of human expression through words, pictures, movies, performance and other artifacts that represent these things. All of these tell stories about the human experience and we want to learn from them and have them be represented in our research. Generally speaking, qualitative research is about the gathering up of these stories, breaking them into pieces so we can examine the ideas that make them up, and putting them back together in a way that allows us to tell a common or shared story that responds to our research question. To do that, we need to discuss the assumptions underlying social science.
17.1 Alternative paradigms: Interpretivism, critical, and pragmatism
Learning Objectives
Students will be able to...
- Distinguish between the assumptions of positivism, interpretivism, critical, and pragmatist research paradigms.
- Use paradigm to describe how scientific thought changes over time.
In Chapter 10, we reviewed the assumptions that underly post-positivism (abbreviated hereafter as positivism for brevity). Quantitative methods are most often the choice for positivist research questions because they conform to these assumptions. Qualitative methods can conform to these assumptions; however, they are limited in their generalizability.
Kivunja & Kuyini (2017)[1] describe the essential features of positivism as:
- A belief that theory is universal and law-like generalizations can be made across contexts
- The assumption that context is not important
- The belief that truth or knowledge is ‘out there to be discovered’ by research
- The belief that cause and effect are distinguishable and analytically separable
- The belief that results of inquiry can be quantified
- The belief that theory can be used to predict and to control outcomes
- The belief that research should follow the scientific method of investigation
- Rests on formulation and testing of hypotheses
- Employs empirical or analytical approaches
- Pursues an objective search for facts
- Believes in ability to observe knowledge
- The researcher’s ultimate aim is to establish a comprehensive universal theory, to account for human and social behavior
- Application of the scientific method
Because positivism is the dominant social science research paradigm, it can be easy to ignore or be confused by research that does not use these assumptions. We covered in Chapter 10 the table reprinted below when discussing the assumptions underlying positivistic social science.
As you consider your research project, keep these philosophical assumptions in mind. They are useful shortcuts to understanding the deeper ideas and assumptions behind the construction of knowledge. The purpose of exploring these philosophical assumptions isn't to find out which is true and which is false. Instead, the goal is to identify the assumptions that fit with how you think about your research question. Choosing a paradigm helps you make those assumptions explicit.
| Assumptions | Central conflicts |
| Ontology: assumptions about what is real | Realism vs. anti-realism (a.k.a. relativism) |
| Epistemology: assumptions about how we come to know what is real | Objective truth vs. subjective truths
Math vs. language/expression Prediction vs. understanding |
| Assumptions about the researcher | Researcher as unbiased vs. researcher shaped by oppression, culture, and history
Researcher as neutral force vs. researcher as oppressive force |
| Assumptions about human action | Determinism vs. free will
Holism vs. individualism |
| Assumptions about the social world | Orderly and consensus-focused vs. disorderly and conflict-focused |
| Assumptions about the purpose of research | Study the status quo vs. create radical change
Values-neutral vs. values-informed |
Before we explore alternative paradigms, it's important for us to review what paradigms are.
How do scientific ideas change over time?
Much like your ideas develop over time as you learn more, so does the body of scientific knowledge. Kuhn’s (1962)[2] The Structure of Scientific Revolutions is one of the most influential works on the philosophy of science, and is credited with introducing the idea of competing paradigms (or “disciplinary matrices”) in research. Kuhn investigated the way that scientific practices evolve over time, arguing that we don’t have a simple progression from “less knowledge” to “more knowledge” because the way that we approach inquiry is changing over time. This can happen gradually, but the process results in moments of change where our understanding of a phenomenon changes more radically (such as in the transition from Newtonian to Einsteinian physics; or from Lamarckian to Darwinian theories of evolution). For a social work practice example, Fleuridas & Krafcik (2019)[3] trace the development of the "four forces" of psychotherapy, from psychodynamics to behaviorism to humanism as well as the competition among emerging perspectives to establish itself as the fourth force to guide psychotherapeutic practice. But how did the problems in one paradigm inspire new paradigms? Kuhn presents us with a way of understanding the history of scientific development across all topics and disciplines.
As you can see in this video from Matthew J. Brown (CC-BY), there are four stages in the cycle of science in Kuhn’s approach. Firstly, a pre-paradigmatic state where competing approaches share no consensus. Secondly, the “normal” state where there is wide acceptance of a particular set of methods and assumptions. Thirdly, a state of crisis where anomalies that cannot be solved within the existing paradigm emerge and competing theories to address them follow. Fourthly, a revolutionary phase where some new paradigmatic approach becomes dominant and supplants the old. Shnieder (2009)[4] suggests that the Kuhnian phases are characterized by different kinds of scientific activity.
Newer approaches often build upon rather than replace older ones, but they also overlap and can exist within a state of competition. Scientists working within a particular paradigm often share methods, assumptions and values. In addition to supporting specific methods, research paradigms also influence things like the ambition and nature of research, the researcher-participant relationship and how the role of the researcher is understood.
Paradigm vs. theory
The terms 'paradigm' and 'theory' are often used interchangeably in social science. There is not a consensus among social scientists as to whether these are identical or distinct concepts. With that said, in this text, we will make a clear distinction between the two ideas because thinking about each concept separately is more useful for our purposes.
We define paradigm a set of common philosophical (ontological, epistemological, and axiological) assumptions that inform research. The four paradigms we describe in this section refer to patterns in how groups of researchers resolve philosophical questions. Some assumptions naturally make sense together, and paradigms grow out of researchers with shared assumptions about what is important and how to study it. Paradigms are like “analytic lenses” and a provide framework on top of which we can build theoretical and empirical knowledge (Kuhn, 1962).[5] Consider this video of an interview with world-famous physicist Richard Feynman in which he explains why "when you explain a 'why,' you have to be in some framework that you allow something to be true. Otherwise, you are perpetually asking why." In order to answer basic physics question like "what is happening when two magnets attract?" or a social work research question like "what is the impact of this therapeutic intervention on depression," you must understand the assumptions you are making about social science and the social world. Paradigmatic assumptions about objective and subjective truth support methodological choices like whether to conduct interviews or send out surveys, for example.
While paradigms are broad philosophical assumptions, theory is more specific, and refers to a set of concepts and relationships scientists use to explain the social world. Theories are more concrete, while paradigms are more abstract. Look back to Figure 7.1 at the beginning of this chapter. Theory helps you identify the concepts and relationships that align with your paradigmatic understanding of the problem. Moreover, theory informs how you will measure the concepts in your research question and the design of your project.
For both theories and paradigms, Kuhn's observation of scientific paradigms, crises, and revolutions is instructive for understanding the history of science. Researchers inherit institutions, norms, and ideas that are marked by the battlegrounds of theoretical and paradigmatic debates that stretch back hundreds of years. We have necessarily simplified this history into four paradigms: positivism, interpretivism, critical, and pragmatism. Our framework and explanation are inspired by the framework of Guba and Lincoln (1990)[6] and Burrell and Morgan (1979).[7] while also incorporating pragmatism as a way of resolving paradigmatic questions. Most of social work research and theory can be classified as belonging to one of these four paradigms, though this classification system represents only one of many useful approaches to analyzing social science research paradigms.
Building on our discussion in section 7.1 on objective vs. subjective epistemologies and ontologies, we will start with the difference between positivism and interpretivism. Afterward, we will link our discussion of axiology in section 7.2 with the critical paradigm. Finally, we will situate pragmatism as a way to resolve paradigmatic questions strategically. The difference between positivism and interpretivism is a good place to start, since the critical paradigm and pragmatism build on their philosophical insights.
It's important to think of paradigms less as distinct categories and more as a spectrum along which projects might fall. For example, some projects may be somewhat positivist, somewhat interpretivist, and a little critical. No project fits perfectly into one paradigm. Additionally, there is no paradigm that is more correct than the other. Each paradigm uses assumptions that are logically consistent, and when combined, are a useful approach to understanding the social world using science. The purpose of this section is to acquaint you with what research projects in each paradigm look like and how they are grounded in philosophical assumptions about social science.
You should read this section to situate yourself in terms of what paradigm feels most "at home" to both you as a person and to your project. You may find, as I have, that your research projects are more conventional and less radical than what feels most like home to you, personally. In a research project, however, students should start with their working question rather than their heart. Use the paradigm that fits with your question the best, rather than which paradigm you think fits you the best.

Interpretivism: Researcher as "empathizer"
Positivism is focused on generalizable truth. Interpretivism, by contrast, develops from the idea that we want to understand the truths of individuals, how they interpret and experience the world, their thought processes, and the social structures that emerge from sharing those interpretations through language and behavior. The process of interpretation (or social construction) is guided by the empathy of the researcher to understand the meaning behind what other people say.
Historically, interpretivism grew out of a specific critique of positivism: that knowledge in the human and social sciences cannot conform to the model of natural science because there are features of human experience that cannot objectively be “known”. The tools we use to understand objects that have no self-awareness may not be well-attuned to subjective experiences like emotions, understandings, values, feelings, socio-cultural factors, historical influences, and other meaningful aspects of social life. Instead of finding a single generalizable “truth,” the interpretivist researcher aims to generate understanding and often adopts a relativist position.
While positivists seek “the truth,” the social constructionist framework argues that “truth” varies. Truth differs based on who you ask, and people change what they believe is true based on social interactions. These subjective truths also exist within social and historical contexts, and our understanding of truth varies across communities and time periods. This is because we, according to this paradigm, create reality ourselves through our social interactions and our interpretations of those interactions. Key to the interpretivist perspective is the idea that social context and interaction frame our realities.
Researchers operating within this framework take keen interest in how people come to socially agree, or disagree, about what is real and true. Consider how people, depending on their social and geographical context, ascribe different meanings to certain hand gestures. When a person raises their middle finger, those of us in Western cultures will probably think that this person isn't very happy (not to mention the person at whom the middle finger is being directed!). In other societies around the world, a thumbs-up gesture, rather than a middle finger, signifies discontent (Wong, 2007).[8] The fact that these hand gestures have different meanings across cultures aptly demonstrates that those meanings are socially and collectively constructed. What, then, is the "truth" of the middle finger or thumbs up? As we've seen in this section, the truth depends on the intention of the person making the gesture, the interpretation of the person receiving it, and the social context in which the action occurred.
Qualitative methods are preferred as ways to investigate these phenomena. Data collected might be unstructured (or “messy”) and correspondingly a range of techniques for approaching data collection have been developed. Interpretivism acknowledges that it is impossible to remove cultural and individual influence from research, often instead making a virtue of the positionality of the researcher and the socio-cultural context of a study.
One common objection positivists levy against interpretivists is that interpretivism tends to emphasize the subjective over the objective. If the starting point for an investigation is that we can’t fully and objectively know the world, how can we do research into this without everything being a matter of opinion? For the positivist, this risk for confirmation bias as well as invalid and unreliable measures makes interpretivist research unscientific. Clearly, we disagree with this assessment, and you should, too. Positivism and interpretivism have different ontologies and epistemologies with contrasting notions of rigor and validity (for more information on assumptions about measurement, see Chapter 11 for quantitative validity and reliability and Chapter 20 for qualitative rigor). Nevertheless, both paradigms apply the values and concepts of the scientific method through systematic investigation of the social world, even if their assumptions lead them to do so in different ways. Interpretivist research often embraces a relativist epistemology, bringing together different perspectives in search of a trustworthy and authentic understanding or narrative.
Kivunja & Kuyini (2017)[9] describe the essential features of interpretivism as:
- The belief that truths are multiple and socially constructed
- The acceptance that there is inevitable interaction between the researcher and his or her research participants
- The acceptance that context is vital for knowledge and knowing
- The belief that knowledge can be value laden and the researcher's values need to be made explicit
- The need to understand specific cases and contexts rather deriving universal laws that apply to everyone, everywhere.
- The belief that causes and effects are mutually interdependent, and that causality may be circular or contradictory
- The belief that contextual factors need to be taken into consideration in any systematic pursuit of understanding
One important clarification: it's important to think of the interpretivist perspective as not just about individual interpretations but the social life of interpretations. While individuals may construct their own realities, groups—from a small one such as a married couple to large ones such as nations—often agree on notions of what is true and what “is” and what "is not." In other words, the meanings that we construct have power beyond the individuals who create them. Therefore, the ways that people and communities act based on such meanings is of as much interest to interpretivists as how they were created in the first place. Theories like social constructionism, phenomenology, and symbolic interactionism are often used in concert with interpretivism.
Is interpretivism right for your project?
An interpretivist orientation to research is appropriate when your working question asks about subjective truths. The cause-and-effect relationships that interpretivist studies produce are specific to the time and place in which the study happened, rather than a generalizable objective truth. More pragmatically, if you picture yourself having a conversation with participants like an interview or focus group, then interpretivism is likely going to be a major influence for your study.
Positivists critique the interpretivist paradigm as non-scientific. They view the interpretivist focus on subjectivity and values as sources of bias. Positivists and interpretivists differ on the degree to which social phenomena are like natural phenomena. Positivists believe that the assumptions of the social sciences and natural sciences are the same, while interpretivists strongly believe that social sciences differ from the natural sciences because their subjects are social creatures.
Similarly, the critical paradigm finds fault with the interpretivist focus on the status quo rather than social change. Although interpretivists often proceed from a feminist or other standpoint theory, the focus is less on liberation than on understanding the present from multiple perspectives. Other critical theorists may object to the consensus orientation of interpretivist research. By searching for commonalities between people's stories, they may erase the uniqueness of each individual's story. For example, while interpretivists may arrive at a consensus definition of what the experience of "coming out" is like for people who identify as lesbian, gay, bisexual, transgender, or queer, it cannot represent the diversity of each person's unique "coming out" experience and what it meant to them. For example, see Rosario and colleagues' (2009)[10] critique the literature on lesbians "coming out" because previous studies did not addressing how appearing, behaving, or identifying as a butch or femme impacted the experience of "coming out" for lesbians.
Exercises
- From your literature search, identify an empirical article that uses qualitative methods to answer a research question similar to your working question or about your research topic.
- Review the assumptions of the interpretivist research paradigm.
- Discuss in a few sentences how the author's conclusions are based on some of these paradigmatic assumptions. How might a researcher operating from a different paradigm (like positivism or the critical paradigm) critique the conclusions of this study?

Critical paradigm: Researcher as "activist"
As we've discussed a bit in the preceding sections, the critical paradigm focuses on power, inequality, and social change. Although some rather diverse perspectives are included here, the critical paradigm, in general, includes ideas developed by early social theorists, such as Max Horkheimer (Calhoun et al., 2007),[11] and later works developed by feminist scholars, such as Nancy Fraser (1989).[12] Unlike the positivist paradigm, the critical paradigm assumes that social science can never be truly objective or value-free. Furthermore, this paradigm operates from the perspective that scientific investigation should be conducted with the express goal of social change. Researchers in the critical paradigm foreground axiology, positionality and values . In contrast with the detached, “objective” observations associated with the positivist researcher, critical approaches make explicit the intention for research to act as a transformative or emancipatory force within and beyond the study.
Researchers in the critical paradigm might start with the knowledge that systems are biased against certain groups, such as women or ethnic minorities, building upon previous theory and empirical data. Moreover, their research projects are designed not only to collect data, but to impact the participants as well as the systems being studied. The critical paradigm applies its study of power and inequality to change those power imbalances as part of the research process itself. If this sounds familiar to you, you may remember hearing similar ideas when discussing social conflict theory in your human behavior in the social environment (HBSE) class.[13] Because of this focus on social change, the critical paradigm is a natural home for social work research. However, we fall far short of adopting this approach widely in our profession's research efforts.
Is the critical paradigm right for your project?
Every social work research project impacts social justice in some way. What distinguishes critical research is how it integrates an analysis of power into the research process itself. Critical research is appropriate for projects that are activist in orientation. For example, critical research projects should have working questions that explicitly seek to raise the consciousness of an oppressed group or collaborate equitably with community members and clients to addresses issues of concern. Because of their transformative potential, critical research projects can be incredibly rewarding to complete. However, partnerships take a long time to develop and social change can evolve slowly on an issue, making critical research projects a more challenging fit for student research projects which must be completed under a tight deadline with few resources.
Positivists critique the critical paradigm on multiple fronts. First and foremost, the focus on oppression and values as part of the research process is seen as likely to bias the research process, most problematically, towards confirmation bias. If you start out with the assumption that oppression exists and must be dealt with, then you are likely to find that regardless of whether it is truly there or not. Similarly, positivists may fault critical researchers for focusing on how the world should be, rather than how it truly is. In this, they may focus too much on theoretical and abstract inquiry and less on traditional experimentation and empirical inquiry. Finally, the goal of social transformation is seen as inherently unscientific, as science is not a political practice.
Interpretivists often find common cause with critical researchers. Feminist studies, for example, may explore the perspectives of women while centering gender-based oppression as part of the research process. In interpretivist research, the focus is less on radical change as part of the research process and more on small, incremental changes based on the results and conclusions drawn from the research project. Additionally, some critical researchers' focus on individuality of experience is in stark contrast to the consensus-orientation of interpretivists. Interpretivists seek to understand people's true selves. Some critical theorists argue that people have multiple selves or no self at all.
Exercises
- From your literature search, identify an article relevant to your working question or broad research topic that uses a critical perspective. You should look for articles where the authors are clear that they are applying a critical approach to research like feminism, anti-racism, Marxism and critical theory, decolonization, anti-oppressive practice, or other social justice-focused theoretical perspectives. To target your search further, include keywords in your queries to research methods commonly used in the critical paradigm like participatory action research and community-based participatory research. If you have trouble identifying an article for this exercise, consult your professor for some help. These articles may be more challenging to find, but reviewing one is necessary to get a feel for what research in this paradigm is like.
- Review the assumptions of the critical research paradigm.
- Discuss in a few sentences how the author's conclusions are based on some of these paradigmatic assumptions. How might a researcher operating from different assumptions (like values-neutrality or researcher as neutral and unbiased) critique the conclusions of this study?

Pragmatism: Researcher as "strategist"
“Essentially, all models are wrong but some are useful.” (Box, 1976)[14]
Pragmatism is a research paradigm that suspends questions of philosophical ‘truth’ and focuses more on how different philosophies, theories, and methods can be used strategically to provide a multidimensional view of a topic. Researchers employing pragmatism will mix elements of positivist, interpretivist, and critical research depending on the purpose of a particular project and the practical constraints faced by the researcher and their research context. We favor this approach for student projects because it avoids getting bogged down in choosing the "right" paradigm and instead focuses on the assumptions that help you answer your question, given the limitations of your research context. Student research projects are completed quickly and moving in the direction of pragmatism can be a route to successfully completing a project. Your project is a representation of what you think is feasible, ethical, and important enough for you to study.
The crucial consideration for the pragmatist is whether the outcomes of research have any real-world application, rather than whether they are “true.” The methods, theories, and philosophies chosen by pragmatic researchers are guided by their working question. There are no distinctively pragmatic research methods since this approach is about making judicious use whichever methods fit best with the problem under investigation. Pragmatic approaches may be less likely to prioritize ontological, epistemological or axiological consistency when combining different research methods. Instead, the emphasis is on solving a pressing problem and adapting to the limitations and opportunities in the researchers' context.
Adopt a multi-paradigmatic perspective
Believe it or not, there is a long literature of acrimonious conflict between scientists from positivist, interpretivist, and critical camps (see Heineman-Pieper et al., 2002[15] for a longer discussion). Pragmatism is an old idea, but it is appealing precisely because it attempts to resolve the problem of multiple incompatible philosophical assumptions in social science. To a pragmatist, there is no "correct" paradigm. All paradigms rely on assumptions about the social world that are the subject of philosophical debate. Each paradigm is an incomplete understanding of the world, and it requires a scientific community using all of them to gain a comprehensive view of the social world. This multi-paradigmatic perspective is a unique gift of social work research, as our emphasis on empathy and social change makes us more critical of positivism, the dominant paradigm in social science.
We offered the metaphors of expert, empathizer, activist, and strategist for each paradigm. It's important not to take these labels too seriously. For example, some may view that scientists should be experts or that activists are biased and unscientific. Nevertheless, we hope that these metaphors give you a sense of what it feels like to conduct research within each paradigm.
One of the unique aspects of paradigmatic thinking is that often where you think you are most at home may actually be the opposite of where your research project is. For example, in my graduate and doctoral education, I thought I was a critical researcher. In fact, I thought I was a radical researcher focused on social change and transformation. Yet, often times when I sit down to conceptualize and start a research project, I find myself squarely in the positivist paradigm, thinking through neat cause-and-effect relationships that can be mathematically measured. There is nothing wrong with that! Your task for your research project is to find the paradigm that best matches your research question. Think through what you really want to study and how you think about the topic, then use assumptions of that paradigm to guide your inquiry.
Another important lesson is that no research project fits perfectly in one paradigm or another. Instead, there is a spectrum along which studies are, to varying degrees, interpretivist, positivist, and critical. For example, all social work research is a bit activist in that our research projects are designed to inform action for change on behalf of clients and systems. However, some projects will focus on the conclusions and implications of projects informing social change (i.e., positivist and interpretivist projects) while others will partner with community members and design research projects collaboratively in a way that leads to social change (i.e. critical projects). In section 7.5, we will describe a pragmatic approach to research design guided by your paradigmatic and theoretical framework.
Key Takeaways
- Social work research falls, to some degree, in each of the four paradigms: positivism, interpretivism, critical, and pragmatist.
- Adopting a pragmatic, multi-paradigmatic approach to research makes sense for student researchers, as it directs students to use the philosophical assumptions and methodological approaches that best match their research question and research context.
- Research in all paradigms is necessary to come to a comprehensive understanding of a topic, and social workers must be able to understand and apply knowledge from each research paradigm.
Exercises
- Describe which paradigm best fits your perspective on the world and which best fits with your project.
- Identify any similarities and differences in your personal assumptions and the assumption your research project relies upon. For example, are you a more critical and radical thinker but have chosen a more "expert" role for yourself in your research project?
15.2 Multiparadigmatic research: An example
Learning Objectives
Learners will be able to...
- Apply the assumptions of each paradigm to your project
- Summarize what aspects of your project stem from positivist, interpretivist, or critical assumptions
In the previous sections, we reviewed the major paradigms and theories in social work research. In this section, we will provide an example of how to apply theory and paradigm in research. This process is depicted in Figure 7.2 below with some quick summary questions for each stage. Some questions in the figure below have example answers like designs (i.e., experimental, survey) and data analysis approaches (i.e., discourse analysis). These examples are arbitrary. There are a lot of options that are not listed. So, don't feel like you have to memorize them or use them in your study.
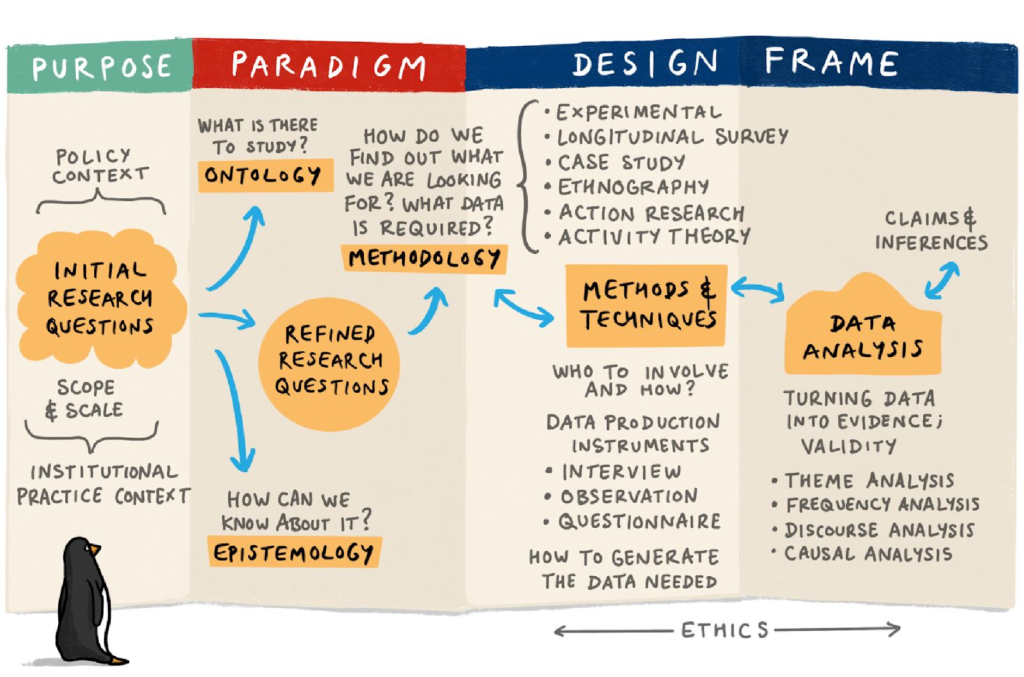
This diagram (taken from an archived Open University (UK) course entitled E89-Educational Inquiry) shows one way to visualize the research design process. While research is far from linear, in general, this is how research projects progress sequentially. Researchers begin with a working question, and through engaging with the literature, develop and refine those questions into research questions (a process we will finalize in Chapter 9). But in order to get to the part where you gather your sample, measure your participants, and analyze your data, you need to start with paradigm. Based on your work in section 7.3, you should have a sense of which paradigm or paradigms are best suited to answering your question. The approach taken will often reflect the nature of the research question; the kind of data it is possible to collect; and work previously done in the area under consideration. When evaluating paradigm and theory, it is important to look at what other authors have done previously and the framework used by studies that are similar to the one you are thinking of conducting.
Once you situate your project in a research paradigm, it becomes possible to start making concrete choices about methods. Depending on the project, this will involve choices about things like:
- What is my final research question?
- What are the key variables and concepts under investigation, and how will I measure them?
- How do I find a representative sample of people who experience the topic I'm studying?
- What design is most appropriate for my research question?
- How will I collect and analyze data?
- How do I determine whether my results describe real patterns in the world or are the result of bias or error?
The data collection phase can begin once these decisions are made. It can be very tempting to start collecting data as soon as possible in the research process as this gives a sense of progress. However, it is usually worth getting things exactly right before collecting data as an error found in your approach further down the line can be harder to correct or recalibrate around.
Designing a study using paradigm and theory: An example
Paradigm and theory have the potential to turn some people off since there is a lot of abstract terminology and thinking about real-world social work practice contexts. In this section, I'll use an example from my own research, and I hope it will illustrate a few things. First, it will show that paradigms are really just philosophical statements about things you already understand and think about normally. It will also show that no project neatly sits in one paradigm and that a social work researcher should use whichever paradigm or combination of paradigms suit their question the best. Finally, I hope it is one example of how to be a pragmatist and strategically use the strengths of different theories and paradigms to answering a research question. We will pick up the discussion of mixed methods in the next chapter.
Thinking as an expert: Positivism
In my undergraduate research methods class, I used an open textbook much like this one and wanted to study whether it improved student learning. You can read a copy of the article we wrote on based on our study. We'll learn more about the specifics of experiments and evaluation research in Chapter 13, but you know enough to understand what evaluating an intervention might look like. My first thought was to conduct an experiment, which placed me firmly within the positivist or "expert" paradigm.
Experiments focus on isolating the relationship between cause and effect. For my study, this meant studying an open textbook (the cause, or intervention) and final grades (the effect, or outcome). Notice that my position as "expert" lets me assume many things in this process. First, it assumes that I can distill the many dimensions of student learning into one number—the final grade. Second, as the "expert," I've determined what the intervention is: indeed, I created the book I was studying, and applied a theory from experts in the field that explains how and why it should impact student learning.
Theory is part of applying all paradigms, but I'll discuss its impact within positivism first. Theories grounded in positivism help explain why one thing causes another. More specifically, these theories isolate a causal relationship between two (or more) concepts while holding constant the effects of other variables that might confound the relationship between the key variables. That is why experimental design is so common in positivist research. The researcher isolates the environment from anything that might impact or bias the cause and effect relationship they want to investigate.
But in order for one thing to lead to change in something else, there must be some logical, rational reason why it would do so. In open education, there are a few hypotheses (though no full-fledged theories) on why students might perform better using open textbooks. The most common is the access hypothesis, which states that students who cannot afford expensive textbooks or wouldn't buy them anyway can access open textbooks because they are free, which will improve their grades. It's important to note that I held this theory prior to starting the experiment, as in positivist research you spell out your hypotheses in advance and design an experiment to support or refute that hypothesis.
Notice that the hypothesis here applies not only to the people in my experiment, but to any student in higher education. Positivism seeks generalizable truth, or what is true for everyone. The results of my study should provide evidence that anyone who uses an open textbook would achieve similar outcomes. Of course, there were a number of limitations as it was difficult to tightly control the study. I could not randomly assign students or prevent them from sharing resources with one another, for example. So, while this study had many positivist elements, it was far from a perfect positivist study because I was forced to adapt to the pragmatic limitations of my research context (e.g., I cannot randomly assign students to classes) that made it difficult to establish an objective, generalizable truth.
Thinking like an empathizer: Interpretivism
One of the things that did not sit right with me about the study was the reliance on final grades to signify everything that was going on with students. I added another quantitative measure that measured research knowledge, but this was still too simplistic. I wanted to understand how students used the book and what they thought about it. I could create survey questions that ask about these things, but to get at the subjective truths here, I thought it best to use focus groups in which students would talk to one another with a researcher moderating the discussion and guiding it using predetermined questions. You will learn more about focus groups in Chapter 18.
Researchers spoke with small groups of students during the last class of the semester. They prompted people to talk about aspects of the textbook they liked and didn't like, compare it to textbooks from other classes, describe how they used it, and so forth. It was this focus on understanding and subjective experience that brought us into the interpretivist paradigm. Alongside other researchers, I created the focus group questions but encouraged researchers who moderated the focus groups to allow the conversation to flow organically.
We originally started out with the assumption, for which there is support in the literature, that students would be angry with the high-cost textbook that we used prior to the free one, and this cost shock might play a role in students' negative attitudes about research. But unlike the hypotheses in positivism, these are merely a place to start and are open to revision throughout the research process. This is because the researchers are not the experts, the participants are! Just like your clients are the experts on their lives, so were the students in my study. Our job as researchers was to create a group in which they would reveal their informed thoughts about the issue, coming to consensus around a few key themes.

When we initially analyzed the focus groups, we uncovered themes that seemed to fit the data. But the overall picture was murky. How were themes related to each other? And how could we distill these themes and relationships into something meaningful? We went back to the data again. We could do this because there isn't one truth, as in positivism, but multiple truths and multiple ways of interpreting the data. When we looked again, we focused on some of the effects of having a textbook customized to the course. It was that customization process that helped make the language more approachable, engaging, and relevant to social work practice.
Ultimately, our data revealed differences in how students perceived a free textbook versus a free textbook that is customized to the class. When we went to interpret this finding, the remix hypothesis of open textbook was helpful in understanding that relationship. It states that the more faculty incorporate editing and creating into the course, the better student learning will be. Our study helped flesh out that theory by discussing the customization process and how students made sense of a customized resource.
In this way, theoretical analysis operates differently in interpretivist research. While positivist research tests existing theories, interpretivist research creates theories based on the stories of research participants. However, it is difficult to say if this theory was totally emergent in the dataset or if my prior knowledge of the remix hypothesis influenced my thinking about the data. Interpretivist researchers are encouraged to put a box around their prior experiences and beliefs, acknowledging them, but trying to approach the data with fresh eyes. Interpretivists know that this is never perfectly possible, though, as we are always influenced by our previous experiences when interpreting data and conducting scientific research projects.
Thinking like an activist: Critical
Although adding focus groups helped ease my concern about reducing student learning down to just final grades by providing a more rich set of conversations to analyze. However, my role as researcher and "expert" was still an important part of the analysis. As someone who has been out of school for a while, and indeed has taught this course for years, I have lost touch with what it is like to be a student taking research methods for the first time. How could I accurately interpret or understand what students were saying? Perhaps I would overlook things that reflected poorly on my teaching or my book. I brought other faculty researchers on board to help me analyze the data, but this still didn't feel like enough.
By luck, an undergraduate student approached me about wanting to work together on a research project. I asked her if she would like to collaborate on evaluating the textbook with me. Over the next year, she assisted me with conceptualizing the project, creating research questions, as well as conducting and analyzing the focus groups. Not only would she provide an "insider" perspective on coding the data, steeped in her lived experience as a student, but she would serve as a check on my power through the process.
Including people from the group you are measuring as part of your research team is a common component of critical research. Ultimately, critical theorists would find my study to be inadequate in many ways. I still developed the research question, created the intervention, and wrote up the results for publication, which privileges my voice and role as "expert." Instead, critical theorists would emphasize the role of students (community members) in identifying research questions, choosing the best intervention to used, and so forth. But collaborating with students as part of a research team did address some of the power imbalances in the research process.
Critical research projects also aim to have an impact on the people and systems involved in research. No students or researchers had profound personal realizations as a result of my study, nor did it lessen the impact of oppressive structures in society. I can claim some small victory that my department switched to using my textbook after the study was complete (changing a system), though this was likely the result of factors other than the study (my advocacy for open textbooks).
Social work research is almost always designed to create change for people or systems. To that end, every social work project is at least somewhat critical. However, the additional steps of conducting research with people rather than on people reveal a depth to the critical paradigm. By bringing students on board the research team, study had student perspectives represented in conceptualization, data collection, and analysis. That said, there was much to critique about this study from a critical perspective. I retained a lot of the power in the research process, and students did not have the ability to determine the research question or purpose of the project. For example, students might likely have said that textbook costs and the quality of their research methods textbook were less important than student debt, racism, or other potential issues experienced by students in my class. Instead of a ground-up research process based in community engagement, my research included some important participation by students on project created and led by faculty.
Conceptualization is an iterative process
I hope this conversation was useful in applying paradigms to a research project. While my example discusses education research, the same would apply for social work research about social welfare programs, clinical interventions, or other topics. Paradigm and theory are covered at the beginning of the conceptualization of your project because these assumptions will structure the rest of your project. Each of the research steps that occur after this chapter (e.g., forming a question, choosing a design) rely upon philosophical and theoretical assumptions. As you continue conceptualizing your project over the next few weeks, you may find yourself shifting between paradigms. That is normal, as conceptualization is not a linear process. As you move through the next steps of conceptualizing and designing a project, you'll find philosophies and theories that best match how you want to study your topic.
Viewing theoretical and empirical arguments through this lens is one of the true gifts of the social work approach to research. The multi-paradigmatic perspective is a hallmark of social work research and one that helps us contribute something unique on research teams and in practice.
Key Takeaways
- Multi-paradigmatic research is a distinguishing hallmark of social work research. Understanding the limitations and strengths of each paradigm will help you justify your research approach and strategically choose elements from one or more paradigms to answer your question.
- Paradigmatic assumptions help you understand the "blind spots" in your research project and how to adjust and address these areas. Keep in mind, it is not necessary to address all of your blind spots, as all projects have limitations.
Exercises
- Sketch out which paradigm applies best to your project. Second, building on your answer to the exercise in section 7.3, identify how the theory you chose and the paradigm in which you find yourself are consistent or are in conflict with one another. For example, if you are using systems theory in a positivist framework, you might talk about how they both rely on a deterministic approach to human behavior with a focus on the status-quo and social order.
15.3 Idiographic causal relationships
Learning Objectives
Learners will be able to...
- Define and provide an example of an idiographic causal explanation
- Differentiate between idiographic and nomothetic causal relationships
- Link idiographic and nomothetic causal relationships with the process of theory building and theory testing
- Describe how idiographic and nomothetic causal explanations can be complementary
As we transition away from positivism, it is important to highlight the assumptions it makes about the scientific process--the hypothetico-deductive method, sometimes referred to as the research circle.
The hypothetico-deductive method
The primary way that researchers in the positivist paradigm use theories is sometimes called the hypothetico-deductive method (although this term is much more likely to be used by philosophers of science than by scientists themselves). Researchers choose an existing theory. Then, they make a prediction about some new phenomenon that should be observed if the theory is correct. Again, this prediction is called a hypothesis. The researchers then conduct an empirical study to test the hypothesis. Finally, they reevaluate the theory in light of the new results and revise it if necessary.
This process is usually conceptualized as a cycle because the researchers can then derive a new hypothesis from the revised theory, conduct a new empirical study to test the hypothesis, and so on. As Figure 8.8 shows, this approach meshes nicely with the process of conducting a research project—creating a more detailed model of “theoretically motivated” or “theory-driven” research. Together, they form a model of theoretically motivated research.
Keep in mind the hypothetico-deductive method is only one way of using social theory to inform social science research. It starts with describing one or more existing theories, deriving a hypothesis from one of those theories, testing your hypothesis in a new study, and finally reevaluating the theory based on the results data analyses. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with a hypothesis derived from a different theory.
But what if your research question is more interpretive? What if it is less about theory-testing and more about theory-building? This is what our next chapter covers: the process of inductively deriving theory from people's stories and experiences. This process looks different than that depicted in Figure 8.8. It still starts with your research question and answering that question by conducting a research study. But instead of testing a hypothesis you created based on a theory, you will create a theory of your own that explain the data you collected. This format works well for qualitative research questions and for research questions that existing theories do not address.
Inductive reasoning is most commonly found in studies using qualitative methods, such as focus groups and interviews. Because inductive reasoning involves the creation of a new theory, researchers need very nuanced data on how the key concepts in their working question operate in the real world. Qualitative data is often drawn from lengthy interactions and observations with the individuals and phenomena under examination. For this reason, inductive reasoning is most often associated with qualitative methods, though it is used in both quantitative and qualitative research.

Whose truth does science establish?
Social work is concerned with the "isms" of oppression (ableism, ageism, cissexism, classism, heterosexism, racism, sexism, etc.), and so our approach to science must reconcile its history as both a tool of oppression and its exclusion of oppressed groups. Science grew out of the Enlightenment, a philosophical movement which applied reason and empirical analysis to understanding the world. While the Enlightenment brought forth tremendous achievements, the critiques of Marxian, feminist, and other critical theorists complicated the Enlightenment understanding of science. For this section, I will focus on feminist critiques of science, building upon an entry in the Stanford Encyclopedia of Philosophy (Crasnow, 2020).[16]
In its original formulation, science was an individualistic endeavor. As we learned in Chapter 1, a basic statement of the scientific method is that a researcher studies existing theories on a topic, formulates a hypothesis about what might be true, and either confirms or disconfirms their hypothesis through experiment and rigorous observation. Over time, our theories become more accurate in their predictions and more comprehensive in their conclusions. Scientists put aside their preconceptions, look at the data, and build their theories based on objective rationality.
Yet, this cannot be perfectly true. Scientists are human, after all. As a profession historically dominated by white men, scientists have dismissed women and other minorities as being psychologically unfit for the scientific profession. While attitudes have improved, science, technology, engineering, mathematics (STEM) and related fields remain dominated by white men (Grogan, 2019).[17] Biases can persist in social work theory and research when social scientists do not have similar experiences to the populations they study.
Gender bias can influence the research questions scientists choose to answer. Feminist critiques of medical science drew attention to women's health issues, spurring research and changing standards of care. The focus on domestic violence in the empirical literature can also be seen as a result of feminist critique. Thus, critical theory helps us critique what is on the agenda for science. If science is to answer important questions, it must speak to the concerns of all people. Through the democratization in access to scientific knowledge and the means to produce it, science becomes a sister process of social development and social justice.
The goal of a diverse and participatory scientific community lies in contrast to much of what we understand to be "proper" scientific knowledge. Many of the older, classic social science theories were developed based on research which observed males or from university students in the United States or other Western nations. How these observations were made, what questions were asked, and how the data were interpreted were shaped by the same oppressive forces that existed in broader society, a process that continues into the present. In psychology, the concept of hysteria or hysterical women was believed to be caused by a wandering womb (Tasca et al., 2012).[18] Even today, there are gender biases in diagnoses of histrionic personality disorder and racial biases in psychotic disorders (Klonsky et al., 2002)[19] because the theories underlying them were created in a sexist and racist culture. In these ways, science can reinforce the truth of the white Western male perspective.
Finally, it is important to note that social science research is often conducted on populations rather than with populations. Historically, this has often meant Western men traveling to other countries and seeking to understand other cultures through a Western lens. Lacking cultural humility and failing to engage stakeholders, ethnocentric research of this sort has led to the view of non-Western cultures as inferior. Moreover, the use of these populations as research subjects rather than co-equal participants in the research process privileges the researcher's knowledge over that from other groups or cultures. Researchers working with indigenous cultures, in particular, had a destructive habit of conducting research for a short time and then leaving, without regard for the impact their study had on the population. These critiques of Western science aim to decolonize social science and dismantle the racist ideas the oppress indigenous and non-Western peoples through research (Smith, 2013).[20]
The central concept in feminist, anti-racist, and decolonization critiques (among other critical frames) is epistemic injustice. Epistemic injustice happens when someone is treated unfairly in their capacity to know something or describe their experience of the world. As described by Fricker (2011),[21] the injustice emerges from the dismissal of knowledge from oppressed groups, discrimination against oppressed groups in scientific communities, and the resulting gap between what scientists can make sense of from their experience and the experiences of people with less power who have lived experience of the topic. We recommend this video from Edinburgh Law School which applies epistemic injustice to studying public health emergencies, disabilities, and refugee services.
Positivism relies on nomothetic causality, or the idea that "one event, behavior, or belief will result in the occurrence of another, subsequent event, behavior, or belief." Then, we described one kind of causality: a simple cause-and-effect relationship supported by existing theory and research on the topic, also known as a nomothetic causal relationship. But what if there is not a lot of literature on your topic? What if your question is more exploratory than explanatory? Then, you need a different kind of causal explanation, one that accounts for the complexity of human interactions.
How can we build causal relationships if we are just describing or exploring a topic? Recall the definitions of exploratory research, descriptive research, and explanatory research from Chapter 2. Wouldn’t we need to do explanatory research to build any kind of causal explanation? Explanatory research attempts to establish nomothetic causal relationships: an independent variable is demonstrated to cause change in a dependent variable. Exploratory and descriptive qualitative research contains some causal relationships, but they are actually descriptions of the causal relationships established by the study participants.
What do idiographic causal explanations look like?
An idiographic causal relationship tries to identify the many, interrelated causes that account for the phenomenon the researcher is investigating. So, if idiographic causal explanations do not look like Figure 8.5, 8.6, or 8.7 what do they look like? Instead of saying “x causes y,” your participants will describe their experiences with “x,” which they will tell you was caused and influenced by a variety of other factors, as interpreted through their unique perspective, time, and environment. As we stated before, idiographic causal explanations are messy. Your job as a social science researcher is to accurately describe the patterns in what your participants tell you.
Let's think about this using an example. If I asked you why you decided to become a social worker, what might you say? For me, I would say that I wanted to be a mental health clinician since I was in high school. I was interested in how people thought, and I was privileged enough to have psychology courses at my local high school. I thought I wanted to be a psychologist, but at my second internship in my undergraduate program, my supervisors advised me to become a social worker because the license provided greater authority for independent practice and flexibility for career change. Once I found out social workers were like psychologists who also raised trouble about social justice, I was hooked.
That’s not a simple explanation at all! But it's definitely a causal explanation. It is my individual, subjective truth of a complex process. If we were to ask multiple social workers the same question, we might find out that many social workers begin their careers based on factors like personal experience with a disability or social injustice, positive experiences with social workers, or a desire to help others. No one factor is the “most important factor,” like with nomothetic causal relationships. Instead, a complex web of factors, contingent on context, emerge when you interpret what people tell you about their lives.
Understanding "why?"
In creating an idiographic explanation, you are still asking "why?" But the answer is going to be more complex. Those complexities are described in Table 8.1 as well as this short video comparing nomothetic and idiographic relationships.
| Nomothetic causal relationships | Idiographic causal relationships | |
|---|---|---|
| Paradigm | Positivist | Interpretivist |
| Purpose of research | Prediction & generalization | Understanding & particularity |
| Reasoning | Deductive | Inductive |
| Purpose of research | Explanatory | Exploratory or descriptive |
| Research methods | Quantitative | Qualitative |
| Causality | Simple: cause and effect | Complex: context-dependent, sometimes circular or contradictory |
| Role of theory | Theory testing | Theory building |
Remember our question from the last section, “Are you trying to generalize or nah?” If you answered nah (or no, like a normal person), you are trying to establish an idiographic causal explanation. The purpose of that explanation isn't to predict the future or generalize to larger populations, but to describe the here-and-now as it is experienced by individuals within small groups and communities. Idiographic explanations are focused less on what is generally experienced by all people but more on the particularities of what specific individuals in a unique time and place experience.
Researchers seeking idiographic causal relationships are not trying to generalize or predict, so they have no need to reduce phenomena to mathematics. In fact, only examining things that can be counted can rob a causal relationship of its meaning and context. Instead, the goal of idiographic causal relationships is understanding, rather than prediction. Idiographic causal relationships are formed by interpreting people’s stories and experiences. Usually, these are expressed through words. Not all qualitative studies use word data, as some can use interpretations of visual or performance art. However, the vast majority of qualitative studies do use word data, like the transcripts from interviews and focus groups or documents like journal entries or meeting notes. Your participants are the experts on their lives—much like in social work practice—and as in practice, people's experiences are embedded in their cultural, historical, and environmental context.
Idiographic causal explanations are powerful because they can describe the complicated and interconnected nature of human life. Nomothetic causal explanations, by comparison, are simplistic. Think about if someone asked you why you wanted to be a social worker. Your story might include a couple of vignettes from your education and early employment. It might include personal experience with the social welfare system or family traditions. Maybe you decided on a whim to enroll in a social work course during your graduate program. The impact of each of these events on your career is unique to you.
Idiographic causal explanations are concerned with individual stories, their idiosyncrasies, and the patterns that emerge when you collect and analyze multiple people's stories. This is the inductive reasoning we discussed at the beginning of this chapter. Often, idiographic causal explanations begin by collecting a lot of qualitative data, whether though interviews, focus groups, or looking at available documents or cultural artifacts. Next, the researcher looks for patterns in the data and arrives at a tentative theory for how the key ideas in people's stories are causally related.
Unlike nomothetic causal relationships, there are no formal criteria (e.g., covariation) for establishing causality in idiographic causal relationships. In fact, some criteria like temporality and nonspuriousness may be violated. For example, if an adolescent client says, “It’s hard for me to tell whether my depression began before my drinking, but both got worse when I was expelled from my first high school,” they are recognizing that it may not so simple that one thing causes another. Sometimes, there is a reciprocal relationship where one variable (depression) impacts another (alcohol abuse), which then feeds back into the first variable (depression) and into other variables as well (school). Other criteria, such as covariation and plausibility, still make sense, as the relationships you highlight as part of your idiographic causal explanation should still be plausible and its elements should vary together.
Theory building and theory testing
As we learned in the previous section, nomothetic causal explanations are created by researchers applying deductive reasoning to their topic and creating hypotheses using social science theories. Much of what we think of as social science is based on this hypothetico-deductive method, but this leaves out the other half of the equation. Where do theories come from? Are they all just revisions of one another? How do any new ideas enter social science?
Through inductive reasoning and idiographic causal explanations!
Let's consider a social work example. If you plan to study domestic and sexual violence, you will likely encounter the Power and Control Wheel, also known as the Duluth Model (Figure 8.9). The wheel is a model designed to depict the process of domestic violence. The wheel was developed based on qualitative focus groups conducted by sexual and domestic violence advocates in Duluth, MN. This video explains more about the Duluth Model of domestic abuse.
The Power and Control Wheel is an example of what an idiographic causal relationship looks like. By contrast, look back at the previous section's Figure 8.5, 8.6, and 8.7 on nomothetic causal relationships between independent and dependent variables. See how much more complex idiographic causal explanations are?! They are complex, but not difficult to understand. At the center of domestic abuse is power and control, and while not every abuser would say that is what they were doing, that is the understanding of the survivors who informed this theoretical model. Their power and control is maintained through a variety of abusive tactics from social isolation to use of privilege to avoid consequences.
What about the role of hypotheses in idiographic causal explanations? In nomothetic causal explanations, researchers create hypotheses using existing theory and then test them for accuracy. Hypotheses in idiographic causality are much more tentative, and are probably best considered as "hunches" about what they think might be true. Importantly, they might indicate the researcher's prior knowledge and biases before the project begins, but the goal of idiographic research is to let your participants guide you rather than existing social work knowledge. Continuing with our Duluth Model example, advocates likely had some tentative hypotheses about what was important in a relationship with domestic violence. After all, they worked with this population for years prior to the creation of the model. However, it was the stories of the participants in these focus groups that led the Power and Control Wheel explanation for domestic abuse.
As qualitative inquiry unfolds, hypotheses and hunches are likely to emerge and shift as researchers learn from what their participants share. Because the participants are the experts in idiographic causal relationships, a researcher should be open to emerging topics and shift their research questions and hypotheses accordingly. This is in contrast to hypotheses in quantitative research, which remain constant throughout the study and are shown to be true or false.
Over time, as more qualitative studies are done and patterns emerge across different studies and locations, more sophisticated theories emerge that explain phenomena across multiple contexts. Once a theory is developed from qualitative studies, a quantitative researcher can seek to test that theory. For example, a quantitative researcher may hypothesize that men who hold traditional gender roles are more likely to engage in domestic violence. That would make sense based on the Power and Control Wheel model, as the category of “using male privilege” speaks to this relationship. In this way, qualitatively-derived theory can inspire a hypothesis for a quantitative research project, as we will explore in the next section.
Complementary approaches
If idiographic and nomothetic still seem like obscure philosophy terms, let’s consider another example. Imagine you are working for a community-based non-profit agency serving people with disabilities. You are putting together a report to lobby the state government for additional funding for community support programs. As part of that lobbying, you are likely to rely on both nomothetic and idiographic causal relationships.
If you looked at nomothetic causal relationships, you might learn how previous studies have shown that, in general, community-based programs like yours are linked with better health and employment outcomes for people with disabilities. Nomothetic causal explanations seek to establish that community-based programs are better for everyone with disabilities, including people in your community.
If you looked at idiographic causal explanations, you would use stories and experiences of people in community-based programs. These individual stories are full of detail about the lived experience of being in a community-based program. You might use one story from a client in your lobbying campaign, so policymakers can understand the lived experience of what it’s like to be a person with a disability in this program. For example, a client who said “I feel at home when I’m at this agency because they treat me like a family member,” or “this is the agency that helped me get my first paycheck,” can communicate richer, more complex causal relationships.
Neither kind of causal explanation is better than the other. A decision to seek idiographic causal explanations means that you will attempt to explain or describe your phenomenon exhaustively, attending to cultural context and subjective interpretations. A decision to seek nomothetic causal explanations, on the other hand, means that you will try to explain what is true for everyone and predict what will be true in the future. In short, idiographic explanations have greater depth, and nomothetic explanations have greater breadth.
Most importantly, social workers understand the value of both approaches to understanding the social world. A social worker helping a client with substance abuse issues seeks idiographic explanations when they ask about that client’s life story, investigate their unique physical environment, or probe how their family relationships. At the same time, a social worker also uses nomothetic explanations to guide their interventions. Nomothetic explanations may help guide them to minimize risk factors and maximize protective factors or use an evidence-based therapy, relying on knowledge about what in general helps people with substance abuse issues.
So, which approach speaks to you? Are you interested in learning about (a) a few people's experiences in a great deal of depth, or (b) a lot of people's experiences more superficially, while also hoping your findings can be generalized to a greater number of people? The answer to this question will drive your research question and project. These approaches provide different types of information and both types are valuable.
Key Takeaways
- Idiographic causal explanations focus on subjectivity, context, and meaning.
- Idiographic causal explanations are best suited to exploratory research questions and qualitative methods.
- Idiographic causal explanations are used to create new theories in social science.
Exercises
- Explore the literature on the theory you identified in section 8.1.
- Read about the origins of your theory. Who developed it and from what data?
- See if you can find a figure like Figure 8.9 in an article or book chapter that depicts the key concepts in your theory and how those concepts are related to one another causally. Write out a short statement on the causal relationships contained in the figure.
15.4 Qualitative research questions
Learning Objectives
Learners will be able to...
- List the key terms associated with qualitative research questions
- Distinguish between qualitative and quantitative research questions
Qualitative research questions differ from quantitative research questions. Because qualitative research questions seek to explore or describe phenomena, not provide a neat nomothetic explanation, they are often more general and openly worded. They may include only one concept, though many include more than one. Instead of asking how one variable causes changes in another, we are instead trying to understand the experiences, understandings, and meanings that people have about the concepts in our research question. These keywords often make an appearance in qualitative research questions.
Let’s work through an example from our last section. In Table 9.1, a student asked, “What is the relationship between sexual orientation or gender identity and homelessness for late adolescents in foster care?” In this question, it is pretty clear that the student believes that adolescents in foster care who identify as LGBTQ+ may be at greater risk for homelessness. This is a nomothetic causal relationship—LGBTQ+ status causes changes in homelessness.
However, what if the student were less interested in predicting homelessness based on LGBTQ+ status and more interested in understanding the stories of foster care youth who identify as LGBTQ+ and may be at risk for homelessness? In that case, the researcher would be building an idiographic causal explanation. The youths whom the researcher interviews may share stories of how their foster families, caseworkers, and others treated them. They may share stories about how they thought of their own sexuality or gender identity and how it changed over time. They may have different ideas about what it means to transition out of foster care.

Because qualitative questions usually center on idiographic causal relationships, they look different than quantitative questions. Table 9.3 below takes the final research questions from Table 9.1 and adapts them for qualitative research. The guidelines for research questions previously described in this chapter still apply, but there are some new elements to qualitative research questions that are not present in quantitative questions.
- Qualitative research questions often ask about lived experience, personal experience, understanding, meaning, and stories.
- Qualitative research questions may be more general and less specific.
- Qualitative research questions may also contain only one variable, rather than asking about relationships between multiple variables.
| Quantitative Research Questions | Qualitative Research Questions |
| How does witnessing domestic violence impact a child’s romantic relationships in adulthood? | How do people who witness domestic violence understand its effects on their current relationships? |
| What is the relationship between sexual orientation or gender identity and homelessness for late adolescents in foster care? | What is the experience of identifying as LGBTQ+ in the foster care system? |
| How does income inequality affect ambivalence in high-density urban areas? | What does racial ambivalence mean to residents of an urban neighborhood with high income inequality? |
| How does race impact rates of mental health diagnosis for children in foster care? | How do African-Americans experience seeking help for mental health concerns? |
Qualitative research questions have one final feature that distinguishes them from quantitative research questions: they can change over the course of a study. Qualitative research is a reflexive process, one in which the researcher adapts their approach based on what participants say and do. The researcher must constantly evaluate whether their question is important and relevant to the participants. As the researcher gains information from participants, it is normal for the focus of the inquiry to shift.
For example, a qualitative researcher may want to study how a new truancy rule impacts youth at risk of expulsion. However, after interviewing some of the youth in their community, a researcher might find that the rule is actually irrelevant to their behavior and thoughts. Instead, their participants will direct the discussion to their frustration with the school administrators or the lack of job opportunities in the area. This is a natural part of qualitative research, and it is normal for research questions and hypothesis to evolve based on information gleaned from participants.
However, this reflexivity and openness unacceptable in quantitative research for good reasons. Researchers using quantitative methods are testing a hypothesis, and if they could revise that hypothesis to match what they found, they could never be wrong! Indeed, an important component of open science and reproducability is the preregistration of a researcher's hypotheses and data analysis plan in a central repository that can be verified and replicated by reviewers and other researchers. This interactive graphic from 538 shows how an unscrupulous research could come up with a hypothesis and theoretical explanation after collecting data by hunting for a combination of factors that results in a statistically significant relationship. This is an excellent example of how the positivist assumptions behind quantitative research and intepretivist assumptions behind qualitative research result in different approaches to social science.
Key Takeaways
- Qualitative research questions often contain words or phrases like "lived experience," "personal experience," "understanding," "meaning," and "stories."
- Qualitative research questions can change and evolve over the course of the study.
Exercises
- Using the guidance in this chapter, write a qualitative research question. You may want to use some of the keywords mentioned above.
Chapter Outline
- Introduction to qualitative rigor (13 minute read)
- Ethical responsibility and cultural respectfulness (4 minute read)
- Critical considerations (6 minute read)
- Data capture: Striving for accuracy in our raw data (6 minute read)
- Data management: Keeping track of our data and our analysis (8 minute read)
- Tools to account for our influence (22 minute read)
Content warning: Examples in this chapter contain references to fake news, mental health treatment, peer-support, misrepresentation, equity and (dis)honesty in research.
We hear a lot about fake news these days. Fake news has to do with the quality of journalism that we are consuming. It begs questions like: does it contain misinformation, is it skewed or biased in its portrayal of stories, does it leave out certain facts while inflating others. If we take this news at face value, our opinions and actions may be intentionally manipulated by poor quality information. So, how do we avoid or challenge this? The oversimplified answer is, we find ways to check for quality. While this isn't a chapter dedicated to fake news, it does offer an important comparison for the focus of this chapter, rigor in qualitative research. Rigor is concerned with the quality of research that we are designing and consuming. While I devote a considerable amount of time in my clinical class talking about the importance of adopting a non-judgmental stance in practice, that is not the case here; I want you to be judgmental, critical thinkers about research! As a social worker who will hopefully be producing research (we need you!) and definitely consuming research, you need to be able to differentiate good science from rubbish science. Rigor will help you to do this.

This chapter will introduce you to the concept of rigor and specifically, what it looks like in qualitative research. We will begin by considering how rigor relates to issues of ethics and how thoughtfully involving community partners in our research can add additional dimensions in planning for rigor. Next, we will look at rigor in how we capture and manage qualitative data, essentially helping to ensure that we have quality raw data to work with for our study. Finally, we will devote time to discussing how researchers, as human instruments, need to maintain accountability throughout the research process. Finally, we will examine tools that encourage this accountability and how they can be integrated into your research design. Our hope is that by the end of this chapter, you will begin to be able to identify some of the hallmarks of quality in qualitative research, and if you are designing a qualitative research proposal, that you consider how to build these into your design.
20.1 Introduction to qualitative rigor
Learning Objectives
Learners will be able to...
- Identify the role of rigor in qualitative research and important concepts related to qualitative rigor
- Discuss why rigor is an important consideration when conducting, critiquing and consuming qualitative research
- Differentiate between quality in quantitative and qualitative research studies
In Chapter 11 we talked about quality in quantitative studies, but we built our discussion around concepts like reliability and validity. With qualitative studies, we generally think about quality in terms of the concept of rigor. The difference between quality in quantitative research and qualitative research extends beyond the type of data (numbers vs. words/sounds/images). If you sneak a peek all the way back to Chapter 7, we discussed the idea of different paradigms or fundamental frameworks for how we can think about the world. These frameworks value different kinds of knowledge, arrive at knowledge in different ways, and evaluate the quality of knowledge with different criteria. These differences are essential in differentiating qualitative and quantitative work.
Quantitative research generally falls under a positivist paradigm, seeking to uncover knowledge that holds true across larger groups of people. To accomplish this, we need to have tools like reliability and validity to help produce internally consistent and externally generalizable findings (i.e. was our study design dependable and do our findings hold true across our population).
In contrast, qualitative research is generally considered to fall into an alternative paradigm (other than positivist), such as the interpretive paradigm which is focused on the subjective experiences of individuals and their unique perspectives. To accomplish this, we are often asking participants to expand on their ideas and interpretations. A positivist tradition requires the information collected to be very focused and discretely defined (i.e. closed questions with prescribed categories). With qualitative studies, we need to look across unique experiences reflected in the data and determine how these experiences develop a richer understanding of the phenomenon we are studying, often across numerous perspectives.
Rigor is a concept that reflects the quality of the process used in capturing, managing, and analyzing our data as we develop this rich understanding. Rigor helps to establish standards through which qualitative research is critiqued and judged, both by the scientific community and by the practitioner community.

For the scientific community, people who review qualitative research studies submitted for publication in scientific journals or for presentations at conferences will specifically look for indications of rigor, such as the tools we will discuss in this chapter. This confirms for them that the researcher(s) put safeguards in place to ensure that the research took place systematically and that consumers can be relatively confident that the findings are not fabricated and can be directly connected back to the primary sources of data that was gathered or the secondary data that was analyzed.
As a note here, as we are critiquing the research of others or developing our own studies, we also need to recognize the limitations of rigor. No research design is flawless and every researcher faces limitations and constraints. We aren't looking for a researcher to adopt every tool we discuss below in their design. In fact, one of my mentors, speaks explicitly about "misplaced rigor", that is, using techniques to support rigor that don't really fit what you are trying to accomplish with your research design. Suffice it to say that we can go overboard in the area of rigor and it might not serve our study's best interest. As a consumer or evaluator of research, you want to look for steps being taken to reflect quality and transparency throughout the research process, but they should fit within the overall framework of the study and what it is trying to accomplish.
From the perspective of a practitioner, we also need to be acutely concerned with the quality of research. Social work has made a commitment, outlined in our Code of Ethics (NASW,2017), to competent practice in service to our clients based on "empirically based knowledge" (subsection 4.01). When I think about my own care providers, I want them to be using "good" research—research that we can be confident was conducted in a credible way and whose findings are honestly and clearly represented. Don't our clients deserve the same from us?

As providers, we will be looking to qualitative research studies to provide us with information that helps us better understand our clients, their experiences, and the problems they encounter. As such, we need to look for research that accurately represents:
- Who is participating in the study
- What circumstances is the study being conducted under
- What is the research attempting to determine
Further, we want to ensure that:
- Findings are presented accurately and reflect what was shared by participants (raw data)
- A reasonably good explanation of how the researcher got from the raw data to their findings is presented
- The researcher adequately considered and accounted for their potential influence on the research process
As we talk about different tools we can use to help establish qualitative rigor, I will try to point out tips for what to look for as you are reading qualitative studies that can reflect these. While rigor can't "prove" quality, it can demonstrate steps that are taken that reflect thoughtfulness and attention on the part of the researcher(s). This is a link from the American Psychological Association on the topic of reviewing qualitative research manuscripts. It's a bit beyond the level of critiquing that I would expect from a beginning qualitative research student, however, it does provide a really nice overview of this process. Even if you aren't familiar with all the terms, I think it can be helpful in giving an overview of the general thought process that should be taking place.
To begin breaking down how to think about rigor, I find it helpful to have a framework to help understand different concepts that support or are associated with rigor. Lincoln and Guba (1985) have suggested such a framework for thinking about qualitative rigor that has widely contributed to standards that are often employed for qualitative projects. The overarching concept around which this framework is centered is trustworthiness. Trustworthiness is reflective of how much stock we should put in a given qualitative study—is it really worth our time, headspace, and intellectual curiosity? A study that isn't trustworthy suggests poor quality resulting from inadequate forethought, planning, and attention to detail in how the study was carried out. This suggests that we should have little confidence in the findings of a study that is not trustworthy.
According to Lincoln and Guba (1985)[22] trustworthiness is grounded in responding to four key ideas and related questions to help you conceptualize how they relate to your study. Each of these concepts is discussed below with some considerations to help you to compare and contrast these ideas with more positivist or quantitative constructs of research quality.
Truth value
You have already been introduced to the concept of internal validity. As a reminder, establishing internal validity is a way to ensure that the change we observe in the dependent variable is the result of the variation in our independent variable—did we actually design a study that is truly testing our hypothesis. In much/most qualitative studies we don't have hypotheses, independent or dependent variables, but we do still want to design a study where our audience (and ourselves) can be relatively sure that we as the researcher arrived at our findings through a systematic and scientific process, and that those findings can be clearly linked back to the data we used and not some fabrication or falsification of that data; in other words, the truth value of the research process and its findings. We want to give our readers confidence that we didn't just make up our findings or "see what we wanted to see".

Applicability
- who we were studying
- how we went about studying them
- what we found

Consistency

Neutrality

These concepts reflect a set of standards that help to determine the integrity of qualitative studies. At the end of this chapter you will be introduced to a range of tools to help support or reflect these various standards in qualitative research. Because different qualitative designs (e.g. phenomenology, narrative, ethnographic), that you will learn more about in Chapter 22 emphasize or prioritize different aspects of quality, certain tools will be more appropriate for these designs. Since this chapter is intended to give you a general overview of rigor in qualitative studies, exploring additional resources will be necessary to best understand which of these concepts are prioritized in each type of design and which tools best support them.
Key Takeaways
- Qualitative research is generally conducted within an interpretativist paradigm. This differs from the post-positivist paradigm in which most quantitative research originates. This fundamental difference means that the overarching aim of these different approaches to knowledge building differ, and consequently, our standards for judging the quality of research within these paradigms differ.
- Assessing the quality of qualitative research is important, both from a researcher and a practitioner perspective. On behalf of our clients and our profession, we are called to be critical consumers of research. To accomplish this, we need strategies for assessing the scientific rigor with which research is conducted.
- Trustworthiness and associated concepts, including credibility, transferablity, dependability and confirmability, provide a framework for assessing rigor or quality in qualitative research.
20.2 Ethical responsibility and cultural respectfulness
Learning Objectives
Learners will be able to...
- Discuss the connection between rigor and ethics as they relate to the practice of qualitative research
- Explain how the concepts of accountability and transparency lay an ethical foundation for rigorous qualitative research
The two concepts of rigor and ethics in qualitative research are closely intertwined. It is a commitment to ethical research that leads us to conduct research in rigorous ways, so as not to put forth research that is of poor quality, misleading, or altogether false. Furthermore, the tools that demonstrate rigor in our research are reinforced by solid ethical practices. For instance, as we build a rigorous protocol for collecting interview data, part of this protocol must include a well-executed, ethical informed consent process; otherwise, we hold little hope that our efforts will lead to trustworthy data. Both ethics and rigor shine a light on our behaviors as researchers. These concepts offer standards by which others can critique our commitment to quality in the research we produce. They are both tools for accountability in the practice of research.
Related to this idea of accountability, rigor requires that we promote a sense of transparency in the qualitative research process. We will talk extensively in this chapter about tools to help support this sense of transparency, but first, I want to explore why transparency is so important for ethical qualitative research. As social workers, our own knowledge, skills, and abilities to help serve our clients are our tools. Similarly, qualitative research demands the social work researcher be an actively involved human instrument in the research process.
While quantitative researchers also makes a commitment to transparency, they may have an easier job of demonstrating it. Let's just think about the data analysis stage of research. The quantitative researcher has a data set, and based on that data set there are certain tests that they can run. Those tests are mathematically defined and computed by statistical software packages and we have established guidelines for interpreting the results and reporting the findings. There is most certainly tremendous skill and knowledge exhibited in the many decisions that go into this analysis process; however, the rules and requirements that lay the foundation for these mathematical tests mean that much of this process is prescribed for us. The prescribed procedures offer quantitative researchers a shorthand for talking about their transparency.
In comparison, the qualitative researcher, sitting down with their data for analysis will engage in a process that will require them to make hundreds or thousands of decisions about what pieces of data mean, what label they should have, how they relate to other ideas, what the larger significance is as it relates to their final results. That isn't to say that we don't have procedures and processes as qualitative researchers, we just can't rely on mathematics to make these decisions precise and clear. We have to rely on ourselves as human instruments. Adopting a commitment to transparency in our research as qualitative researchers means that we are actively describing for our audience the role we have as human instruments and we consider how this is shaping the research process. This allows us to avoid unethically representing what we did in our research process and what we found.
I think that as researchers we can sometimes think of data as an object that is not inherently valuable, but rather a means to an end. But if we see qualitative data as part of sacred stories that are being shared with us, doesn't it feel like a more precious resource? Something worthy of thoughtfully and even gently gathering, something that needs protecting and safe-keeping. Adhering to a rigorous research process can help to honor these commitments and avoid the misuse of data as a precious resource. Thinking like this will hopefully help us to demonstrate greater cultural humility as social work researchers.
Key Takeaways
- Ethics and rigor both are interdependent and call attention to our behaviors as researchers and the quality and care with which our research is conducted.
- Accountability and transparency in qualitative research helps to demonstrate that as researchers we are acting with integrity. This means that we are clear about how we are conducting our research, what decisions we are making during the research process, and how we have arrived at these decisions.
Exercises
While this activity is early in the chapter, I want you to consider for a few moments about how accountability relates to your research proposal.
- Who are you accountable to as you carry plan and carry out your research
- In what ways are you accountable to each of the people you listed in the previous question?
20.3 Critical considerations
Learning Objectives
Learners will be able to...
- Identify some key questions for a critical critique of research planning and design
- Differentiate some alternative standards for rigor according to more participatory research approaches
As I discussed above, rigor shines a spotlight on our actions as researchers. A critical perspective is one that challenges traditional arrangements of power, control and the role of structural forces in maintaining oppression and inequality in society. From this perspective, rigor takes on additional meaning beyond the internal integrity of the qualitative processes used by you or I as researchers, and suggest that standards of quality need to address accountability to our participants and the communities that they represent, NOT just the scientific community. There are many evolving dialogues about what criteria constitutes "good" research from critical traditions, including participatory and empowerment approaches that have their roots in critical perspective. These discussions could easily stand as their own chapter, however, for our purposes, we will borrow some questions from these critical debates to consider how they might inform the work we do as qualitative researchers.


Who gets to ask the questions?
In the case of your research proposal, chances are you are outlining your research question. Because our research question truly drives our research process, it carries a lot of weight in the planning and decision-making process of research. In many instances, we bring our fully-formed research projects to participants, and they are only involved in the collection of data. But critical approaches would challenge us to involve people who are impacted by issues we are studying from the onset. How can they be involved in the early stages of study development, even in defining our question? If we treat their lived experience as expertise on the topic, why not start early using this channel to guide how we think about the issue? This challenges us to give up some of our control and to listen for the "right" question before we ask it.
Who owns the data and the findings?
Answering this question from a traditional research approach is relatively clear—the researcher or rather, the university or research institution they represent. However, critical approaches question this. Think about this specifically in terms of qualitative research. Should we be "owning" pieces of other people's stories, since that is often the data we are working with? What say do people get in what is done with their stories and the findings that are derived from them? Unfortunately, there aren't clear answers. These are some critical questions that we need to struggle with as qualitative researchers.
- How can we disrupt or challenge current systems of data ownership, empowering participants to maintain greater rights?
- What could more reciprocal research ownership arrangments look like?
- What are the benefits and consequences of disrupting this system?
- What are the benefits and consequences of perpetuating our current system?

What is the sustained impact of what I'm doing?
As qualitative researchers, our aim is often exploring meaning and developing understanding of social phenomena. However, criteria from more critical traditions challenge us to think more tangibly and with more immediacy. They require us to answer questions about how our involvement with this specific group of people within the context of this project may directly benefit or harm the people involved. This not only applies in the present but also in the future.
We need to consider questions like:
- How has our interaction shaped participants' perceptions of research?
- What are the ripple effects left behind from the questions we raised by our study?
- What thoughts or feelings have been reinforced or challenged, both within the community but also for outsiders?
- Have we built/strengthened/damaged relationships?
- Have we expanded/depleted resources for participants?
We need to reflect on these topics in advance and carefully considering the potential ramifications of our research before we begin. This helps to demonstrate critical rigor in our approach to research planning. Furthermore, research that is being conducted in participatory traditions should actively involve participants and other community members to define what the immediate impacts of the research should be. We need to ask early and often, what do they need as a community and how can research be a tool for accomplishing this? Their answers to these questions then become the criteria on which our research is judged. In designing research for direct and immediate change and benefit to the community, we also need to think about how well we are designing for sustainable change. Have we crafted a research project that creates lasting transformation, or something that will only be short-lived?
As students and as scholars we are often challenged by constraints as we address issues of rigor, especially some of the issues raised here. One of the biggest constraints is time. As a student, you are likely building a research proposal while balancing many demands on your time. To actively engage community members and to create sustainable research projects takes considerable time and commitment. Furthermore, we often work in highly structured systems that have many rules and regulations that can make doing things differently or challenging convention quite hard. However, we can begin to make a more equity-informed research agenda by:
- Reflecting on issues of power and control in our own projects
- Learning from research that models more reciprocal relationships between researcher and researched
- Finding new and creative ways to actively involve participants in the process of research and in sharing the benefits of research
In the resource box below, you will find links for a number of sources to learn more about participatory research methods that embody the critical perspective in research that we have been discussing.
As we turn our attention to rigor in the various aspects of the qualitative research process, continue to think about what critical criteria might also apply to each of these areas.
Key Takeaways
- Traditional research methods, including many qualitative approaches, may fail to challenge the ways that the practice of research can disenfranchise and disempower individauls and communities.
- Researchers from critical perspectives often question the power arrangments, roles, and objectives of more traditional research methods, and have been developing alternatives such as participatory research approaches. These participatory approaches engage participants in much more active ways and furthermore, they evaluate the quality of research by the direct and sustained benefit that it brings to participants and their communities.
Resources
Bergold, J., & Thomas, S. (2012). Participatory research methods: A methodological approach in motion
Center for Community Health and Development, University of Kansas. (n.d.). Community toolbox: Section.2 Community-based participatory research
New Tactics in Human Rights. (n.d.). Participatory research for action.
Pain et al. (2010). Participatory action research toolkit: An introduction to using PAR as an approach to learning, research and action.
Participate. (n.d.). Participatory research methods.
20.4 Data capture: Striving for accuracy in our raw data
Learning Objectives
Learners will be able to...
- Explain the importance of paying attention to the data collection process for ensuring rigor in qualitative research
- Identify key points that they will need to consider and address in developing a plan for gathering data to support rigor in their study
It is very hard to make a claim that research was conducted in a rigorous way if we don't start with quality raw data. That is to say, if we botch our data collection, we really can't produce trustworthy findings, no matter how good our analysis is. So what is quality raw data? From a qualitative research perspective, quality raw data means that the data we capture provides an accurate representation of what was shared with us by participants or through other data sources, such as documents. This section is meant to help you consider rigor as it pertains to how you capture your data. This might mean how you document the information from your interviews or focus groups, how you record your field notes as you are conducting observations, what you track down and access for other artifacts, or how you produce your entries in your reflexive journal (as this can become part of your data, as well).
This doesn't mean that all your data will look the same. However, you will want to anticipate the type(s) of data you will be collecting and what format they will be in. In addition, whenever possible and appropriate, you will want the data you collect to be in a consistent format. So, if you are conducting interviews and you decide that you will be capturing this data by taking field notes, you will use a similar strategy for gathering information at each interview. You would avoid using field notes for some, recording and transcribing others, and then having emailed responses from the remaining participants. You might be wondering why this matters, after all, you are asking them the same questions. However, using these different formats to capture your data can make your data less comparable. This may have led to different information being shared by the participant and different information being captured by the researcher. For instance, if you rely on email responses, you lose the ability to follow up with probing questions you may have introduced in an in-person interview. Those participants who were recorded may not have felt as free to share information when compared to those interviews where you took field notes. It becomes harder to know if variation in your data is due to diversity in peoples' experiences or just differences in how you went about capturing your data. Now we will turn our attention to quality in different types of data.
As qualitative researchers, we often are dealing with written data. At times, it may be participants who are doing the writing. We may ask participants to provide written responses to questions or we may use writing samples as artifacts that are produced for some other purpose that we have permission to include in our study. In either case, ideally we are including this written data with as little manipulation as possible. If we do things like take passages or ideas out of context or interpret segments in our own words, we run a much greater risk of misrepresenting the data that is being shared with us. This is a direct threat to rigor, compromising the quality of the raw data we are collecting. If we need to clarify what a participant means by one of their responses and we have the opportunity to follow up with them, we want to capture their own words as closely as we can when they provide their explanation. This is also true if we ask participants to provide us with drawings. For instance, we may ask youth to provide a drawn response to a question as an age-appropriate way to respond to a question, but we might follow-up by asking them to explain their drawing to us. We would want to capture their description as close to their own words as possible, including both the drawing and the description in our data.

Researchers may also be responsible for producing written data. Rigorous field notes strive to capture participants' words as accurately as possible, which usually means quoting more and paraphrasing less. Of course we can't avoid paraphrasing altogether (unless you have incredible shorthand skills, which I definitely do not), but the more interpreting or filtering we do as we capture our data, the less trustworthy it becomes. You also want to stick to a consistent method of recording your field notes. It becomes much harder to analyze your data if you have one system one day and another system another day. The quality of the notes may differ greatly and differences in organization may make it challenging to compare across your data. Finally, rigorous field notes usually capture context, as well. If you are gathering field notes for an interview or during a focus group, this may mean that you take note of non-verbal information during the exchange. If you are conducting an observation, your field notes might contain detailed information about the setting and circumstances of the observation.
As qualitative researchers, we may also be working with audio, video, or other forms of media data. Much of what we have already discussed in respect to written data also applies to these data formats, as well. The less we manipulate or change the original data source, the better. For example, if you have an audio recording of your focus group, you want your transcript to be as close to verbatim as possible. Also, if we are working with a visual or aural medium, like a performance, capturing context and description—including audience reactions—with as much detail as possible is vital if we are looking to analyze the meaning of such an event or experience.
This topic shouldn't require more than a couple sentences as you write up your research proposal. However, these sentences should reflect some careful forethought and planning. Remember, this is the hand-off! If you are a relay runner, this is the point where the baton gets passed as the participant or source transfers information to the study. Also, you want to ensure that you select a strategy that can be consistent and part of systematic process. Now we need to come up with a plan for managing our data.
Examples
Data will be collected using semi-structured interviews. Interviews will be digitally recorded and transcribed verbatim. In addition, the researcher will take field notes during each interview (see field note template, appendix A).
As they are gathered, documents will be assigned a study identification number. Along with their study ID, a brief description of the document, its source, and any other historical information will be kept in the data tracking log (see data tracking log, appendix B).
Key Takeaways
- Anticipating and planning for how you will systematically and consistently gather your data is crucial for a rigorous qualitative research project.
- When conducting qualitative research, we not only need to consider the data that we collect from other sources, but the data that we produce ourselves. As human instruments in the research process, our reaction to the data also becomes a form of data that can shape our findings. As such, we need to think about how we can capture this as well.
Exercises
- How will you ensure that you use a consistent and systematic approach for qualitative data collection in your proposal?
20.5 Data management: Keeping track of our data and our analysis
Learning Objectives
Learners will be able to...
- Explain how data management and data analysis in qualitative projects can present unique challenges or opportunities for demonstrating quality in the research process
- Plan for key elements to address or include in a data management plan that supports qualitative rigor in the study
Elements to think about
Once data collection begins, we need a plan for what we are going to do with it. As we talked about in our chapter devoted to qualitative data collection, this is often an important point of departure between quantitative and qualitative methods. Quantitative research tends to be much more sequential, meaning that first we collect all the data, then we analyze the data. If we didn't do it this way, we wouldn't know what numbers we are dealing with. However, with qualitative data, we are usually collecting and beginning to analyze our data simultaneously. This offers us a great opportunity to learn from our data as we are gathering it. However, it also means that if you don't have a plan for how you are going to manage these dual processes of data collection and data analysis, you are going to get overwhelmed twice as fast! A rigorous process will have a clearly defined process for labeling and tracking your data artifacts, whether they are text documents (e.g. transcripts, newspaper clippings, advertisements), photos, videos, or audio recordings. These may be physical documents, but more often than not, they are electronic. In either case, a clear, documented labeling system is required. This becomes very important because you are going to need to come back to this artifact at some point during your analysis and you need to have a way of tracking it down. Let's talk a bit more about this.
You were introduced to the term iterative process in our previous discussions about qualitative data analysis. As a reminder, an iterative process is one that involves repetition, so in the case of working with qualitative data, it means that we will be engaging in a repeating and evolving cycle of reviewing our data, noting our initial thoughts and reactions about what the data means, collecting more data, and going back to review the data again. Figure 20.1 depicts this iterative process. To adopt a rigorous approach to qualitative analysis, we need to think about how we will capture and document each point of this iterative process. This ishow we demonstrate transparency in our data analysis process, how we detail the work that we are doing as human instruments.
During this process, we need to consider:
- How will we capture our thoughts about the data, including what we are specifically responding to in the data?
- How do we introduce new data into this process?
- How do we record our evolving understanding of the data and what those changes are prompted by?
So we have already talked about the importance of labeling our artifacts, but each artifact is likely to contain many ideas. For instance, think about the many ideas that are shared in a single interview. Because of this, we need to also have a clear and standardized way of labeling smaller segments of data within each artifact that represent discrete or separate ideas. If you recall back to our analysis chapter, these labels are called units. You are likely to have many, many units in each artifact. Additionally, as suggested above, you need a way to capture your thought process as you respond to the data. This documentation is called memoing, a term you were introduced to in our analysis chapter. These various components, labeling your artifacts, labeling your units, and memoing, come together as you produce a rigorous plan for how you document your data analysis. Again, rigor here is closely associated with transparency. This means that you are using these tools to document a clear road map for how you got from your raw data to your findings. The term for this road map is an audit trail, and we will speak more about it in the next section. The test of this aspect of rigor becomes your ability to work backwards, or better yet, for someone else to work backwards. Could someone not connected with your project look at your findings, and using your audit trail, trace these ideas all the way back to specific points in your raw data? The term for this is having an external audit and will also be further explained below. If you can do this, we sometimes say that your findings are clearly "grounded in your data".
What our plan for data management might look like.
If you are working with physical data, you will need a system of logging and storing your artifacts. In addition, as you break your artifacts down into units you may well be copying pieces of these artifacts onto small note cards or post-its that serve as your data units. These smaller units become easier to manipulate and move around as you think about what ideas go together and what they mean collectively. However, each of these smaller units need a label that links them back to their artifact. But why do I have to go through all this? Well, it isn't just for the sake of transparency and being able to link your findings back to the original raw data, although that is certainly important. You also will likely reach a point in your analysis where themes are coming together and you are starting to make sense of things. When this occurs, you will have a pile of units from various artifacts under each of these themes. At this point you will want to know where the information in the units came from. If it was verbal data, you will want to know who said it or what source it came from. This offers us important information about the context of our findings and who/what they are connected to. We can't determine this unless we have a good labeling system.

You will need to come up with a system that makes sense to you and fits for your data. As an example, I'm often working with transcripts from interviews or focus groups. As I am collecting my data, each transcript is numbered as I obtain it. Also, the transcripts themselves have continuous line numbers on them. When I start to break-up or deconstruct my data, each unit gets a label that consists of two numbers separated by a period. The number before the period is the transcript that the unit came from and the number after the period is the line number within that transcript so that I can find exactly where the information is. So, if I have a unit labeled 3.658, it means that this data can be found in my transcript labeled 3 and on line 658.
Now, I often use electronic versions of my transcripts when I break them up. As I showed in our data analysis chapter, I create an excel file where I can cut and paste the data units, their label, and the preliminary code I am assigning to this idea. I find excel useful because I can easily sort my data by codes and start to look for emerging themes. Furthermore, above I mentioned memoing, or recording my thoughts and responses to the data. I can easily do this in excel, by adding an additional column for memoing where I can put my thoughts/responses by a particular unit and date it, so I know when I was having that thought. Generally speaking, I find that excel makes it pretty easy for me to manipulate or move my data around while I'm making sense of it, while also documenting this. Of course, the qualitative data analysis software packages that I mentioned in our analysis chapter all have their own systems for activities such as assigning labels, coding, and memoing. And if you choose to use one of these, you will want to be well acquainted with how to do this before you start collecting data. That being said, you don't need software or even excel to do this work. I know many qualitative researchers who prefer having physical data in front of them, allowing them to shift note cards around and more clearly visualize their emerging themes. If you elect for this, you just need to make sure you track the moves you are making and your thought process during the analysis. And be careful if you have a cat, mine would have a field day with piles of note cards left on my desk!
Key Takeaways
- Due to the dynamic and often iterative nature of qualitative research, we need to proactively consider how we will store and analyze our qualitative data, often at the same time we are collecting it.
- Whatever data management system we plan for, it needs to have consistent ways of documenting our evolving understanding of what our data mean. This documentation acts as an important bridge between our raw qualitative data and our qualitative research findings, helping to support rigor in our design.
20.6 Tools to account for our influence
Learning Objectives
Learners will be able to...
- Identify key tools for enhancing qualitative rigor at various stages of the research process
- Begin to critique the quality of existing qualitative studies based on the use of these tools
- Determine which tools may strengthen the quality of our own qualitative research designs
So I've saved the best for last. This is a concrete discussion about tools that you can utilize to demonstrate qualitative rigor in your study. The previous sections in this chapter suggest topics you need to think about related to rigor, but this suggests strategies to actually accomplish it. Remember, these are tools you should also be looking for as you examine other qualitative research studies. As I previously mentioned, you won't be looking to use all of these in any one study, but rather determining which tools make the most sense based on your study design.
Some of these tools apply throughout the research process, while others are more specifically applied at one stage of research. For instance, an audit trail is created during your analysis phase, while peer debriefing can take place throughout all stages of your research process. These come to us from the work of Lincoln and Guba (1985).[23] Along with the argument that we need separate criteria for judging the quality of from the interpretivist paradigm (as opposed to positivist criteria of reliability and validity), they also proposed a compendium of tools to help meet these criteria. We will review each of these tools and an example will be provided after the description.

Observer triangulation
Observer triangulation involves including more than one member of your research team to aid in analyzing the data. Essentially, you will have at least two sets of eyes looking at the data, drawing it out, and then comparing findings, converging on agreement about what the final results should be. This helps us to ensure that we aren’t just seeing what we want to see.
Data triangulation
Data triangulation is a strategy that you build into your research design where you include data from multiple sources to help enhance your understanding of a topic. This might mean that you include a variety of groups of people to represent different perspectives on the issue. This can also mean that you collect different types of data. The main idea here is that by incorporating different sources of data (people or types), you are seeking to get a more well-rounded or comprehensive understanding of the focus of your study.
Example.
People: Instead of just interviewing mental health consumers about their treatment, you also include family members and providers.
Types: I have conducted a case study where we included interviews and the analysis of multiple documents, such as emails, agendas, and meeting minutes.
Peer debriefing
Peer debriefing means that you intentionally plan for and meet with a qualitative researcher outside of your team to discuss your process and findings and to help examine the decisions you are making, the logic behind them, and your potential influence and accountability in the research process. You will often meet with a peer debriefer multiple times during your research process and may do things like: review your reflexive journal; review certain aspects of your project, such as preliminary findings; discuss current decisions you are considering; and review the current status of your project. The main focus here is building in some objectivity to what can become a very subjective process. We can easily become very involved in this research and it can be hard for us to step back and thoughtfully examine the decisions we are making.
Member-checking
Member-checking has to do with incorporating research participants into the data analysis process. This may mean actively including them throughout the analysis, either as a co-researcher or as a consultant. This can also mean that once you have the findings from your analysis, you take these to your participants (or a subset of your participants) and ask them to review these findings and provide you feedback about their accuracy. I will often ask participants when I member-check, can you hear your voice in these findings? Do you recognize what you shared with me in these results? We often need to preface member-checking by saying that we are bringing together many people’s ideas, so we are often trying to represent multiple perspectives, but we want to make sure that their perspective is included in there. This can be a very important step in ensuring that we did a reasonable job getting from our raw data to our findings…did we get it right. It also gives some power back to participants, as we are giving them some say in what our findings look like.

Thick description
Providing a thick description means that you are giving your audience a rich, detailed description of your findings and the context in which they exist. As you read a thick description, you walk away feeling like you have a very vivid picture of what the research participants felt, thought, or experienced, and that you now have a more complete understanding of the topic being studied. Of course, a thick description can’t just be made up at the end. You can’t hope to produce a thick description if you haven’t done work early on to collect detailed data and performed a thorough analysis. Our main objective with a thick description is being accountable to our audience in helping them to understand what we learned in the most comprehensive way possible.
Reflexivity
Reflexivity pertains to how we understand and account for our influence, as researchers, on the research process. In social work practice, we talk extensively about our “use of self” as social workers, meaning that we work to understanding how our unique personhood (who we are) impacts or influences how we work with our clients. Reflexivity is about applying this to the process of research, rather than practice. It assumes that our values, beliefs, understanding, and experiences all may influence the decisions that we make as we engage in research. By engaging in qualitative research with reflexivity, we are attempting to be transparent about how we are shaping and being shaped by the research we are conducting.
Prolonged engagement
Prolonged engagement means that we are extensively spending time with participants or are in the community we are studying. We are visiting on multiple occasions during the study in an attempt to get the most complete picture or understanding possible. This can be very important for us as we attempt to analyze and interpret our data. If we haven’t spent enough time getting to know our participants and their community, we may miss the meaning of data that is shared with us because we don’t understand the cultural subtext in which this data exists. The main idea here is that we don’t know what we don’t know; furthermore, we can’t know it unless we invest time getting to know it! There’s no short-cut here, you have to put in the time.
Audit trail
Creating an audit trail is something we do during our data analysis process as qualitative researchers. An audit trail is essentially creating a map of how you got from your raw data to your research findings. This means that we should be able to work backwards, starting with your research findings and trace them back to your raw data. It starts with labeling our data as we begin to break it apart (deconstruction) and then reassemble it (reconstruction). It allows us to determine where ideas came from and how/why we put ideas together to form broader themes. An audit trail offers transparency in our data analysis process. It is the opposite of the “black box” we spoke about in our qualitative analysis chapter, making it clear how we got from point A to point B.

External audit
An external audit is when we actually bring in a qualitative researcher not connected to our project once the study has been completed to examine the research project and the findings to “evaluate the accuracy and evaluate whether or not the findings, interpretations and conclusions are supported by the data” (Robert Wood Johnson Foundation, External Audits). An external auditor will likely look at all of our research materials, but will likely make extensive use of our audit trail to ensure that a clear link can be established between our findings and the raw data we collected by an external observer. Much like a peer debriefer, an external auditor can offer an outside critique of the study, thereby helping us to reflect on the work we are doing and how we are going about it.
Negative case analysis
Negative case analysis involves including data that contrasts, contradicts, or challenges the majority of evidence that we have found or expect to find. This may come into play in our sampling, meaning that we may seek to recruit or include a specific participant or group of participants because they represent a divergent opinion. Or, as we begin our analysis, we may identify a unique or contrasting idea or opinion that seems to contradict the majority of what our other data seem to be point to. In this case, we choose to intentionally analyze and work to understand this unique perspective in our data. As with a thick description, a negative case analysis is attempting to offer the most comprehensive and complete understanding of the phenomenon we are studying, including divergent or contradictory ideas that may be held about it.
Now let's take some time to think through each of the stages of the design process and consider how we might apply some of these strategies. Again, these tools are to help us, as human instruments, better account for our role in the qualitative research process and also to enhance the trustworthiness of our research when we share it with others. It is unrealistic that you would apply all of these, but attention to some will indicate that you have been thoughtful in your design and concerned about the quality of your work and the confidence in your findings.
First let's discuss sampling. We have already discussed that qualitative research generally relies on non-probability sampling and have reviewed some specific non-probability strategies you might use. However, along with selecting a strategy, you might also include a couple of the rigor-related tools discussed above. First, you might choose to employ data triangulation. For instance, maybe you are conducting an ethnography studying the culture of a peer-support clubhouse. As you are designing your study, along with extensive observations you plan to make in the clubhouse, you are also going to conduct interviews with staff, board members, and focus groups with members. In this way you are combining different types of data (i.e. observations, focus groups, interviews) and perspectives (i.e. yourself as the researcher, members, staff, board). In addition, you might also consider using negative case analysis. At the planning stage, this could involve you intentionally sampling a case or set of cases that are likely to provide an alternative view or perspective compared to what you might expect to find. Finally, specifically articulating your sampling rationale can also enhance the rigor of your research (Barusch, Gringeri, & George, 2011).[24] While this isn't listed in our tools table, it is generally a good practice when reporting your research (qualitative or quantitative) to outline your sampling strategy with a brief rationale for the choices you made. This helps to improve the transparency of your study.
Next, we can progress to data gathering. The main rigor-related tool that directly applies to this stage of your design is likely prolonged engagement. Here we build in or plan to spend extensive time with participants gathering data. This might mean that we return for repeated interviews with the same participants or that we go back numerous times to make observations and take field notes. While this can take many forms, the overarching idea here is that you build in time to immerse yourself in the context and culture that you are studying. Again, there is no short-cut here, it demands time in the field getting to know people, places, significance, history, etc. You need to appreciate the context and the culture of the situation you are studying. Something special to consider here is insider/outsider status. If you would consider yourself an "outsider", that is to say someone who does not belong to the same group or community of people you are studying, it may be quite obvious that you will need to spend time getting to know this group and take considerable time observing and reflecting on the significance of what you see. However, if you are a researcher who is a member of the particular community you are studying, or an "insider", I would suggest that you still need to work to objectively to take a step back, make observations, and try to reflect on what you see, what you thought you knew, and what you come to know about the community you belong to. In both cases, prolonged engagement requires good self-reflection and observation skills.
A number of these tools may be applied during the data analysis process. First, if you have a research team, you might use observer triangulation, although this might not be an option as a student unless you are building a proposal as a group. As explained above, observer triangulation means that more than one of you will be examining the data that has been collected and drawing results from it. You will then compare these results and ultimately converge on your findings.
Example. I'm currently using the following strategy on a project where we are analyzing focus group data that was collected over a number of focus groups. We have a team of four researchers and our process involves:
- reviewing our initial focus group transcripts
- individually identifying important categories that were present
- collectively processing these together and identifying specific labels we would use for a second round of coding
- individually returning to the transcripts with our codes and coding all the transcripts
- collectively meeting again to discuss what subthemes fell under each of the codes and if the codes fit or needed to be changed/merged/expanded
While the process was complex, I do believe this triangulation of observers enriched our analysis process. It helped us to gain a clearer understanding of our results as we collectively discussed and debated what each theme meant based on our individual understandings of the data.
While we did discuss negative case analysis above in the sampling phase, it is also worth mentioning here. Contradictory findings may creep up during our analysis. One of our participants may share something or we may find something in a document that seemingly is at odds with the majority of the rest of our data. Rather than ignoring this, negative case analysis would seek to understand this perspective and what might be behind this contradiction. In addition, we may choose to construct an audit trail as we move from raw data to our research findings during our data analysis. This means that we will institute a strategy for tracking our analysis process. I imagine that most researchers develop their own variation on this tracking process, but at its core, you need to find a way to label your segments of data so that you know where they came from once you start to break them up. Furthermore, you will be making decisions about what groups of data belong together and what they mean. Your tracking process for your audit trail will also have to provide a way to document how you arrived at these decisions. Often towards the end of an analysis process, researchers may choose to employ member checking (although you may also implement this throughout your analysis). In the example above where I was discussing our focus group project, we plan to take our findings back to some of our focus group participants to see if they feel that we captured the important information based on what they shared with us. As discussed in sampling, it is also a good practice to make sure to articulate your qualitative analysis process clearly. Unfortunately, I've read a number of qualitative studies where the researchers provide little detail regarding what their analysis looked like and how they arrived at their results. This often leaves me with questions about the quality of what was done.
Now we need to share our research with others. The most relevant tool specific to this phase is providing a thick description of our results. As indicated in the table, a thick description means that we offer our audience a very detailed, rich narrative in helping them to interpret and make sense of our results. Remember, the main aim of qualitative research is not necessarily to produce results that generalize to a large group of people. Rather, we are seeking to enhance understanding about a particular experience, issue, or phenomenon by studying it very extensively for a relatively small sample. This produces a deep, as opposed to, a broad understanding. A thick description can be very helpful by offering detailed information about the sample, the context in which the study takes place, and a thorough explanation of findings and often how they relate to each other. As a consumer of research, a thick description can help us to make our own judgments about the implications of these results and what other situations or populations these findings might apply to.

You may have noticed that a few of the tools in our table haven't yet been discussed in the qualitative process yet. This is because some of these rigor-related tools are meant to span the researcher process. To begin with, reflexivity is a tool that best applied through qualitative research. I encourage students in my social work practice classes to find ways to build reflexivity into their professional lives as a way of improving their professional skills. This is no less true of qualitative research students. Throughout our research process, we need to consider how our use-of-self is shaping the decisions we are making and how the research may be transforming us during the process. What led you to choose your research question? Why did you group those ideas together? What caused you to label your theme that? What words do you use to talk about your study at a conference? The qualitative researcher has much influence throughout this process, and self-examination of that influence can be an important piece of rigor. As an example, one step that I sometimes build into qualitative projects is reflexively journaling before and after interviews. I'm often driving to these interviews, so I'll turn my Bluetooth on in the car and capture my thoughts before and after, transcribing them later. This helps me to check-in with myself during data collection and can help me illuminate insights I might otherwise miss. I have also found this to be helpful to use in my peer debriefing. Peer debriefing can be used throughout the research process. Meeting with a peer debriefer throughout the research process can be a good way to consistently reflect on your progress and the decisions you are making throughout a project. A peer debriefer can make connections that we may otherwise miss and question aspects of our project that may be important for us to explore. As I mentioned, combining reflexivity with peer debriefing can be a powerful tool for processing our self-reflection in connection with the progress of our project.
Finally, the use of an external audit really doesn't come into play until the end of the research process, but an external auditor will look extensively at the whole research process. Again, this is a researcher who is unattached to the project and seeking to follow the path of the project in hopes of providing an external perspective on the trustworthiness of the research process and its findings. Often, these auditors will begin at the end, starting with the findings, and attempt to trace backwards to the beginning of the project. This is often quite a laborious task and some qualitative scholars debate whether the attention to objectivity in this strategy may be at odds with the aims of qualitative research in illuminating the uniquely subjective experiences of participants by inherently subjective researchers. However, it can be a powerful tool for demonstrating that a systematic approach was used.
As you are thinking about designing your qualitative research proposal, consider how you might use some of these tools to strengthen the quality of your proposed research. Again, you might be using these throughout the entire research process, or applying them more specifically to one stage of the process (e.g. data collection, data analysis). In addition, as you are reviewing qualitative studies to include in your literature review or just in developing your understanding of the topic, make sure to look out for some of these tools being used. They are general indicators that we can use to assess the attention and care that was given to using a scientific approach to producing the knowledge that is being shared.
Key Takeaways
- As qualitative researchers there are a number of tools at your disposal to help support quality and rigor. These tools can aid you in assessing the quality of others' work and in supporting the quality of your own design.
- Qualitative rigor is not a box we can tick complete somewhere along our research project's timeline. It is something that needs to be attended to thoughtfully throughout the research process; it is a commitment we make to our participants and to our potential audience.
Exercises
List out 2-3 tools that seem like they would be a good fit for supporting the rigor of your qualitative proposal. Also, provide a justification as to why they seem relevant to the design of your research and what you are trying to accomplish.
- Tool:
- Justification:
- Tool:
- Justification:
- Tool:
- Justification:
Chapter Outline
- Ethical responsibility and cultural respectfulness (7 minute read)
- Critical considerations (8 minute read)
- Find the right qualitative data to answer my research question (17 minute read)
- How to gather a qualitative sample (21 minute read)
- What should my sample look like? (9 minute read)
Content warning: examples in this chapter contain references to substance use, ageism, injustices against the Black community in research (e.g. Henrietta Lacks and Tuskegee Syphillis Study), children and their educational experiences, mental health, research bias, job loss and business closure, mobility limitations, politics, media portrayals of LatinX families, labor protests, neighborhood crime, Batten Disease (childhood disorder), transgender youth, cancer, child welfare including kinship care and foster care, Planned Parenthood, trauma and resilience, sexual health behaviors.
Now let's change things up! In the previous chapters, we were exploring steps to create and carry out a quantitative research study. Quantitative studies are great when we want to summarize data and examine or test relationships between ideas using numbers and the power of statistics. However, qualitative research offers us a different and equally important tool. Sometimes the aim of research is to explore meaning and experience. If these are the goals of our research proposal, we are going to turn to qualitative research. Qualitative research relies on the power of human expression through words, pictures, movies, performance and other artifacts that represent these things. All of these tell stories about the human experience and we want to learn from them and have them be represented in our research. Generally speaking, qualitative research is about the gathering up of these stories, breaking them into pieces so we can examine the ideas that make them up, and putting them back together in a way that allows us to tell a common or shared story that responds to our research question. Back in Chapter 7 we talked about different paradigms.

Before plunging further into our exploration of qualitative research, I would like to suggest that we begin by thinking about some ethical, cultural and empowerment-related considerations as you plan your proposal. This is by no means a comprehensive discussion of these topics as they relate to qualitative research, but my intention is to have you think about a few issues that are relevant at each step of the qualitative process. I will begin each of our qualitative chapters with some discussion about these topics as they relate to each of these steps in the research process. These sections are specially situated at the beginning of the chapters so that you can consider how these principles apply throughout the proceeding discussion. At the end of this chapter there will be an opportunity to reflect on these areas as they apply specifically to your proposal. Now, we have already discussed research ethics back in Chapter 8. However, as qualitative researchers we have some unique ethical commitments to participants and to the communities that they represent. Our work as qualitative researchers often requires us to represent the experiences of others, which also means that we need to be especially attentive to how culture is reflected in our research. Cultural respectfulness suggests that we approach our work and our participants with a sense of humility. This means that we maintain an open mind, a desire to learn about the cultural context of participants' lives, and that we preserve the integrity of this context as we share our findings.
17.1 Ethical responsibility and cultural respectfulness
Learning Objectives
Learners will be able to...
- Explain how our ethical responsibilities as researchers translate into decisions regarding qualitative sampling
- Summarize how aspects of culture and identity may influence recruitment for qualitative studies
Representation
Representation reflects two important aspects of our work as qualitative researchers, who is present and how are they presented. First, we need to consider who we are including or excluding in or sample. Recruitment and sampling is especially tied to our ethical mandate as researchers to uphold the principle of justice under the Belmont Report[25] (see Chapter 6 for additional information). Within this context we need to:
- Assure there is fair distribution of risks and benefits related to our research
- Be conscientious in our recruitment efforts to support equitable representation
- Ensure that special protections to vulnerable groups involved in research activities are in place
As you plan your qualitative research study, make sure to consider who is invited and able to participate and who is not. These choices have important implications for your findings and how well your results reflect the population you are seeking to represent. There may be explicit exclusions that don't allow certain people to participate, but there may also be unintended reasons people are excluded (e.g. transportation, language barriers, access to technology, lack of time).
The second part of representation has to do with how we disseminate our findings and how this reflects on the population we are studying. We will speak further about this aspect of representation in Chapter 21, which is specific to qualitative research dissemination. For now, it is enough to know that we need to be thoughtful about who we attempt to recruit and how effectively our resultant sample reflects our population.
Being mindful of history
As you plan for the recruitment of your sample, be mindful of the history of how this group (and/or the individuals you may be interacting with) has been treated – not just by the research community, but by others in positions of power. As researchers, we usually represent an outside influence and the people we are seeking to recruit may have significant reservations about trusting us and being willing to participate in our study (often grounded in good historical reasons—see Chapter 6 for additional information). Because of this, be very intentional in your efforts to be transparent about the purpose of your research and what it involves, why it is important to you, as well as how it can impact the community. Also, in helping to address this history, we need to make concerted efforts to get to know the communities that we research with well, including what is important to them.
Stories as sacred: How are we requesting them?
Finally, it is worth pointing out that as qualitative researchers, we have an extra layer of ethical and cultural responsibility. While quantitative research deals with numbers, as qualitative researchers, we are generally asking people to share their stories. Stories are intimate, full of depth and meaning, and can reveal tremendous amounts about who we are and what makes us tick. Because of this, we need to take special care to treat these stories as sacred. I will come back to this point in subsequent chapters, but as we go about asking for people to share their stories, we need to do so humbly.
Key Takeaways
- As researchers, we need to consider how our participant communities have been treated historically, how we are representing them in the present through our research, and the implications this representation could have (intended and unintended) for their lives. We need to treat research participants and their stories with respect and humility.
- When conducting qualitative research, we are asking people to share their stories with us. These "data" are personal, intimate, and often reflect the very essence of who our participants are. As researchers, we need to treat research participants and their stories with respect and humility.
17.2 Critical considerations
Learning Objectives
Learners will be able to...
- Assess dynamics of power in sampling design and recruitment for individual participants and participant communities
- Create opportunities for empowerment through early choice points in key research design elements
Power
Related to the previous discussion regarding being mindful of history, we also need to consider the current dynamics of power between researcher and potential participant. While we may not always recognize or feel like we are in a position of power, as researchers we hold specialized knowledge, a particular skill set, and what we do can with the data we collect can have important implications and consequences for individuals, groups, and communities. All of these contribute to the formation of a role ascribed with power. It is important for us to consider how this power is perceived and whenever possible, how we can build opportunities for empowerment that can be built into our research design. Examples of some strategies include:
- Recruiting and meeting in spaces that are culturally acceptable
- Finding ways to build participant choice into the research process
- Working with a community advisory group during the research process (explained further in the example box below)
- Designing informative and educational materials that help to thoroughly explain the research process in meaningful ways
- Regularly checking with participants for understanding
- Asking participants what they would like to get out of their participation and what it has been like to participate in our research
- Determining if there are ways that we can contribute back to communities beyond our research (developing an ongoing commitment to collaboration and reciprocity)
While it may be beyond the scope of a student research project to address all of these considerations, I do think it is important that we start thinking about these more in our research practices. As social work researchers, we should be modeling empowerment practices in the field of social science research, but we often fail to meet this standard.
Example. A community advisory group can be a tremendous asset throughout our research process, but especially in early stages of planning, including recruitment. I was fortunate enough to have a community advisory group for one of the projects I worked on. They were incredibly helpful as I considered different perspectives I needed to include in my study, helping me to think through a respectful way to approach recruitment, and how we might make the research arrangement a bit more reciprocal so community members might benefit as well.
Intersectional identity
As qualitative researchers, we are often not looking to prove a hypothesis or uncover facts. Instead, we are generally seeking to expand our understanding of the breadth and depth of human experience. Breadth is reflected as we seek to uncover variation across participants and depth captures variation or detail within each participants' story. Both are important for generating the fullest picture possible for our findings. For example, we might be interested in learning about people's experience living in an assisted living facility by interviewing residents. We would want to capture a range of different residents' experiences (breadth) and for each resident, we would seek as much detail as possible (depth). Do note, sometimes our research may only involve one person, such as in a case study. However, in these instances we are usually trying to understand many aspects or dimensions of that single case.
To capture this breadth and depth we need to remember that people are made of multiple stories formed by intersectional identities. This means that our participants never just represent one homogeneous social group. We need to consider the various aspects of our population that will help to give the most complete representation in our sample as we go about recruitment.
Exercises
Identify a population you are interested in studying. This might be a population you are working with at your field placement (either directly or indirectly), a group you are especially interested in learning more about, or a community you want to serve in the future. As you formulate your question, you may draw your sample directly from clients that are being served, others in their support network, service providers that are providing services, or other stakeholders that might be invested in the well-being of this group or community. Below, list out two populations you are interested in studying and then for each one, think about two groups connected with this population that you might focus your study on.
| Population | Group |
| 1. | 1a. |
| 1b. | |
| 2. | 2a. |
| 2b. |
Next, think about what would kind of information might help you understand this group better. If you had the chance to sit down and talk with them, what kinds of things would you want to ask? What kinds of things would help you understand their perspective or their worldview more clearly? What kinds of things do we need to learn from them and their experiences that could help us to be better social workers? For each of the groups you identified above, write out something you would like to learn from their experience.
| Population | Group | What I would like to learn from their experience |
| 1 | 1a. | 1a. |
| 1b. | 1b. | |
| 2. | 2a. | 2a. |
| 2b. | 2b. |
Finally, consider how this group might perceive a request to participate. For the populations and the groups that you have identified, think about the following questions:
- How have these groups been represented in the news?
- How have these groups been represented in popular culture and popular media?
- What historical or contemporary factors might influence these group members' opinions of research and researchers?
- In what ways have these groups been oppressed and how might research or academic institutions have contributed to this oppression?
Our impact on the qualitative process
It is important for qualitative research to thoughtfully plan for and attempt to capture our own impact on the research process. This influence that we can have on the research process represents what is known as researcher bias. This requires that we consider how we, as human beings, influence the research we conduct. This starts at the very beginning of the research process, including how we go about sampling. Our choices throughout the research process are driven by our unique values, experiences, and existing knowledge of how the world works. To help capture this contribution, qualitative researchers may plan to use tools like a reflexive journal, which is a research journal that helps the researcher to reflect on and consider their thoughts and reactions to the research process and how these may influence or shape a study (there will be more about this tool in Chapter 20 when we discuss the concept of rigor). While this tool is not specific to the sampling process, the next few chapters will suggest reflexive journal questions to help you think through how it might be used as you develop a qualitative proposal.
Example. To help demonstrate the potential for researcher bias, consider a number of students that I work with who are placed in school systems for their field experience and choose to focus their research proposal in this area. Some are interested in understanding why parents or guardians aren't more involved in their children's educational experience. While this might be an interesting topic, I would encourage students to consider what kind of biases they might have around this issue.
- What expectations do they have about parenting?
- What values do they attach to education and how it should be supported in the home?
- How has their own upbringing shaped their expectations?
- What do they know about the families that the school district serves and how did they come by this information?
- How are these families' life experiences different from their own?
The answers to these questions may unconsciously shape the early design of the study, including the research question they ask and the sources of data they seek out. For instance, their study may only focus on the behaviors and the inclinations of the families, but do little to investigate the role that the school plays in engagement and other structural barriers that might exist (e.g. language, stigma, accessibility, child-care, financial constraints, etc.).
Key Takeaways
- As researchers, we wield (sometimes subtle) power and we need to be conscientious of how we use and distribute this power.
- Qualitative study findings represent complex human experiences. As good as we may be, we are only going to capture a relatively small window into these experiences (and need to be mindful of this when discussing our findings).
Exercises
In the early stages of your research process, it is a good idea to start your reflexive journal. Starting a reflexive journal is as easy as opening up a new word document, titling it and chronologically dating your entries. If you are more tactile-oriented, you can also keep your reflexive journal in paper bound journal.
To prompt your initial entry, put your thoughts down in response to the following questions:
- What led you to be interested in this topic?
- What experience(s) do you have in this area?
- What knowledge do you have about this issue and how did you come by this knowledge?
- In what ways might you be biased about this topic?
Don't answer this last question too hastily! Our initial reaction is often—"Biased!?! Me—I don't have a biased bone in my body! I have an open-mind about everything, toward everyone!" After all, much of our social work training directs us towards acceptance and working to understand the perspectives of others. However, WE ALL HAVE BIASES. These are conscious or subconscious preferences that lead us to favor some things over others. These preferences influence the choices we make throughout the research process. The reflexive journal helps us to reflect on these preferences, where they might stem from, and how they might be influencing our research process. For instance, I conduct research in the area of mental health. Before I became a researcher, I was a mental health clinician, and my years as a mental health practitioner created biases for me that influence my approach to research. For instance, I may be biased in perceiving mental health services as being well-intentioned and helpful. However, participants may well have very different perceptions based on their experiences or beliefs (or those of their loved ones).
17.3 Finding the right qualitative data to answer my research question
Learning Objectives
Learners will be able to...
- Compare different types of qualitative data
- Begin to formulate decisions as they build their qualitative research proposal, specially in regards to selecting types of data that can effectively answer their research question
Sampling starts with deciding on the type of data you will be using. Qualitative research may use data from a variety of sources. Sources of qualitative data may come frominterviews or focus groups, observations, a review of written documents, administrative data, or other forms of media, and performances. While some qualitative studies rely solely on one source of data, others incorporate a variety.
You should now be well acquainted with the term triangulation. When thinking about triangulation in qualitative research, we are often referring to our use of multiple sources of data among those listed above to help strengthen the confidence we have in our findings. Drawing on a journalism metaphor, this allows us to "fact check" our data to help ensure that we are getting the story correct. This can mean that we use one type of data (like interviews), but we intentionally plan to get a diverse range of perspectives from people we know will see things differently. In this case we are using triangulation of perspectives. In addition, we may also you a variety of different types of data, like including interviews, data from case records, and staff meeting minutes all as data sources in the same study. This reflects triangulation through types of data.
As a student conducting research, you may not always have access to vulnerable groups or communities in need, or it may be unreasonable for you to collect data from them directly due to time, resource, or knowledge constraints. Because of this, as you are reviewing the sections below, think about accessible alternative sources of data that will still allow you to answer your research question practically, and I will provide some examples along the way to get you started. In the above example, local media coverage might be a means of obtaining data that does not involve vulnerable directly collecting data from potentially vulnerable participants.

Verbal data
Perhaps the bread and butter of the qualitative researcher, we often rely on what people tell us as a primary source of information for qualitative studies in the form of verbal data. The researcher who schedules interviews with recipients of public assistance to capture their experience after legislation drastically changes requirements for benefits relies on the communication between the researcher and the impacted recipients of public assistance. Focus groups are another frequently used method of gathering verbal data. Focus groups bring together a group of participants to discuss their unique perspectives and explore commonalities on a given topic. One such example is a researcher who brings together a group of child welfare workers who have been in the field for one to two years to ask them questions regarding their preparation, experiences, and perceptions regarding their work.
A benefit of utilizing verbal data is that it offers an opportunity for researchers to hear directly from participants about their experiences, opinions, or understanding of a given topic. Of course, this requires that participants be willing to share this information with a researcher and that the information shared is genuine. If groups of participants are unwilling to participate in sharing verbal data or if participants share information that somehow misrepresents their feelings (perhaps because they feel intimidated by the research process), then our qualitative sample can become biased and lead to inaccurate or partially accurate findings.
As noted above, participant willingness and honesty can present challenges for qualitative researchers. You may face similar challenges as a student gathering verbal data directly from participants who have been personally affected by your research topic. Because of this, you might want to gather verbal data from other sources. Many of the students I work with are placed in schools. It is not feasible for them to interview the youth they work with directly, so frequently they will interview other professionals in the school, such as teachers, counselors, administration, and other staff. You might also consider interviewing other social work students about their perceptions or experiences working with a particular group.
Again, because it may be problematic or unrealistic for you to obtain verbal data directly from vulnerable groups as a student researcher, you might consider gathering verbal data from the following sources:
- Interviews and focus groups with providers, social work students, faculty, the general public, administrators, local politicians, advocacy groups
- Public blogs of people invested in your topic
- Publicly available transcripts from interviews with experts in the area or people reporting experiences in popular media
Make sure to consult with your professor to ensure that what you are planning will be realistic for the purposes of your study.

Observational data
As researchers, we sometimes rely on our own powers of observation to gather data on a particular topic. We may observe a person’s behavior, an interaction, setting, context, and maybe even our own reactions to what we are observing (i.e. what we are thinking or feeling). When observational data is used for quantitative purposes, it involves a count, such as how many times a certain behavior occurs for a child in a classroom. However, when observational data is used for qualitative purposes, it involves the researcher providing a detailed description. For instance, a qualitative researcher may conduct observations of how mothers and children interact in child and adolescent cancer units, and take notes about where exchanges take place, topics of conversation, nonverbal information, and data about the setting itself – what the unit looks like, how it is arranged, the lighting, photos on the wall, etc.
Observational data can provide important contextual information that may not be captured when we rely solely on verbal data. However, using this form of data requires us, as researchers, to correctly observe and interpret what is going on. As we don’t have direct access to what participants may be thinking or feeling to aid us (which can lead us to misinterpret or create a biased representation of what we are observing), our take on this situation may vary drastically from that of another person observing the same thing. For instance, if we observe two people talking and one begins crying, how do we know if these are tears of joy or sorrow? When you observe someone being abrupt in a conversation, I might interpret that as the person being rude while you might perceive that the person is distracted or preoccupied with something. The point is, we can't know for sure. Perhaps one of the most challenging aspects of gathering observational data is collecting neutral, objective observations, that are not laden with our subjective value judgments placed on them. Students often find this out in class during one of our activities. For this activity, they have to go out to public space and write down observations about what they observe. When they bring them back to class and we start discussing them together, we quickly realize how often we make (unfounded) judgments. Frequent examples from our class include determining the race/ethnicity of people they observe or the relationships between people, without any confirmational knowledge. Additionally, they often describe scenarios with adverbs and adjectives that often reflect judgments and values they are placing on their data. I'm not sharing this to call them out, in fact, they do a great job with the assignment. I just want to demonstrate that as human beings, we are often less objective than we think we are! These are great examples of research bias.
Again, gaining access to observational spaces, especially private ones, might be a challenge for you as a student. As such, you might consider if observing public spaces might be an option. If you do opt for this, make sure you are not violating anyone's right to privacy. For instance, gathering information in a narcotics anonymous meeting or a religious celebration might be perceived as offensive, invasive or in direct opposition to values (like anonymity) of participants. When making observations in public spaces be careful not to gather any information that might identify specific individuals or organizations. Also, it is important to consider the influence your presence may have on a community, particularly if your observation makes you stand out among those typically present in that setting. Always consider the needs of the individual and the communities in formulating a plan for observing public behavior. Public spaces might include commercial spaces or events open to the public as well as municipal parks. Below we will have an expanded discussion about different varieties of non-probability sampling strategies that apply to qualitative research. Recruiting in public spaces like these may work for strategies such as convenience sampling or quota sampling, but would not be a good choice for snowball sampling or purposive sampling.
As with the cautionary note for student researchers under verbal data, you may experience restricted access to spaces in which you are able to gather observational data. However, if you do determine that observational data might be a good fit for your student proposal, you might consider the following spaces:
- Shopping malls
- Public parks or beaches
- Public meetings or rallies
- Public transportation
Artifacts (documents & other media)
Existing artifacts can also be very useful for the qualitative researcher. Examples include newspapers, blogs, websites, podcasts, television shows, movies, pictures, video recordings, artwork, and live performances. While many of these sources may provide indirect information on a topic, this information can still be quite valuable in capturing the sentiment of popular culture and thereby help researchers enhance their understanding of (dominant) societal values and opinions. Conversely, researchers can intentionally choose to seek out divergent, unique or controversial perspectives by searching for artifacts that tend to take up positions that differ from the mainstream, such as independent publications and (electronic) newsletters. While we will explore this further below, it is important to understand that data and research, in all its forms, is political. Among many other purposes, it is used to create, critique, and change policy; to engage in activism; to support and refute how organizations function; and to sway public opinion.
When utilizing documents and other media as artifacts, researchers may choose to use an entire source (such as a book or movie), or they may use a segment or portion of that artifact (such as the front-page stories from newspapers, or specific scenes in a television series). Your choice of which artifacts you choose to include will be driven by your question, and remember, you want your sample of artifacts to reflect the diversity of perspectives that may exist in the population you are interested in. For instance, perhaps I am interested in studying how various forms of media portray substance use treatment. I might intentionally include a range of liberal to conservative views that are portrayed across a number of media sources.
As qualitative researchers using artifacts, we often need to do some digging to understand the context of said artifact. We do this because data is almost always affiliated or aligned with some position (again, data is political). To help us consider this, it may be helpful to reflect on the following questions:
- Who owns the artifact or where is it housed
- What values does the owner (organization or person) hold
- How might the position or identity of the owner influence what information is shared or how it is portrayed
- What is the purpose of the artifact
- Who is the audience for which the artifact is intended
Answers to questions such as these can help us to better understand and give meaning to the content of the artifacts. Content is the substance of the artifact (e.g. the words, picture, scene). While context is the circumstances surrounding content. Both work together to help provide meaning, and further understanding of what can be derived from an artifact. As an example to illustrate this point, let's say that you are including meeting minutes from an organizing network as a source of data for your study. The narrative description in these minutes will certainly be important, however, they may not tell the whole story. For instance, you might not know from the text that the organization has recently voted in a new president and this has created significant division within the network. Knowing this information might help you to interpret the agenda and the discussion contained in the minutes very differently.
As student researchers, using documents and other artifacts may be a particularly appealing source of data for your study. This is because this data already exists (you aren't creating new data) and depending on what you select, it might be relatively easy to access. Examples of utilizing existing artifacts might include studying the cultural context of movie portrayals of Latinx families or analyzing publicly available town hall meeting minutes to explore expressions of social capital. Below is a list of sources of data from documents or other media sources to consider for your student proposal:
- Movies or TV shows
- Music or music videos
- Public blogs
- Policies or other organizational documents
- Meeting minutes
- Comments in online forums
- Books, newspapers, magazines, or other print/virtual text-based materials
- Recruitment, training, or educational materials
- Musical or artistic expressions
Photovoice
Finally, Photovoice is a technique that merges pictures with narrative (word or voice) data that helps interpret the meaning or significance of the visual. Photovoice is often used for qualitative work that is conducted as part of Community Based Participatory Research (CBPR), wherein community members act as both participants and as co-researchers. These community members are provided with a means of capturing images that reflect their understanding of some topic, prompt or question, and then they are asked to provide a narrative description or interpretation to help give meaning to the image(s). Both the visual and narrative information are used as qualitative data to include in the study. Dissemination of Photovoice projects often involve a public display of the works, such as through a demonstration or art exhibition to raise awareness or to produce some specific change that is desired by participants. Because this form of study is often intentionally persuasive in nature, we need to recognize that this form of data will be inherently subjective. As a student, it may be particularly challenging to implement a Photovoice project, especially due to its time-intensive nature, as well as the additional commitments of needing to engage, train, and collaborate with community partners.
| Type of Data | Potential Sources of Student Data | Some Potential Strengths and Challenges with this Type of Data |
| Verbal |
|
Strengths
Challenges
|
| Type of Data | Potential Sources of Student Data | Some Potential Strengths and Challenges with this Type of Data |
| Observational | Observations in:
|
Strengths
Challenges
|
| Type of Data | Potential Sources of Student Data | Some Potential Strengths and Challenges with this Type of Data |
| Documents & Other Media |
|
Strengths
Challenges
|
How many kinds of data?
You will need to consider whether you will rely on one kind of data or multiple. While many qualitative studies solely use one type of data, such as interviews or focus groups, others may use multiple sources. The decision to use multiple sources is often made to help strengthen the confidence we have in our findings or to help us to produce a richer, more detailed description of our results. For instance, if we are conducting a case study of what the family experience is for a child with a very rare disorder like Batten Disease, we may use multiple sources of data. These can include observing family and community interactions, conducting interviews with family members and others connected to the family (such as service providers,) and examining journal entries families were asked to keep over the course of the study. By collecting data from a variety of sources such as this, we can more broadly represent a range of perspectives when answering our research question, which will hopefully provide a more holistic picture of the family experience. However, if we are trying to examine the decision-making processes of adult protective workers, it may make the most sense to rely on just one type of data, such as interviews with adult protective workers.
Key Takeaways
- There are numerous types of qualitative data (verbal, observational, artifacts) that we may be able to access when planning a qualitative study. As we plan, we need to consider the strengths and challenges that each possess and how well each type might answer our research question.
- The use of multiple types of qualitative data does add complexity to a study, but this complication may well be worth it to help us explore multiple dimensions of our topic and thereby enrich our findings.
Exercises
Reflexive Journal Entry Prompt
For your next entry, consider responding to the following:
- What types of data appeal to you?
- Why do you think you are drawn to them?
- How well does this type of data "fit" as a means of answering your question? Why?
17.4 How to gather a qualitative sample
Learning Objectives
Learners will be able to...
- Compare and contrast various non-probability sampling approaches
- Select a sampling strategy that ideologically fits the research question and is practical/actionable
Before we launch into how to plan our sample, I'm going to take a brief moment to remind us of the philosophical basis surrounding the purpose of qualitative research—not to punish you, but because it has important implications for sampling.
Nomothetic vs. idiographic
As a quick reminder, as we discussed in Chapter 8 idiographic research aims to develop a rich or deep understanding of the individual or the few. The focus is on capturing the uniqueness of a smaller sample in a comprehensive manner. For example, an idiographic study might be a good approach for a case study examining the experiences of a transgender youth and her family living in a rural Midwestern state. Data for this idiographic study would be collected from a range of sources, including interviews with family members, observations of family interactions at home and in the community, a focus group with the youth and her friend group, another focus group with the mother and her social network, etc. The aim would be to gain a very holistic picture of this family's experiences.
On the other hand, nomothetic research is invested in trying to uncover what is ‘true’ for many. It seeks to develop a general understanding of a very specific relationship between variables. The aim is to produce generalizable findings, or findings that apply to a large group of people. This is done by gathering a large sample and looking at a limited or restricted number of aspects. A nomothetic study might involve a national survey of heath care providers in which thousands of providers are surveyed regarding their current knowledge and competence in treating transgender individuals. It would gather data from a very large number of people, and attempt to highlight some general findings across this population on a very focused topic.
Idiographic and nomothetic research represent two different research categories existing at opposite extremes on a continuum. Qualitative research generally exists on the idiographic end of this continuum. We are most often seeking to obtain a rich, deep, detailed understanding from a relatively small group of people.
Non-probability sampling
Non-probability sampling refers to sampling techniques for which a person’s (or event’s) likelihood of being selected for membership in the sample is unknown. Because we don’t know the likelihood of selection, we don’t know whether a sample represents a larger population or not. But that’s okay, because representing the population is not the goal of nonprobability samples. That said, the fact that nonprobability samples do not represent a larger population does not mean that they are drawn arbitrarily or without any specific purpose in mind. We typically use nonprobability samples in research projects that are qualitative in nature. We will examine several types of nonprobability samples. These include purposive samples, snowball samples, quota samples, and convenience samples.
Convenience or availability
Convenience sampling, also known as availability sampling, is a nonprobability sampling strategy that is employed by both qualitative and quantitative researchers. To draw a convenience sample, we would simply collect data from those people or other relevant elements to which we have the most convenient access. While convenience samples offer one major benefit—convenience—we should be cautious about generalizing from research that relies on convenience samples because we have no confidence that the sample is representative of a broader population. If you are a social work student who needs to conduct a research project at your field placement setting and you decide to conduct a focus group with the staff at your agency, you are using a convenience sampling approach – you are recruiting participants that are easily accessible to you. In addition, if you elect to analyze existing data that your social work program has collected as part of their graduation exit surveys, you are using data that you readily have access to for your project; again, you have a convenience sample. The vast majority of students I work with on their proposal design rely on convenience data due to time constraints and limited resources.
Purposive
To draw a purposive sample, we begin with specific perspectives or purposive criteria in mind that we want to examine. We would then seek out research participants who cover that full range of perspectives. For example, if you are studying mental health supports on your campus, you may want to be sure to include not only students, but mental health practitioners and student affairs administrators as well. You might also select students who currently use mental health supports, those who dropped out of supports, and those who are waiting to receive supports. The "purposive" part of purposive sampling comes from selecting specific participants on purpose because you already know they have certain characteristics—being an administrator, dropping out of mental health supports, for example—that you need in your sample.
Note that these differ from inclusion criteria, which are more general requirements a person must possess to be a part of your sample; to be a potential participant that may or may not be sampled. For example, one of the inclusion criteria for a study of your campus’ mental health supports might be that participants had to have visited the mental health center in the past year. That differs from purposive sampling. In purposive sampling, you know characteristics of individuals and recruit them because of those characteristics. For example, I might recruit Jane because she stopped seeking supports this month, because she has worked at the center for many years, and so forth.
Also, it’s important to recognize that purposive sampling requires you to have prior information about your participants before recruiting them because you need to know their perspectives or experiences before you know whether you want them in your sample. This is a common mistake that many students make. What I often hear is, “I’m using purposive sampling because I’m recruiting people from the health center,” or something like that. That’s not purposive sampling. In most instances they really mean they are going to use convenience sampling-taking whoever they can recruit that fit the inclusion criteria (i.e. have attended the mental health center). Purposive sampling is recruiting specific people because of the various characteristics and perspectives they bring to your sample. Imagine we were creating a focus group. A purposive sample might gather clinicians, patients, administrators, staff, and former patients together so they can talk as a group. Purposive sampling would seek out people that have each of those attributes.
If you are considering using a purposive sampling approach for your research proposal, you will need to determine what your purposive criteria involves. There are a range of different purposive strategies that might be employed, including: maximum variation, typical case, extreme case, or political case, and you want to be thoughtful in thinking about which one(s) you select and why.
| Purposive Strategy | Description | Student Example |
| Maximum Variation | Case(s) selected to represent a range of very different perspectives on a topic | You interview student leaders from the schools of social work, business, the arts, math & science, education, history & anthropology and health studies to ensure that you have the perspective of a variety of disciplines |
| Typical Case | Case(s) selected to reflect a commonly held perspective. | You interview a child welfare worker specifically because many of their characteristics fit the state statistical profile for providers in that service area. |
| Extreme Case | Case(s) selected to represent extreme or underrepresented perspectives. | You examine websites devoted to rare cancer survivor support. |
| Political Case | Case(s) selected to represent a contemporary politicized issue | You analyze media interviews with Planned Parenthood providers, employees, and clients from 2010 to present. |
| Expert Case | Case(s) selected based on specialized content knowledge or expertise | You are interested in studying resilience in trauma providers, so you research and reach out to a handful of authorities in this area. |
| Theory-Based Case | Case(s) selected based on their representation of a specific theoretical orientation or some aspect of a given theory | You are interested in studying how training methods vary by practitioner according to their theoretical orientation. You specifically reach out to a clinician who identifies as a Cognitive Behavioral clinician, one who identifies as Bowenian, and one who identifies as Structural Family. |
| Critical Case | Case(s) selected based on the likelihood that the case will yield the desired information | You examine a public gaming network forum on social media to see how participants offer support to one another. |
It can be a bit tricky determining how to approach or formulate your purposive cases. Below are a couple additional resources to explore this strategy further.
For more information on purposive sampling consult this webpage from Laerd Statistics on purposive sampling and this webpage from the University of Connecticut on education research.

Snowball
When using snowball sampling, we might know one or two people we’d like to include in our study but then we have to rely on those initial participants to help identify additional participants. Thus, our sample builds and grows as the study continues, much as a snowball builds and becomes larger as it rolls through the snow. Snowball sampling is an especially useful strategy when you wish to study a stigmatized group or behavior. These groups may have limited visibility and accessibility for a variety of reasons, including safety.
Malebranche and colleagues (2010)[29] were interested in studying sexual health behaviors of Black, bisexual men. Anticipating that this may be a challenging group to recruit, they utilized a snowball sampling approach. They recruited initial contacts through activities such as advertising on websites and distributing fliers strategically (e.g. barbershops, nightclubs). These initial recruits were compensated with $50 and received study information sheets and five contact cards to distribute to people in their social network that fit the study criteria. Eventually the research team was able to recruit a sample of 38 men who fit the study criteria.
Snowball sampling may present some ethical quandaries for us. Since we are essentially relying on others to help advertise for us, we are giving up some of our control over the process of recruitment. We may be worried about coercion, or having people put undue pressure to have others' they know participate in your study. To help mitigate this, we would want to make sure that any participant we recruit understands that participation is completely voluntary and if they tell others about the studies, they should also make them aware that it is voluntary, too. In addition to coercion, we also want to make sure that people's privacy is not violated when we take this approach. For this reason, it is good practice when using a snowball approach to provide people with our contact information as the researchers and ask that they get in touch with us, rather than the other way around. This may also help to protect again potential feelings of exploitation or feeling taken advantage of. Because we often turn to snowball sampling when our population is difficult to reach or engage, we need to be especially sensitive to why this is. It is often because they have been exploited in the past and participating in research may feel like an extension of this. To address this, we need to have a very clear and transparent informed consent process and to also think about how we can use or research to benefit the people we work in the most meaningful and tangible ways.
Quota
Quota sampling is another nonprobability sampling strategy. This type of sampling is actually employed by both qualitative and quantitative researchers, but because it is a nonprobability method, we’ll discuss it in this section. When conducting quota sampling, we identify categories that are important to our study and for which there is likely to be some variation. Subgroups are created based on each category and the researcher decides how many people (or whatever element happens to be the focus of the research) to include from each subgroup and collects data from that number for each subgroup. To demonstrate, perhaps we are interested in studying support needs for children in the foster care system. We decide that we want to examine equal numbers (seven each) of children placed in a kinship placement, a non-kinship foster placement, group home, and residential placements. We expect that the experiences and needs across these settings may differ significantly, so we want to have good representation of each one, thus setting a quota of seven for each type of placement.
| Sampling Type | Brief Description |
| Convenience/ Availability | You gather data from whatever cases/people/documents happen to be convenient |
| Purposive | You seek out elements that meet specific criteria, representing different perspectives |
| Snowball | You rely on participant referrals to recruit new participants |
| Quota | You select a designated number of cases from specified subgroups |
As you continue to plan for your proposal, below you will find some of the strengths and challenges presented by each of these types of sampling.
| Sampling Type | Strengths | Challenges |
| Convenience/ Availability | Allows us to draw sample from participants who are most readily available/accessible | Sample may be biased and may represent limited or skewed diversity in characteristics of participants |
| Purposive | Ensures that specific expertise, positions, or experiences are represented in sample participants | It may be challenging to define purposive criteria or to locate cases that represent these criteria; restricts our potential sampling pool |
| Snowball | Accesses participant social network and community knowledge
Can be helpful in gaining access to difficult to reach populations |
May be hard to locate initial small group of participants, concerns over privacy—people might not want to share contacts, process may be slow or drawn-out |
| Quota | Helps to ensure specific characteristics are represented and defines quantity of each | Can be challenging to fill quotas, especially for subgroups that might be more difficult to locate or reluctant to participate |
Wait a minute, we need a plan!
Both qualitative and quantitative research should be planful and systematic. We've actually covered a lot of ground already and before we get any further, we need to start thinking about what the plan for your qualitative research proposal will look like. This means that as you develop your research proposal, you need to consider what you will be doing each step of the way: how you will find data, how you will capture it, how you will organize it, and how you will store it. If you have multiple types of data, you need to have a plan in place for each type. The plan that you develop is your data collection protocol. If you have a team of researchers (or are part of a research team), the data collection protocol is an important communication tool, making sure that everyone is clear what is going on as the research proceeds. This plan is important to help keep you and others involved in your research consistent and accountable. Throughout this chapter and the next (Chapter 18—qualitative data gathering) we will walk through points you will want to include in your data collection protocol. While I've spent a fair amount of time talking about the importance of having a plan here, qualitative design often does embrace some degree of flexibility. This flexibility is related to the concept of emergent design that we find in qualitative studies. Emergent design is the idea that some decision in our design will be dynamic and fluid as our understanding of the research question evolves. The more we learn about the topic, the more we want to understand it thoroughly.
Exercises
A research protocol is a document that not only defines your research project and its aims, but also comprehensively plans how you will carry it out. If this sounds like the function of a research proposal, you are right, they are similar. What differentiates a protocol from a proposal is the level of detail. A proposal is more conceptual; a protocol is more practical (right down to the dollars and cents!). A protocol offers explicit instructions for you and your research team, any funders that may be involved in your research, and any oversight bodies that might be responsible for overseeing your study. Not every study requires a research protocol, but what I'm suggesting here is that you consider constructing at least a limited one to help though the decisions you will need to make to construct your qualitative study.
Al-Jundi and Sakka (2016)[30] provide the following elements for a research protocol:
- What is the question? (Hypothesis) What is to be investigated?
- Why is the study important (Significance)
- Where and when will it take place?
- What is the methodology? (Procedures and methods to be used).
- How are you going to implement it? (Research design)
- What is the proposed time table and budget?
- What are the resources required (technical, scientific, and financial)?
While your research proposal in its entirety will focus on many of these areas, our attention for developing your qualitative research protocol will hone in on the two highlighted above. As we go through these next couple chapters, there will be a number of exercises that walk you though decision points that will form your qualitative research protocol.
To begin developing your qualitative research protocol:
- Select the question you have decided is the best to frame your research proposal.
- Write a brief paragraph about the aim of your study, ending it with the research question you have selected.
Here are a few additional resources on developing a research protocol:
Cameli et al., (2018) How to write a research protocol: Tips and tricks.
Ohio State University, Institutional Review Board (n.d.). Research protocol.
World Health Organization (n.d.). Recommended format for a research protocol.
Exercises
Decision Point: What types of data will you be using?
- After having considered the different types of data that have been reviewed here, what type(s) are you planning on using?
- Why is this a good choice, given your research question?
- Are you thinking about using more than one type?
- If so, provide support for this decision.
Exercises
Decision Point: Which non-probability sampling strategy will you employ?
- Thinking about the four non-probability sampling strategies we reviewed, which one makes the most sense for your proposal?
- Why is this is a good fit?
- What challenges or limitations does this present for your study?
- What steps might your take to address these challenges?
Recruiting strategies
Much like quantitative research, recruitment for qualitative studies can take many different approaches. When considering how to draw your qualitative sample, it may be helpful to first consider which of these three general strategies will best fit your research question and general study design: public, targeted, or membership-based. While all will lead to a sample, the process for getting you there will look very different, depending on the strategy you select.
Public
Taking a public approach to recruitment offers you access to the broadest swath of potential participants. With this approach, you are taking advantage of public spaces in an attempt to gain the attention of the general population of people that frequent that space so that they can learn about your study. These spaces can be in-person (e.g. libraries, coffee shops, grocery stores, health care settings, parks) or virtual (e.g. open chat forums, e-bulletin boards, news feeds). Furthermore, a public approach can be static (such as hanging a flier), or dynamic (such as talking to people and directly making requests to participate). While a public approach may offer broad coverage in that it attempts to appeal to an array of people, it may be perceived as impersonal or easily able to be overlooked, due to the potential presence of other announcements that may be featured in public spaces. Public recruitment is most likely to be associated with convenience or quota sampling and is unlikely to be used with purposive or snowball sampling, where we would need some advance knowledge of people and the characteristics they possess.

Targeted
As an alternative, you may elect to take a targeted approach to recruitment. By targeting a select group, you are restricting your sampling frame to those individuals or groups who are potentially most well-suited to answer your research question. Additionally, you may be targeting specific people to help craft a diverse sample, particularly with respect to personal characteristics and/or opinions.
You can target your recruitment through the use of different strategies. First, you might consider the use of knowledgeable and well-connected community members. These are people who may possess a good amount of social capital in their community, which can aid in recruitment efforts. If you are considering the use of community members in this role, make sure to be thoughtful in your approach, as you are essentially asking them to share some of their social capital with you. This means learning about the community or group, approaching community members with a sense of humility, and making sure to demonstrate transparency and authenticity in your interactions. These community members may also be champions for the topic you are researching. A champion is someone who helps to draw the interest of a particular group of people. The champion often comes from within the group itself. As an example, let's say you're interested in studying the experiences of family members who have a loved one struggling with substance use. To aid in your recruitment for this study, you enlist the help of a local person who does a lot of work with Al-Anon, an organization facilitating mutual support groups for individuals and families affected by alcoholism.
A targeted approach can certainly help ensure that we are talking to people who are knowledgeable about the topic we are interested in, however, we still need to be aware of the potential for bias. If we target our recruitment based on connection to a particular person, event, or passion for the topic, these folks may share information that they think is viewed as favorable or that disproportionately reflects a particular perspective. This phenomenon is due to the fact that we often spend time with people who are like-minded or share many of our views. A targeted approach may be helpful for any type of non-probability sampling, but can be especially useful for purposive, quota, or snowball sampling, where we are trying to access people or groups of people with specific characteristics or expertise.
Membership-based
Finally, you might consider a membership-based approach. This approach is really a form of targeted recruitment, but may benefit from some individual attention. When using a membership-based approach, your sampling frame is the membership list of a particular organization or group. As you might have guessed, this organization or group must be well-suited for helping to answer your research question. You will need permission to access membership, and the identity of the person authorized to grant permission will depend on the organizational structure. When contacting members regarding recruitment, you may consider using directories, newsletters, listservs or membership meetings. When utilizing a membership-based approach, we often know that members possess specific inclusion criteria we need, however, because they are all associated with that particular group or organization, they may be homogenous or like-minded in other ways. This may limit the diversity in our sample and is something to be mindful of when interpreting our findings. Membership-based recruiting can be helpful when we have a membership group that fulfills our inclusion criteria. For instance, if you want to conduct research with social workers, you might attempt to recruit through the NASW membership distribution list (but this access will come with stipulations and a price tag). Membership-based recruitment may be helpful for any non-probability sampling approach, given that the membership criteria and study inclusion criteria are a close fit. Table 17.5 offers some additional considerations for each of these strategies with examples to help demonstrate sources that might correspond with them.
| Recruitment Strategy | Strengths/Challenges | Example of Source for Recruitment |
| Public | Strengths: Easier to gain access; Exposure to large numbers of people
Challenges: Can be impersonal, Difficult to cultivate interest |
Advertising in public events & spaces
Accessing materials in local libraries or museums Finding public web-based resources and sources of data (websites, blogs, open forums)
|
| Targeted | Strengths: Prior knowledge of potential audience, More focused use of resources
Challenges: May be hard to locate/access target group(s), Groups may be suspicious of/or resistant to being targeted |
Working with advocacy group for issue you are studying to aid recruitment
Contacting local expert (historian) to help you locate relevant documents Advertising in places that your population may frequent
|
| Membership-Based | Strengths: Shared interest (through common membership), Potentially existing infrastructure for outreach
Challenges: Organization may be highly sensitive to protecting members, Members may be similar in perspectives and limit diversity of ideas |
Membership newsletters
Listserv or Facebook groups Advertising at membership meetings or events |
Key Takeaways
- Qualitative research predominately relies on non-probability sampling techniques. There are a number of these techniques to choose from (convenience/availability, purposive, snowball, quota), each with advantages and limitations to consider. As we consider these, we need to reflect on both our research question and the resources we have available to us in developing a sampling strategy.
- As we consider where and how we will recruit our sample, there are a range of general approaches, including public, targeted, and membership-based.
Exercises
Decision Point: How will you recruit or gain access to your sample?
- Now you've decided your data type and sampling strategy...
- If you are recruiting people, how will you identify them? If necessary (and it often is), how will gain permission to do this?
- If you are using documents or other artifacts for your study, how will you gain access to these? If necessary (and it often is), how will gain permission to do this?
17.5 What should my sample look like?
Learning Objectives
Learners will be able to...
- Explain key factors that influence the makeup of a qualitative sample
- Develop and critique a sampling strategy to support their qualitative proposal
Once you have started your recruitment, you also need to know when to stop. Knowing when to stop recruiting for a qualitative research study generally involves a dynamic and reflective process. This means that you will actively be involved in a process of recruiting, collecting data, beginning to review your preliminary data, and conducting more recruitment to gather more data. You will continue this process until you have gathered enough data and included sufficient perspectives to answer your research question in rich and meaningful way.
The sample size of qualitative studies can vary significantly. For instance, case studies may involve only one participant or event, while some studies may involve hundreds of interviews or even thousands of documents. Generally speaking, when compared to quantitative research, qualitative studies have a considerably smaller sample. Your decision regarding sample size should be guided by a few considerations, described below.
Amount of data
When gathering quantitative data, the amount of data we are gathering is often specified at the start (e.g. a fixed number of questions on a survey or a set number of indicators on a tracking form). However, when gathering qualitative data, we are often asking people to expand on and explore their thoughts and reactions to certain things. This can produce A LOT of data. If you have ever had to transcribe an interview (type out the conversation while listening to an audio recorded interview), you quickly learn that a 15-minute discussion turns into many pages of dialogue. As such, each interview or focus group you conduct represents multi-page transcripts, all of which becomes your data. If you are conducting interviews or focus groups, you will know you have collected enough data from each interaction when you have covered all your questions and allowed the participant(s) to share any and all ideas they have related to the topic. If you are using observational data, you need to spend sufficient time making observations and capturing data to offer a genuine and holistic representation of the thing you are observing (at least to the best of your ability). When using documents and other sources of media, again, you want to ensure that diverse perspectives are represented through your artifact choices so that your data reflects a well-rounded representation of the issue you are studying. For any of these data sources, this involves a judgment call on the researcher's part. Your judgment should be informed by what you have read in the existing literature and consultation with your professor.
As part of your analysis, you will likely eventually break these larger hunks of data apart into words or small phrases, giving you potentially thousands of pieces of data. If you are relying on documents or other artifacts, the amount of data contained in each of these pieces is determined in advance, as they already exist. However, you will need to determine how many to include. With interviews, focus groups, or other forms of data generation (e.g. taking pictures for a photovoice project), we don’t necessarily know how much data will be generated with each encounter, as it will depend on the questions that are asked, the information that is shared, and how well we capture it.
Type of study
A variety of types of qualitative studies will be discussed in greater detail in Chapter 22. While you don't necessarily need to have an extensive understanding of them all at this point in time, it is important that you understand which of the different design types are best for answering certain research questions. For instance, if our question involves understanding some type of experience, that is often best answered by a phenomenological design. Or, if we want to better understand some process, a grounded theory study may be best suited. While there are no hard and fast rules regarding qualitative sample size, each of these different types of designs has different guidelines for what is considered an acceptable or reasonable number to include in your sample. So drawing on the previous examples, your grounded theory study might include 45 participants because you need more people to gain a clearer picture of each step of the process, while your phenomenological study includes 20 because that provides a good representation of the experience you are interested in. Both would be reasonable targets based on the respective study design type. So as you consider your research question and which specific type of qualitative design this leads you to, you will need to do some investigation to see what size samples are recommended for that particular type of qualitative design.
Diversity of perspectives
As you consider your research question, you also may want to think about the potential variation in how your study population might view this topic. If you are conducting a case study of one person, this obviously isn’t a concern, but if you are interested in exploring a range of experiences, you want to plan to intentionally recruit so this level of diversity is reflected in your sample. The level of variation you seek will have direct implications for how big your sample might be. In the example provided above in the section on quota sampling, we wanted to ensure we had equal representation across a host of placement dispositions for children in foster care. This helped us define our target sample size: (4) settings a quota of (7) participants from each type of setting = a target sample size of (28).

In Chapter 18, we will be talking about different approaches to data gathering, which may help to dictate the range of perspectives you want to represent. For instance, if you conduct a focus group, you want all of your participants to have some experience with the thing that you are studying, but you hope that their perspectives differ from one another. Furthermore, you may want to avoid groups of participants who know each other well in the same focus group (if possible), as this may lead to groupthink or level of familiarity that doesn't really encourage differences being expressed. Ideally, we want to encourage a discussion where a variety of ideas are shared, offering a more complete understanding of how the topic is experienced. This is true in all forms of qualitative data, in that your findings are likely to be more well-rounded and offer a broader understanding fo the issue if you recruit a sample with diverse perspectives.
Saturation
Finally, the concept of saturation has important implications for both qualitative sample size and data analysis. To understand the idea of saturation, it is first important to understand that unlike most quantitative research, with qualitative research we often at least begin the process of data analysis while we are still actively collecting data. This is called an iterative approach to data analysis. So, if you are a qualitative researcher conducting interviews, you may be aiming to complete 30 interviews. After you have completed your first five interviews, you may begin reviewing and coding (a term that refers to labeling the different ideas found in your transcripts) these interviews while you are still conducting more interviews. You go on to review each new interview that you conduct and code it for the ideas that are reflected there. Eventually, you will reach a point where conducting more interviews isn’t producing any new ideas, and this is the point of saturation. Reaching saturation is an indication that we can stop data collection. This may come before or after you hit 30, but as you can see, it is driven by the presence of new ideas or concepts in your interviews, not a specific number.
This chapter represents our transition in the text to a focus on qualitative methods in research. Throughout this chapter we have explored a number of topics including various types of qualitative data, approaches to qualitative sampling, and some considerations for recruitment and sample composition. It bears repeating that your plan for sampling should be driven by a number of things: your research question, what is feasible for you, especially as a student researcher, best practices in qualitative research. Finally, in subsequent chapters, we will continue the discussion about reflexivity as it relates to the qualitative research process that we began here.
Key Takeaways
- The composition of our qualitative sample comes with some important decisions to consider, including how large should our sample be and what level and type of diversity it should reflect. These decisions are guided by the purposes or aims of our study, as well as access to resources and our population.
- The concept of saturation is important for qualitative research. It helps us to determine when we have sufficiently collected a range of perspectives on the topic we are studying.
Exercises
Decision Point(s): What should your sample look like (sample composition)?
- How will you determine you have gathered enough data?
- Will you start in advance with a set a number of data sources (people or artifacts)?
- If so, how many?
- How was this number determined?
- OR will you use the concept of saturation to determine when to stop?
- Will you start in advance with a set a number of data sources (people or artifacts)?
- How diverse should your sample be and in what ways?
- What supports your decision in regards to the previous question?
Exercises
This isn't so much a decision point, but a chance for you to reflect on the choices you've made thus far in your protocol with regards to your: (1) ethical responsibility, (2) commitment to cultural humility, and (3) respect for empowerment of individuals and groups as a social work researcher. Think about each of the decisions you've made thus far and work across this grid to identify any important considerations that you need to take into account.
| Decision Point | Ethical Responsibility | Cultural Humility | Empowerment |
| Research Question | |||
| Type of Data | |||
| Sampling Approach | |||
| Recruitment/ Access | |||
| Sample Composition |
Exercises
Reflexive Journal Entry Prompt
You have been prompted to make a number of choices regarding how you will proceed with gathering your qualitative sample. Based on what you have learned and what you are planning, respond to the following questions below.
- What are the strengths of your sampling plan in respect to being able to answer your qualitative research question?
- How feasible is it for you, as a student researcher, to be able to carry out your sampling plan?
- What reservations or questions do you still need to have answered to adequately plan for your sample?
- What excites you about your proposal thus far?
- What worries you about your proposal thus far?
