
10 Connecting conceptualization and measurement
Chapter Outline
- Measurement modeling (18-minute read)
- Construct validity (25-minute read)
- Postpositivism: The assumptions of quantitative methods (30-minute read)
Content warning: TBD.
10.1 Measurement modeling
Learning Objectives
Learners will be able to…
- Define measurement modeling and how it relates to conceptual and operational definitions
- Describe how operational definitions are impacted by power.
- Critique the validity and reliability of measurement models
With your variables operationalized, it’s time to take a step back and look at the assumptions underlying operational definitions and conceptual definitions in your project and how they rely upon broader assumptions underlying quantitative research methods. By making your assumptions explicit, you can ensure your conceptual definitions and operational definitions coalesce into a coherent measurement model. This chapter adapts the seminal work “Measurement and Fairness” by Jacobs & Wallach (2021) which defines measurement model is a statistical model that links unobservable theoretical constructs (i.e., conceptual definitions from Chapter 8) and observable properties a researcher measures (i.e., operational definitions from Chapter 9) within a sample or data set (Chapter 11, see section on sample quality) (Jackman, 2008).
As we discussed in Chapter 9, such constructs cannot be measured directly and must instead be inferred from measurements of observable properties. The measurement model refers to the assumptions that the indicators represent the deeper, unobservable theoretical constructs we are interested in studying. Like we mentioned in Chapter 9, if we are operationalizing the theoretical concept of masculinity, indicators for that concept might include some of the social roles or fashion choices prescribed to men in society. Of course, masculinity is a contested construct, and the extent to which indicators you measured are complete, unbiased, and reliable measurements of the theoretical construct of masculinity will impact the conclusions you can draw. Errors in measurement models are often where human subjects researchers and powerful systems who measure oppressed groups reinforce domination through social science. This chapter will help you understand the assumptions underlying the measurement models in quantitative research.
Latent variables
Left off here: https://www.ncrm.ac.uk/resources/online/all/?id=20835
I am loath to introduce another “variable” type here, as we have many (independent, dependent, control, moderating, mediating). But all of those variables, as we have operationally defined them, are distinct from their theoretical construct. For example, religiosity refers to how religious someone is. A reasonable indicator for a researcher to measure would be how often someone attends a place of worship, but this would exclude many people who consider themselves highly religious who cannot or do not care to attend services. In this simplistic measurement model, the latent variable, religiosity, is inherently unobservable (Jackman, 2008). Religiosity gets operationalized into a variable that can be measured, church attendance, and this level of abstraction adds another layer of assumptions that can introduce error and bias.
In the previous chapter, we discussed researchers use standardized scales to ensure that valid and reliable measurements of participants. Operationalizing anxiety using the GAD-7 Anxiety inventory is a good idea, but the latent variable of anxiety is distinct from the categories of clinically significant generalized anxiety from the GAD-7. But collapsing these distinctions makes it difficult to address any possible mismatches. When reading a research study, you should be able to see how the researcher’s conceptualization informed what indicators and measurements were used. Collapsing the distinction between conceptual definitions and operational definitions is when fairness-related harms are most often introduced into the scientific process.
Researchers measure what they can to infer broader patterns. Necessary compromises introduce mismatches between (a) the theoretical understanding of the construct purported to be measured and (b) its operationalization. Many of the harms in automated systems like algorithmic monitoring in child welfare, gunshot listening devices, and other real-world measurements are direct results of such mismatches, in addition to the harms perpetuated by human subjects researchers. Some of these harms could have been anticipated and, in some cases, mitigated if viewed through the lens of measurement modeling. To do this, Jacobs & Wallch (2022) introduced fairness-oriented conceptualizations of construct validity and construct reliability, described below.
In addition to the validity and reliability of specific measurement, we need to take a look at how validity and reliability impact the measurement model you’ve constructed for the causal relationships in your research question. How we measure things is both shaped by power arrangements inside our society, and more insidiously, by establishing what is scientifically true, measures have their own power to influence the world. Just like reification in the conceptual world, how we operationally define concepts can reinforce or fight against oppressive forces. The measurement modeling process necessarily involves making assumptions that must be made explicit and tested before the resulting measurements are used.
Measurement error models: Are your variables well-behaved?
Consider the process of measuring a person’s socioeconomic status (SES). From a theoretical perspective, a person’s SES is understood as encompassing their social and economic position in relation to others. Unlike a person’s height, their SES is unobservable, so it cannot be measured directly and must instead be inferred from measurements of observable properties thought to be related to it, such as income, wealth, education, and occupation.
We refer to the abstraction of SES as a construct S and then operationalize S as a latent variable s. Measurement error models are the assumptions the researcher makes about the errors in their measurements. In many contexts, it is reasonable to assume that variables are well-behaved in a measurement model. Meaning, researchers assume measurement error does not impact any variable too much, not in any particular direction, and with distributions that can be understood using normal parametric statistics. However, in some contexts, the measurement error may not behave like researcher expect and may even be correlated with demographic factors, such as race or gender. Systematic error or bias often reinforces existing power relationships in society.
The simplest way to measure a person’s SES is to use an observable property—like their income—as an indicator for it. Letting the construct I represent the abstraction of income and operationalizing I as a latent variable i, this means specifying a both measurement model that links s and i and a measurement error model. For example, if we assume that s and i are linked via the identity function—i.e., that s = i—and we assume that it is possible to obtain error-free measurements of a person’s income—i.e., that ˆi = i—then s = ˆi. Like the previous example, this example highlights that the measurement modeling process necessarily involves making assumptions. Indeed, there are many other measurement models that use income as a proxy for SES but make different assumptions about the specific relationship between them.
Similarly, there are many other measurement error models that make different assumptions about the errors that occur when measuring a person’s income. For example, if we measure a person’s monthly income by totaling the wages deposited into their account over a single one-month period, then we must use a measurement error model that accounts for the possibility that the timing of the one-month period and the timings of their wage deposits may not be aligned. We would also exclude non-wage income such as government benefits or child support. Using a measurement error model that does not account for this possibility—e.g., using ˆi = i—will yield inaccurate measurements.
Human Rights Watch reported exactly this scenario in the context of the Universal Credit benefits system in the U.K. [55]: The system measured a claimant’s monthly income using a one-month rolling period that began immediately after they submitted their claim without accounting for the possibility described above. This meant that the system “might detect that an individual received a £1000 paycheck on March 30 and another £1000 on April 29, but not that each £1000 salary is a monthly wage [leading it] to compute the individual’s benefit in May based on the incorrect assumption that their combined earnings for March and April (i.e., £2000) are their monthly wage,” denying them much-needed resources. Moving beyond income as a proxy for SES, there are arbitrarily many ways to operationalize SES via a measurement model, incorporating both measurements of observable properties, such as wealth, education, and occupation, as well as measurements of other unobservable theoretical constructs, such as cultural capital.
Measuring teacher effectiveness
At the end of every semester, students in just about every university classroom in the United States complete similar student evaluations of teaching (SETs). Since every student is likely familiar with these, we can recognize many of the concepts we discussed in the previous sections. There are number of rating scale questions that ask you to rate the professor, class, and teaching effectiveness on a scale of 1-5. Scores are averaged across students and used to determine the quality of teaching delivered by the faculty member. SETs scores are often a principle component of how faculty are reappointed to teaching positions. Would it surprise you to learn that student evaluations of teaching are of questionable quality? If your instructors are assessed with a biased or incomplete measure, how might that impact your education?
Distribution of responses
Most often, student scores are averaged across questions and reported as a final average. This average is used as one factor, often the most important factor, in a faculty member’s reappointment to teaching roles. We learned in the previous chapter that rating scales are ordinal, not interval or ratio, and the data are categories not numbers. Although rating scales use a familiar 1-5 scale, the numbers 1, 2, 3, 4, & 5 are really just helpful labels for categories like “excellent” or “strongly agree.” If we relabeled these categories as letters (A-E) rather than as numbers (1-5), how would you average them?
Averaging ordinal data is methodologically dubious, as the numbers are merely a useful convention. As you will learn in Part 4, taking the median value is what makes the most sense with ordinal data. Median values are also less sensitive to outliers. So, a single student who has strong negative or positive feelings towards the professor could bias the class’s SETs scores higher or lower than what the “average” student in the class would say, particularly for classes with few students or in which fewer students completed evaluations of their teachers.
Unclear latent variable
Even though student evaluations of teaching often contain dozens of questions, researchers often find that the questions are so highly interrelated that one concept (or factor, as it is called in a factor analysis) explains a large portion of the variance in teachers’ scores on student evaluations (Clayson, 2018).[1] Personally, I believe based on completing SETs myself that factor is probably best conceptualized as student satisfaction, which is obviously worthwhile to measure, but is conceptually quite different from teaching effectiveness or whether a course achieved its intended outcomes. The lack of a clear operational and conceptual definition for the variable or variables being measured in student evaluations of teaching also speaks to a lack of content validity. Researchers check content validity by comparing the measurement method with the conceptual definition, but without a clear conceptual definition of the concept measured by student evaluations of teaching, it’s not clear how we can know our measure is valid. Indeed, the lack of clarity around what is being measured in teaching evaluations impairs students’ ability to provide reliable and valid evaluations. So, while many researchers argue that the class average SETs scores are reliable in that they are consistent over time and across classes, it is unclear what exactly is being measured even if it is consistent (Clayson, 2018).[2]

Measurement error model for SETs
We care about teaching quality because more effective teachers will produce more knowledgeable and capable students. However, student evaluations of teaching are not particularly good indicators of teaching quality and are not associated with the independently measured learning gains of students (i.e., test scores, final grades) (Uttl et al., 2017).[3] This speaks to the lack of criterion validity. Higher teaching quality should be associated with better learning outcomes for students, but across multiple studies stretching back years, there is no association that cannot be better explained by other factors. To be fair, there are scholars who find that SETs are valid and reliable. For a thorough defense of SETs as well as a historical summary of the literature see Benton & Cashin (2012).[4]
Some sources of error are easy to spot. As a faculty member, there are a number of things I can do to influence my evaluations and disrupt validity and reliability. Since SETs scores are associated with the grades students perceive they will receive (e.g., Boring et al., 2016),[5] guaranteeing everyone a final grade of A in my class will likely increase my SETs scores and my chances at tenure and promotion. I could time an email reminder to complete SETs with releasing high grades for a major assignment to boost my evaluation scores. On the other hand, student evaluations might be coincidentally timed with poor grades or difficult assignments that will bias student evaluations downward. Students may also infer I am manipulating them and give me lower SET scores as a result. To maximize my SET scores and chances and promotion, I also need to select which courses I teach carefully. Classes that are more quantitatively oriented generally receive lower ratings than more qualitative and humanities-driven classes, which makes my decision to teach social work research a poor strategy (Uttl & Smibert, 2017).[6] The only manipulative strategy I will admit to using is bringing food (usually cookies or donuts) to class during the period in which students are completing evaluations. I can systematically bias scores in a positive direction by feeding students nice treats and telling them how much I appreciated them before handing out the student evaluation forms.
As a white cis-gender male educator, I am adversely impacted by SETs because of their sketchy validity, reliability, and methodology. The other flaws with student evaluations actually help me while disadvantaging teachers from oppressed groups. Heffernan (2021)[7] provides a comprehensive overview of the sexism, racism, ableism, and prejudice baked into student evaluations:
“In all studies relating to gender, the analyses indicate that the highest scores are awarded in subjects filled with young, white, male students being taught by white English first language speaking, able-bodied, male academics who are neither too young nor too old (approx. 35–50 years of age), and who the students believe are heterosexual. Most deviations from this scenario in terms of student and academic demographics equates to lower SET scores. These studies thus highlight that white, able-bodied, heterosexual, men of a certain age are not only the least affected, they benefit from the practice. When every demographic group who does not fit this image is significantly disadvantaged by SETs, these processes serve to further enhance the position of the already privileged” (p. 5).
The staggering consistency of studies examining prejudice in SETs has led to some rather superficial reforms like reminding students to not submit racist or sexist responses in the written instructions given before SETs. Yet, even though we know that SETs are systematically biased against women, people of color, and people with disabilities, the overwhelming majority of universities in the United States continue to use them to evaluate faculty for promotion or reappointment. From a critical perspective, it is worth considering why university administrators continue to use such a biased and flawed instrument. SETs produce data that make it easy to compare faculty to one another and track faculty members over time. Furthermore, they offer students a direct opportunity to voice their concerns and highlight what went well.
Teaching quality or effectiveness is not a well-behaved variable. Bias can explain a lot of the variance produced by the measurement model, and conclusions drawn from SETs should include this limitation. For example, if we were interested in testing the impact of using a free textbook on student learning outcomes, we might use SETs as a measure of teaching effectiveness. Free textbooks might make teachers more effective because students can access the book without a paywall (see Hilton, YEAR for more on the access hypothesis). Using SETs as our dependent variable to brings these limitations to the conclusions we draw about the theoretical concept of teaching effectiveness. Similarly, tenure and promotion schemes that require a minimum average score across SETs would bring the errors associated with SETs into hiring decisions.
Consider the risks: Incomplete & flawed measures
As the people with the greatest knowledge about what happened in the classroom as whether it met their expectations, providing students with open-ended questions is the most productive part of SETs. Personally, I have found focus groups written, facilitated, and analyzed by student researchers to be more insightful than SETs. MSW student activists and leaders may look for ways to evaluate faculty that are more methodologically sound and less systematically biased, creating institutional change by replacing or augmenting traditional SETs in their department. There is very rarely student input on the criteria and methodology for teaching evaluations, yet students are the most impacted by helpful or harmful teaching practices.
Students should fight for better assessment in the classroom because well-designed assessments provide documentation to support more effective teaching practices and discourage unhelpful or discriminatory practices. Flawed assessments like SETs, can lead to a lack of information about problems with courses, instructors, or other aspects of the program. Think critically about what data your program uses to gauge its effectiveness. How might you introduce areas of student concern into how your program evaluates itself? Are there issues with food or housing insecurity, mentorship of nontraditional and first generation students, or other issues that faculty should consider when they evaluate their program? Finally, as you transition into practice, think about how your agency measures its impact and how it privileges or excludes client and community voices in the assessment process.
Let’s consider an example from social work practice. Let’s say you work for a mental health organization that serves youth impacted by community violence. How should you measure the impact of your services on your clients and their community? Schools may be interested in reducing truancy, self-injury, or other behavioral concerns. However, by centering delinquent behaviors in how we measure our impact, we may be inattentive to the role of trauma, family dynamics, and other cognitive and social processes beyond “delinquent behavior.” Indeed, we may bias our interventions by focusing on things that are not as important to clients’ needs. Social workers want to make sure their programs are improving over time, and we rely on our measures to indicate what to change and what to keep. If our measures present a partial or flawed view, we lose our ability to establish and act on scientific truths.
SETs are important to me a a faculty member. For students, you may be interested in similar arguments against the standard grading scale (A-F), and why grades (numerical, letter, etc.) do not do a good job of measuring learning. Think critically about the role that grades play in your life as a student, your self-concept, and your relationships with teachers. Your test and grade anxiety is due in part to how your learning is measured. Those measurements end up becoming an official record of your scholarship and allow employers or funders to compare you to other scholars. The stakes for measurement are the same for participants in your research study.
Key Takeaways
- Mismatches between conceptualization and measurement are often places in which bias and systemic injustice enter the research process.
- Measurement modeling is a way of foregrounding researcher’s assumptions in how they connect their conceptual definitions and operational definitions.
- Theoretical concepts from your research questions are latent variables that are operationalized into observable properties.
- Check the empirical literature to see if your variables are well-behaved, meaning they have little impact and can be accounted for using standard statistical procedures.
- Build a measurement model of what you expect to find when you use these measures to make arguments about their underlying theoretical constructs, evaluating which assumptions you feel more strongly or weakly about.
Exercises
- Outline the measurement model in your research study.
- Distinguish between the measures in your study and their underlying theoretical constructs.
- Which assumptions do you feel more secure in your reasoning? Which assumptions feel like they need more support, and where would you go to get that information?
- Assess the validity, reliability, and fairness of the measures in your operational definitions.
- Search for articles using the names of any standardized measures in your model.
- Look at the citations in the Methods sections of journal articles using similar measures.
- Draft a measurement error model.
- Is there any scientific evidence of invalidity, unreliability, or unfairness from prior researchers?
- All measures have some kind of error. Based on the evidence you collected, do you anticipate your measurement error to be well-behaved?
10.2 Construct validity
Learning Objectives
Learners will be able to…
- Assess the construct validity of measurement models
- Apply the specific subtypes of construct validity to the measurement model in your research study
- Critique the fairness of automatic decision-making systems that use incomplete and flawed measurement models
Diving into measurement modeling further, we will examine two measurement models. First, we will examine Maslach’s Burnout Inventory (MBI), a commonly-used standardized measure of burnout used in social work research. Following the original publication of the MBI in 1981, researchers developed new versions of the MBI for different target populations: Human Services Survey (MBI-HSS), Human Services Survey for Medical Personnel (MBI-HSS (MP)), Educators Survey (MBI-ES), General Survey (MBI-GS),[5] and General Survey for Students (MBI-GS [S]). Operationalizing social worker burnout using the MBI-HSS uses a three-dimension model for burnout : emotional exhaustion, depersonalization, and personal accomplishment. Students have less extreme versions of the underlying theoretical constructs of burnout (e.g., have not personally accomplished as much but feel personally efficacious about their early work). Authors of the MBI scale rewound burnout back a few years, and yielded a student-oriented three-dimensional model of burnout that changes emotional exhaustion to exhaustion, depersonalization to cynicism, and professional accomplishment to professional efficacy. It makes sense that students would have less intensive symptoms of burnout, and this is reflected in the MBI’s measurement model for students.
My colleagues in the Placement Poverty Working Group and I used the MBI with social work students completing field practicums, and well, which would you choose for measuring MSW students? Are student workers best measured by the MBI-GS(S) because they are students or are they practitioners best measured by the MBI-HSS because they are health services workers? I started work on unpaid placements because my students during COVID-19 said they were “unpaid frontline workers in a pandemic.” The underlying theoretical framework for our study was that many social work graduate students already work in human service agencies, making the MBI-HSS more appropriate. Furthermore, if we saw the more dramatic burnout indicators on the MBI-HSS dimensions like depersonalization, we would establish that students are experiencing more intense burnout than the MBI-GS(S) anticipated with concepts like cynicism.
Thus, our research team adopted a measurement model for the burnout of social work students using the MBI-HSS which entailed these assumptions:
- The theoretical construct of social work practicum laborer burnout influences the real-world measurements obtained by the MBI-HSS.
- Burnout has three dimensions: emotional exhaustion, depersonalization, and personal accomplishment.
- Someone with higher emotional exhaustion has higher burnout (direct relationship).
- Someone with higher depersonalization has higher burnout (direct relationship).
- Someone with higher personal accomplishment has less burnout (inverse relationship).
- There is no cut score for burnout/no burnout. Conclusions can be drawn about each burnout dimension, but they do not sum into a larger score.
- The MBI is a valid, reliable, and fair measurement of burnout (with specific attention to the target population of social work students in field practicums)
Second, we will analyze the Association of Social Work Boards (ASWB) examinations required in most states for licensed masters and bachelors practice, and in all state for licensed clinical social work practice. A more complete discussion of the measurement model issues in ASWB examinations can be found in a special issue of Advances in Social Work on licensure exams. Our discussion here will discuss how state boards use an applicant’s ASWB examination score to regulate licensed practice. One’s ASWB examination score measures “first-day competence” of social workers applying for a given license level (e.g., bachelors, masters, clinical). The social worker’s true competence is the latent variable that cannot be observed directly.
Examinations have a public protection purpose, so the theoretical construct of competence is assumed to be equivalent to public protection. A passing test score indicates a lower likelihood to commit ethical and legal offenses. When boards adopt ASWB exams, they adopt their measurement model for public protection. Look at the Content Outline with knowledge, skills, and abilities (KSAs) KSAs for the ASWB masters examination for a clearer sense of the assumptions that underly ASWB examinations. Pages 42-48 of ASWB’s 2024 Practice Analysis provide the exact statements (e.g., “Impact of urbanization, globalization, environmental hazards, and climate change on individuals, families, groups, organizations, and communities”) that ASWB asks practitioners rate according to their frequency and importance for safe and ethical social work practice. ASWB pays and trains subject matter experts (i.e., social workers) to write questions, evaluate them for bias, and set standards for cut scores. The measurement model that states use to assure public safety from unethical social work practice can be outlined as such:
- Public safety is equivalent to minimum competence for first-day practice.
- The theoretical construct of first-day competence influences one’s score on the ASWB examinations.
- First-day competence is composed of three to four content areas, each with a few dozen statements reflecting the knowledge, skills, and abilities of an ethical and safe social worker.
- There is no universal cut score. Subject matter experts estimate the difficulty of each question, and the cut score varies based on the difficulty of the pool of items included in different test versions.
- Someone who fails the examination by a single point is incompetent to practice social work as a licensed practitioner.
- The ASWB examinations are valid, reliable, and fair measurements of social work competence.
The measurement modeling process necessarily involves making assumptions. However, these assumptions must be made explicit and tested before the resulting measurements are used. Leaving them unexamined obscures any possible mismatches between the theoretical understanding of the construct purported to be measured and its operationalization, in turn obscuring any resulting fairness-related harms. In this section we apply and extend the measurement quality concepts from Chapter 9 to address specifically aspects of fairness and social justice.
Construct validity and its subtypes
Construct validity is roughly analogous to the concept of statistical unbiasedness [30]. Establishing construct validity means demonstrating, in a variety of ways, that the measurements obtained from measurement model are accurate.
Different disciplines have different conceptualizations of construct validity, each with its own rich history. For example, in some disciplines, construct validity is considered distinct from content validity and criterion validity, while in other disciplines, content validity and criterion validity are grouped under the umbrella of construct validity. Jacobs & Wallach’s (2022) conceptualization unites traditions from political science, education, and psychology by bringing together the seven different aspects of construct validity that we describe below. They argue that each of these aspects plays a unique and important role in understanding fairness in computational systems:
- Content validity: Does the operationalization capture all relevant aspects of the construct purported to be measured?
- Face validity: Do the measurements look plausible?
- Convergent validity: Do they correlate with other measurements of the same construct?
- Discriminant validity: Do the measurements vary in ways that suggest that the operationalization may be inadvertently capturing aspects of other constructs?
- Predictive validity: Are the measurements predictive of measurements of any relevant observable properties (and other unobservable theoretical constructs) thought to be related to the construct, but not incorporated into the operationalization?
- Hypothesis validity: Do the measurements support known hypotheses about the construct?
- Consequential validity: What are the consequences of using the measurements—including any societal impacts [40, 52].
Jacobs & Wallach (2022) emphasize that construct validity is not a yes/no box to be checked! Construct validity is always a matter of degree, supported by critical reasoning [36].
While we have used some of these validity terms before in Chapter 10 to assess measurement quality, the difference in Chapter 11 will be relating the operationalization back to the underlying theoretical concept (i.e., latent variable). That is, we are looking not only at the validity, reliability, fairness of each operational definition but how measurement error impacts the conclusions we can draw about latent variables, the theoretical constructs that are not directly measurable.
Face validity
Face validity refers to the extent to which the measurements obtained from a measurement model look plausible— a “sniff test” of sorts. It is inherently limited, as it establishes a plausible link between the latent variable and the observations from a measure. Face validity is a prerequisite for establishing construct validity. If the measurements obtained from a measurement model aren’t facially valid, you can stop your analysis. That measurement model is unlikely to possess other aspects of construct validity.
Using the example from section 2.1, measurements obtained by using income as a proxy for SES would most likely possess face validity. SES and income are certainly related and, in general, a person at the high end of the income distribution (e.g., a senior hospital administrator) will have a different SES than a person at the low end (e.g., a home health worker). Although you could poke holes in that validity, and we will, there is a plausible logic connecting income and SES. Similarly, the ASWB examinations are based on knowledge, skills, and abilities that are plausibly connected to social work practice. Every seven years or so, ASWB surveys practitioners with similar KSAs, making incremental changes over time as the profession changes. The MBI-HSS is based on the International Classification of Diseases (ICD-11) definition for burnout as an occupational problem (QD85). These are facially valid measures, and they have plausible relationships to the underlying theoretical constructs.
Content validity
Content validity refers to the extent to which an operationalization wholly and fully captures the substantive nature of the construct purported to be measured. This aspect of construct validity has three sub-aspects, described below.
Contestedness
The first sub-aspect relates to the construct’s contestedness. If a construct is essentially contested then it has multiple context dependent, and sometimes even conflicting, theoretical understandings. Contestedness makes it inherently hard to assess content validity: if a construct has multiple theoretical understandings, then it is unlikely that a single operationalization can wholly and fully capture its substantive nature in a meaningful fashion. Researchers must articulate which understanding is being operationalized [53] because it is often the case that unobservable theoretical constructs are essentially contested, yet we still wish to measure them.
When our research team used the MBI-HSS, one might contest that students are best measured using the student scale (MBI-GS(S)). One might contest the content validity of my operational definition by pointing out that I might miss dimensions of cynicism or efficacy not captured by the MBI-HSS subscales of depersonalization or accomplishment. Looking deeper, there are other standardized measures and theoretical conceptualizations of burnout like the Copenhagen Burnout Inventory (three-dimensional model: personal, work-related, and patient-related) and the Oldenburg Burnout Inventory (two-dimensional model: disengagement & exhaustion). This is common for social science concepts, and the contestedness of the MBI is relatively low.
Whether the ASWB examinations measure social work competence is deeply contested in the profession. In addition to the special issue of Advances in Social Work listed earlier, a previous special issue of the Journal of Evidence-Based Social Work also addressed critiques of ASWB’s conceptualization and operationalization. For example, ASWB examinations have been critiqued as excluding Afrocentric ways of knowing (Teasley, YEAR). Apgar (2021) highlighted that the Council on Social Work Education uses a the nine competencies of the Educational Policies and Accreditation Standards to conceptualize and operationalize social work competence. As of 2025, ASWB examinations use a four-dimensional model whose reliability with the CSWE EPAS was rated to be low (Apgar & Luquet, 2023).
Substantive validity
The second sub-aspect of content validity is sometimes known as substantive validity. This sub-aspect moves beyond the theoretical understanding of the construct purported to be measured and focuses on the measurement modeling process—i.e., the assumptions made when moving from abstractions to mathematics. Establishing substantive validity means demonstrating that the operationalization incorporates measurements of those—and only those—observable properties (and other unobservable theoretical constructs, if appropriate) thought to be related to the construct. For example, although a person’s income contributes to their SES, their income is by no means the only contributing factor. Wealth, education, and occupation all affect a person’s SES, as do other unobservable theoretical constructs, such as cultural capital. A retiree with significant wealth but a low income should have a higher SES than would be suggested by their income alone.
The validity and reliability of the MBI-HSS for my target population of social work students in the United States seemed well-established. There may be unrelated theoretical constructs influencing our measurements like work-family conflict, workplace exploitation, and others. Translating burnout across cultures may surface implicit norms about the workplace, home, and other factors shared by me and my target population that are different in another discipline or cultural group (Poghosyan et al., 2009). Adaptations of the MBI to different groups and work roles demonstrates that there are underlying aspects of each role that impact burnout. Evaluating substantive validity can be startlingly easy. Wang and colleagues (2024) developed a social burnout scale, and to make sure it was valid, they asked students from the target population to match the questions in the measurement to the underlying theoretical constructs. It is entirely possible to quantify how well your measure captures the underlying construct!
ASWB’s (2025) Examination Guidebook undermines any argument for its substantive validity when it states: ” there may be differences in exam performance outcomes for members of different demographic groups because exam performance is influenced by many factors external to the exams” (p. 8). The differences are pronounced. According to ASWB’s 2022 report, 85% of White test takers pass the masters-level exam on their first try. That figure is 51.3% for Black test takers under 30, 30% for Black test takers over 50, 68% of Latino/Hispanic test takers under 30 pass on their first attempt, and 45% of Latino/Hispanic test takers over 50 pass on their first attempt. In both cases, aspiring social workers from oppressed racial and ethnic groups are excluded at higher rates at younger ages, and those disparities increase substantially with age. With retakes, over 90% of White test takers eventually pass the masters exam, but only 52% of Black test takers and 63% of people whose first language is not English eventually pass the exam (ASWB, 2022). This pattern is mirrored in the undergraduate social work practice exam in which 82% of White test takers eventually pass the bachelors-level exam while only 38% of Black test takers and 50% of test takers whose first language is not English pass the exam eventually. ASWB maintains these are issues external to the examination (i.e., structural workforce discrimination), but its own reports demonstrate that controlling for external factors would still leave Black test-takers over 5x more likely to fail the clinical examination–about 2x for Asian & Latine social workers–than White social workers (Kim & Joo, 2024). Thus, there is evidence that the examinations reflect unknown statistical properties unrelated to what ASWB assumed: conceptualization of social work competence and underlying workforce discrimination.
Structural validity
Finally, establishing structural validity, the third sub-aspect of content validity, means demonstrating that the operationalization captures the structure of the relationships between the incorporated observable properties (and other unobservable theoretical constructs, if appropriate) and the construct purported to be measured, as well as the interrelationships between them [36, 40].
A contested aspects of burnout theory is how many dimensions it has. Factor analysis is a statistical technique used by psychometricians to assess whether the empirical results of a measure adhere to the structure of the underlying construct. Since the theory says there should be three factors, the results of a factor analysis should indicate three factors, not one, two, four, etc. Although the three-factor or three-dimension model of burnout is commonly supported, many researchers have also found two-factor, three-factor, and four-factor solutions have been found (Lheurex et al., 2017). Searching for factorial validity can be a fruitful way of evaluating structural validity for multidimensional concepts like burnout. Another concept is the internal consistency reliability associated with the scale. Scale items from the same theoretical concept should be more correlated than those of dissimilar concepts. Structural validity of MBI-HSS has been established in many studies, and even in studies of French (Lheureux et al., 2017) , Spanish (Garcia et al., 2018), and Iranian health professionals (Lin et al., 2022).
For those of you who clicked through to the ASWB’s Knowledge, Skills, and Abilities handbook, which outlines their conceptualization, will be surprised to learn that it will soon change! According to the 2024 Analysis of the Practice of Social Work new examinations will contain three content areas “because of the similarities in the practice of social work in all categories of practice,” but somehow, “the restructuring maintains the distinct nature of each exam category and its corresponding practice category” (p. 1). ASWB is likely reducing the number of content areas because it will also be implementing examinations in which one has to only retake the content areas one failed, not the entire examination. ASWB also “renam[ed] or recategoriz[ed]” the content areas to be consistent across bachelors, masters, advanced generalist, and clinical license exams. ASWB reported consulting with psychometricians but rather than performing a factor analysis, ASWB made these decisions a priori to “capture similarities among the exam categories, providing a common framework for applied knowledge that spans” each level (p. 7). These a priori assumptions are a fine place to start, but they should be accompanied by empirical evidence that the underlying constructs have indeed changed!
Convergent validity
Convergent validity refers to the extent to which the measurements obtained from a measurement model correlate with other measurements of the same construct, obtained from measurement models for which construct validity has already been established. This aspect of construct validity is typically assessed using quantitative methods, though doing so can reveal qualitative differences between different operationalizations. Our initial measurement model for SES was income, but comparing our measure with SES measured by National Committee on Vital and Health Statistics which includes wealth, education, occupation, economic pressure, geographic location, and family size, would likely reveal important aspects that income-alone would miss. Assessing convergent validity can reveal qualitative differences between different operationalizations of a construct.
Note that assessing convergent validity raises an inherent challenge: “If a new measure of some construct differs from an established measure, it is generally viewed with skepticism. If a new measure captures exactly what the previous one did, then it is probably unnecessary” [49]. The measurements obtained from a new measurement model should therefore deviate only slightly from existing measurements of the same construct. Moreover, for the model to be viewed as possessing convergent validity, these deviations must be well justified and supported by critical reasoning. There are many adaptations of the MBI scale to different populations, including a health practitioner version of the MBI-HSS. One might also evaluate the MBI alongside the Copenhagen or Oldenburg burnout inventories as Ogundipe and colleagues (2022) did.
ASWB examinations do not have substantive alternative. States no longer create their own exams like Virginia and California used to do. Thus, there are no studies comparing licensing exams. One could use ASWB’s 2018 examination blueprint (2018-2025) versus their 2010 examination blueprint (2011-2017). Across all examinations, the examination pass rate reduces from about 80% to about 70% across all examinees. ASWB did not provide statistics on minoritized populations for the 2010 blueprint, making it difficult to assess convergent validity across years beyond the top-line pass rate. Given the structural changes highlighted above that ASWB will implement in the 2026 blueprint, state boards should demand equivalency testing. Instead, there is an implicit assumption that convergent validity persists across blueprints that is never empirically documented.
Discriminant validity
Discriminant validity, in measurement modeling, refers to the extent to which the measurements obtained from a measurement model vary in ways that suggest that the operationalization may be inadvertently capturing aspects of other constructs. Measurements of one construct should only correlate with measurements of another to the extent that those constructs are themselves related. As a special case, if two constructs are totally unrelated, then there should be no correlation between their measurements [25].
Establishing discriminant validity can be especially challenging when a construct has relationships with many other constructs. SES, for example, is related to almost all social and economic constructs, albeit to varying extents. For instance, SES and gender are somewhat related due to labor segregation and the persistent gender wage gap, while SES and race are much more closely related due to historical racial inequalities resulting from structural racism. When assessing the discriminant validity of the model described previously, we would therefore hope to find correlations that reflect these relationships. If, however, we instead found that the resulting measurements were perfectly correlated with gender or uncorrelated with race, this would suggest a lack of discriminant validity.
Continuing with our example of burnout, we might want to investigate its relationship to job satisfaction, and a factor analysis of both should reveal a two-factor model (burnout and job satisfaction) each with correlated subfactors, as Tsigilis and colleagues (2004) found. Similarly, one would want to establish that burnout is not the same thing as anxiety or depression. There are no factor analyses for ASWB examinations, so it is difficult to infer their psychometric structure. Studies of ASWB practice examinations found that MSW students (Albright & Thyer, 2011) and ChatGPT (Victor et al., 2023) can guess the correct answer without looking at the question stem more than half of the time, with AI able to pass generalist examinations. Thus, there are likely linguistic patterns, implicit constructs, that the examination measures that are not part of its explicit conceptualization. For this reason, qualitative reports echo testing advice to “think like a middle-aged White woman” to discern the correct answer (Torres et al., 2023).
Predictive validity
Predictive validity refers to the extent to which the measurements obtained from a measurement model are predictive of measurements of any relevant observable properties (and other unobservable theoretical constructs) thought to be related to the construct purported to be measured, but not incorporated into the operationalization. Predictive validity can be assessed using either qualitative or quantitative methods. Note that in contrast to the aspects of construct validity that we discussed above, predictive validity is primarily concerned with the utility of the measurements, not their meaning.
Predictive validity of ASWB examinations seems straightforward. Passing an ASWB examination should be associated with one’s propensity to commit ethical or legal violations with clients, but there have not been any systematic investigations since Kinderknecht’s 1995 dissertation using Kansas state records. Of course, one could assess the many state who never used bachelors or masters examinations, or removed them after the 2022 report demonstrated severe equity concerns. Comparing states who have adopted or removed examinations would provide evidence of predictive validity. For example, Illinois reported no changes in licensure complaints or sanctions after removing their masters examination and allowing alternative pathways to clinical licensure. Similarly, the predictive validity of the MBI-HSS could be assessed using things like job dissatisfaction, patient mortality, and quality of care (Aiken et al., 2002a,b).
Hypothesis validity
Hypothesis validity refers to the extent to which the measurements obtained from a measurement model support substantively interesting hypotheses about the construct purported to be measured. Much like predictive validity, hypothesis validity is primarily concerned with the utility of the measurements. We note that the main distinction between predictive validity and hypothesis validity hinges on the definition of “substantively interesting hypotheses.” As a result, the distinction is not always clear cut. For example, is the hypothesis “People with higher SES are more likely to be mentioned in the New York Times” sufficiently substantively interesting? Or would it be more appropriate to use the hypothesized relationship to assess predictive validity? For this reason, some traditions merge predictive and hypothesis validity [e.g., 30].
Let’s start with some simple measurement models. Using income as a proxy for SES would likely support some— though not all—substantively interesting hypotheses involving SES. For example, many social scientists have studied the relationship between SES and health outcomes, demonstrating that people with lower SES tend to have worse health outcomes. Measurements of SES obtained from the model described previously would likely support this hypothesis, albeit with some notable exceptions. For instance, wealthy college students often have low incomes but good access to healthcare. Combined with their young age, this means that they typically have better health outcomes than other people with comparable incomes. Examining these exceptions might reveal aspects of the substantive nature of SES, such as wealth and education, that are missing from the model described previously.
As you might expect, there is no specific test for hypothesis validity. Looking at the last 40+ years and thousands of journal articles on Maslach’s Burnout Inventory reveals that this measurement model seems to be broadly useful for generating hypotheses about burnout. Because ASWB’s measure is proprietary, social work researchers have not been able to test meaningful hypotheses about it. Other than Kim & Joo (2024), researchers have used practice examinations with retired exam items instead of ASWB’s own data.
Consequential validity
Consequential validity, the final aspect in our fairness-oriented conceptualization of construct validity, is concerned with identifying and evaluating the consequences of using the measurements obtained from a measurement model, including any societal impacts. Assessing consequential validity often reveals fairness-related harms. Consequential validity was first introduced by Messick, who argued that the consequences of using the measurements obtained from a measurement model are fundamental to establishing construct validity [40]. This is because the values that are reflected in those consequences both derive from and contribute back the theoretical understanding of the construct purported to be measured. In other words, the “measurements both reflect structure in the natural world, and impose structure upon it,” [26]—i.e., the measurements shape the ways that we understand the construct itself. Assessing consequential validity therefore means answering the following questions: How is the world shaped by using the measurements? What world do we wish to live in? If there are contexts in which the consequences of using the measurements would cause us to compromise values that we wish to uphold, then the measurements should not be used in those contexts.
For example, when designing a kitchen, we might use measurements of a person’s standing height to determine the height at which to place their kitchen countertop. However, this may render the countertop inaccessible to them if they use a wheelchair. As another example, because the Universal Credit benefits system described previously assumed that measuring a person’s monthly income by totaling the wages deposited into their account over a single one-month period would yield error-free measurements, many people—especially those with irregular pay schedules— received substantially lower benefits than they were entitled to.
The consequences of measurement error in ASWB examinations can be dire. Retaking the examination costs additional time and money. In many states, there is a limited time during which one must pass the examination or exit the worse entirely. According to Timmons and colleagues (2025), removing the masters examination requirement doubled the size of the MSW workforce in Illinois in two years. Because of these consequences, the Council on Social Work Education, National Association of Social Workers, and National Association of Deans and Directors of Schools of Social Work are presently advocating for the removal of bachelors and masters examinations, with an alternative pathway at the clinical level (DeCarlo & Nienow, 2025). By comparison, there are fewer consequences associated with erroneously estimating someone’s burnout.
Make your measurement model clear
Because measurement modeling is often skipped over, researchers and practitioners may be inclined to collapse the distinctions between constructs and their operationalizations in how they talk about, think about, and study the concepts in their research question. Measurements of unobservable theoretical constructs are often treated as if they were obtained directly and without errors—i.e., a source of ground truth. Measurements end up standing in for the constructs purported to be measured, normalizing the assumptions made during the measurement modeling process and embedding them throughout society. In other words, “measures are more than a creation of society, they create society.” [1]. Collapsing the distinctions between constructs and their operationalizations is therefore not just theoretically or pedantically concerning—it is practically concerning with very real, fairness-related consequences.
How we decide to measure what we are researching is influenced by our backgrounds, including our culture, implicit biases, and individual experiences. For me as a middle-class, cisgender white man, the decisions I make about measurement will probably default to ones that make the most sense to me and others like me, and thus measure characteristics about us most accurately if I don’t think carefully about it. There are major implications for research here because this could affect the validity of my measurements for other populations.
This doesn’t mean that standardized scales or indices, for instance, won’t work for diverse groups of people. What it means is that researchers must not ignore difference in deciding how to measure a variable in their research. Doing so may serve to push already marginalized people further into the margins of academic research and, consequently, social work intervention. Social work researchers, with our strong orientation toward celebrating difference and working for social justice, are obligated to keep this in mind for ourselves and encourage others to think about it in their research, too. Similarly, we are obligated to advocate on behalf of clients and communities impacted by measurements beyond their control, including credit scores, risk scores, and other measures used by systems of monitoring and control.
This involves reflecting on what we are measuring, how we are measuring, and why we are measuring. Do we have biases that impacted how we operationalized our concepts? Did we include stakeholders and gatekeepers in the development of our concepts? This can be a way to gain access to vulnerable populations. What feedback did we receive on our measurement process and how was it incorporated into our work? These are all questions we should ask as we are thinking about measurement. Further, engaging in this intentionally reflective process will help us maximize the chances that our measurement will be accurate and as free from bias as possible.
Key Takeaways
- Mismatches between conceptualization and measurement are often places in which bias and systemic injustice enter the research process.
- Measurement modeling is a way of foregrounding researcher’s assumptions in how they connect their conceptual definitions and operational definitions.
- Social work research consumers should critically evaluate the construct validity and reliability of measures in the studies of social work populations.
Exercises
- Look back at the measurement model you drafted in 10.1
- Use the following types of validity as search terms in Google Scholar or an academic database. Assess your measures’…
- Content validity
- Substantive validity
- Structural validity and/or factorial validity
- Convergent validity
- Discriminant validity
- Predictive validity
- Based on your reading of the literature on your measurements, assess their:
- Contestedness
- Hypothesis validity
- Consequential validity
10.3 Post-positivism: The assumptions of quantitative methods
Learning Objectives
Learners will be able to…
- Ground your research project and working question in the philosophical assumptions of social science
- Define the terms ‘ontology‘ and ‘epistemology‘ and explain how they relate to quantitative and qualitative research methods
- Apply feminist, anti-racist, and decolonization critiques of social science to your project
- Define axiology and describe the axiological assumptions of research projects
Let’s zoom out from your measurement model and the specific operational and conceptual definitions in your question and into the deeper assumptions underlying quantitative social science about truth, discovery, and power that shape the research process. These assumptions are easy to overlook, but they are crucial for understanding how quantitative methods have adapted over time to become more robust against invalid, unreliable, and unfair measures. Researchers do not need to spend their time investigating these assumptions for their measurement model, but the limitations of these assumptions impact all measurement models in quantitative social science.
Before we can dive into philosophy, we need to recall out conversation from Chapter 1 about objective truth and subjective truths. Let’s test your knowledge with a quick example. Is crime on the rise in the United States? A recent Five Thirty Eight article highlights the disparity between historical trends on crime that are at or near their lowest in the thirty years with broad perceptions by the public that crime is on the rise (Koerth & Thomson-DeVeaux, 2020).[8] Social workers skilled at research can marshal objective truth through statistics, much like the authors do, to demonstrate that people’s perceptions are not based on a rational interpretation of the world. Of course, that is not where our work ends. Subjective truths might decenter this narrative of ever-increasing crime, deconstruct its racist and oppressive origins, or simply document how that narrative shapes how individuals and communities conceptualize their world.
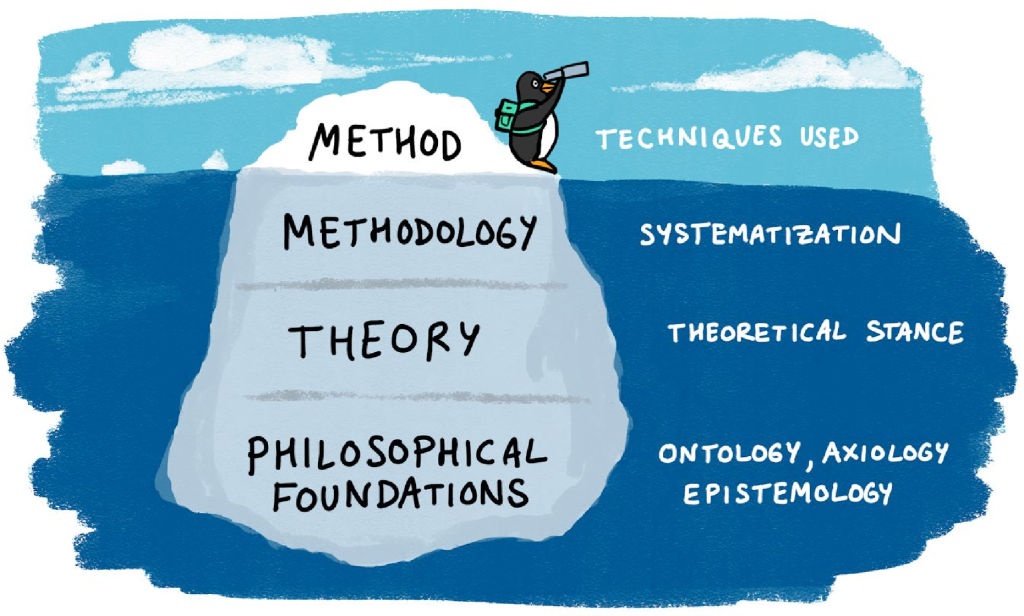
Objective does not mean right, and subjective does not mean wrong. Researchers must understand what kind of truth they are searching for so they can choose a theoretical framework, methodology, and research question that matches. As we discussed in Chapter 1, researchers seeking objective truth (one of the philosophical foundations at the bottom of Figure 7.1) often employ quantitative methods (one of the methods at the top of Figure 7.1). Similarly, researchers seeking subjective truths (again, at the bottom of Figure 7.1) often employ qualitative methods (at the top of Figure 7.1). This chapter is about the connective tissue (the middle two layers of Figure 7.1).
Positivism: Researcher as “expert”
Positivism is concerned with understanding what is true for everybody. Social workers whose working question fits best with the positivist paradigm will want to produce data that are generalizable and can speak to larger populations. For this reason, positivistic researchers favor quantitative methods—probability sampling, experimental or survey design, and multiple, and standardized instruments to measure key concepts.
A positivist orientation to research is appropriate when your research question asks for generalizable truths. For example, your working question may look something like: does my agency’s housing intervention lead to fewer periods of homelessness for our clients? It is necessary to study such a relationship quantitatively and objectively. When social workers speak about social problems impacting societies and individuals, they reference positivist research, including experiments and surveys of the general populations. Positivist research is exceptionally good at producing cause-and-effect explanations that apply across many different situations and groups of people. There are many good reasons why positivism is the dominant research paradigm in the social sciences.
The default paradigm
Positivism (and post-positivism) is the dominant paradigm in social science. We define paradigm a set of common philosophical (ontological, epistemological, and axiological) assumptions that inform research. The four paradigms we describe in this section refer to patterns in how groups of researchers resolve philosophical questions. Some assumptions naturally make sense together, and paradigms grow out of researchers with shared assumptions about what is important and how to study it. Paradigms are like “analytic lenses” and a provide framework on top of which we can build theoretical and empirical knowledge (Kuhn, 1962).[9] Consider this video of an interview with world-famous physicist Richard Feynman in which he explains why “when you explain a ‘why,’ you have to be in some framework that you allow something to be true. Otherwise, you are perpetually asking why.” In order to answer basic physics question like “what is happening when two magnets attract?” or a social work research question like “what is the impact of this therapeutic intervention on depression,” you must understand the assumptions you are making about social science and the social world. Paradigmatic assumptions about objective and subjective truth support methodological choices like whether to conduct interviews or send out surveys, for example.
When you think of science, you are probably thinking of positivistic science–like the kind the physicist Richard Feynman did. It has its roots in the scientific revolution of the Enlightenment. Positivism is based on the idea that we can come to know facts about the natural world through our experiences of it. The processes that support this are the logical and analytic classification and systemization of these experiences. Through this process of empirical analysis, Positivists aim to arrive at descriptions of law-like relationships and mechanisms that govern the world we experience.
Positivists have traditionally claimed that the only authentic knowledge we have of the world is empirical and scientific. Essentially, positivism downplays any gap between our experiences of the world and the way the world really is; instead, positivism determines objective “facts” through the correct methodological combination of observation and analysis. Data collection methods typically include quantitative measurement, which is supposed to overcome the individual biases of the researcher.
Positivism aspires to high standards of validity and reliability supported by evidence, and has been applied extensively in both physical and social sciences. Its goal is familiar to all students of science: iteratively expanding the evidence base of what we know is true. We can know our observations and analysis describe real world phenomena because researchers separate themselves and objectively observe the world, placing a deep epistemological separation between “the knower” and “what is known” and reducing the possibility of bias. We can all see the logic in separating yourself as much as possible from your study so as not to bias it, even if we know we cannot do so perfectly.
Limitations of positivism
The criticism often made of positivism with regard to human and social sciences (e.g. education, psychology, sociology) is that positivism is scientistic; which is to say that it overlooks differences between the objects in the natural world (tables, atoms, cells, etc.) and the subjects in the social work (self-aware people living in a complex socio-historical context). In pursuit of the generalizable truth of “hard” science, it fails to adequately explain the many aspects of human experience don’t conform to this way of collecting data. Furthermore, by viewing science as an idealized pursuit of pure knowledge, positivists may ignore the many ways in which power structures our access to scientific knowledge, the tools to create it, and the capital to participate in the scientific community.
Positivism may not fit the messy, contradictory, and circular world of human relationships. A positivistic approach does not allow the researcher to understand another person’s subjective mental state in detail. This is because the positivist orientation focuses on quantifiable, generalizable data—and therefore encompasses only a small fraction of what may be true in any given situation. This critique is emblematic of the interpretivist paradigm, which we will describe when we conceptualize qualitative research methods.
From a critical perspective, the positivist paradigm (and the interpretivist paradigm) focus too little on social change, values, and oppression. Positivists assume they know what is true, but they often do not incorporate the knowledge and experiences of oppressed people, even when those community members are directly impacted by the research. Positivism has been critiqued as ethnocentrist, patriarchal, and classist (Kincheloe & Tobin, 2009).[10] This leads them to do research on, rather than with populations by excluding them from the conceptualization, design, and impact of a project. It also leads them to ignore the historical and cultural context that is important to understanding the social world. The result can be a one-dimensional and reductionist view of reality.
Assumptions of positivist social science
Kivunja & Kuyini (2017)[11] describe the essential features of positivism as:
- A belief that theory is universal and law-like generalizations can be made across contexts
- The assumption that context is not important
- The belief that truth or knowledge is ‘out there to be discovered’ by research
- The belief that cause and effect are distinguishable and analytically separable
- The belief that results of inquiry can be quantified
- The belief that theory can be used to predict and to control outcomes
- The belief that research should follow the scientific method of investigation
- Rests on formulation and testing of hypotheses
- Employs empirical or analytical approaches
- Pursues an objective search for facts
- Believes in ability to observe knowledge
- The researcher’s ultimate aim is to establish a comprehensive universal theory, to account for human and social behavior
- Application of the scientific method
Let’s explore the underlying assumptions behind these beliefs. Can we really be sure that quantitative social science can tell us about the world?
Ontology: Assumptions about what is real & true
In section 1.2, we reviewed the two types of truth that social work researchers seek—objective truth and subjective truths —and linked these with the methods—quantitative and qualitative—that researchers use to study the world. If those ideas aren’t fresh in your mind, you may want to navigate back to that section for an introduction.
These two types of truth rely on different assumptions about what is real in the social world—i.e., they have a different ontology. Ontology refers to the study of being (literally, it means “rational discourse about being”). In philosophy, basic questions about existence are typically posed as ontological, e.g.:
- What is there?
- What types of things are there?
- How can we describe existence?
- What kind of categories can things go into?
- Are the categories of existence hierarchical?
Objective vs. subjective ontologies
At first, it may seem silly to question whether the phenomena we encounter in the social world are real. Of course you exist, your thoughts exist, your computer exists, and your friends exist. You can see them with your eyes. This is the ontological framework of realism, which simply means that the concepts we talk about in science exist independent of observation (Burrell & Morgan, 1979).[12] Obviously, when we close our eyes, the universe does not disappear. You may be familiar with the philosophical conundrum: “If a tree falls in a forest and no one is around to hear it, does it make a sound?”
The natural sciences, like physics and biology, also generally rely on the assumption of realism. Lone trees falling make a sound. We assume that gravity and the rest of physics are there, even when no one is there to observe them. Mitochondria are easy to spot with a powerful microscope, and we can observe and theorize about their function in a cell. The gravitational force is invisible, but clearly apparent from observable facts, such as watching an apple fall from a tree. Of course, out theories about gravity have changed over the years. Improvements were made when observations could not be correctly explained using existing theories and new theories emerged that provided a better explanation of the data.
As we discussed in section 1.2, culture-bound syndromes are an excellent example of where you might come to question realism. Of course, from a Western perspective as researchers in the United States, we think that the Diagnostic and Statistical Manual (DSM) classification of mental health disorders is real and that these culture-bound syndromes are aberrations from the norm. But what about if you were a person from Korea experiencing Hwabyeong? Wouldn’t you consider the Western diagnosis of somatization disorder to be incorrect or incomplete? This conflict raises the question–do either Hwabyeong or DSM diagnoses like post-traumatic stress disorder (PTSD) really exist at all…or are they just social constructs that only exist in our minds?
If your answer is “no, they do not exist,” you are adopting the ontology of anti-realism (or relativism), or the idea that social concepts do not exist outside of human thought. Unlike the realists who seek a single, universal truth, the anti-realists perceive a sea of truths, created and shared within a social and cultural context. Unlike objective truth, which is true for all, subjective truths will vary based on who you are observing and the context in which you are observing them. The beliefs, opinions, and preferences of people are actually truths that social scientists measure and describe. Additionally, subjective truths do not exist independent of human observation because they are the product of the human mind. We negotiate what is true in the social world through language, arriving at a consensus and engaging in debate within our socio-cultural context.
These theoretical assumptions should sound familiar if you’ve studied social constructivism or symbolic interactionism in your other MSW courses, most likely in human behavior in the social environment (HBSE).[13] From an anti-realist perspective, what distinguishes the social sciences from natural sciences is human thought. When we try to conceptualize trauma from an anti-realist perspective, we must pay attention to the feelings, opinions, and stories in people’s minds. In their most radical formulations, anti-realists propose that these feelings and stories are all that truly exist.
What happens when a situation is incorrectly interpreted? Certainly, who is correct about what is a bit subjective. It depends on who you ask. Even if you can determine whether a person is actually incorrect, they think they are right. Thus, what may not be objectively true for everyone is nevertheless true to the individual interpreting the situation. Furthermore, they act on the assumption that they are right. We all do. Much of our behaviors and interactions are a manifestation of our personal subjective truth. In this sense, even incorrect interpretations are truths, even though they are true only to one person or a group of misinformed people. This leads us to question whether the social concepts we think about really exist. For researchers using subjective ontologies, they might only exist in our minds; whereas, researchers who use objective ontologies which assume these concepts exist independent of thought.
How do we resolve this dichotomy? As social workers, we know that often times what appears to be an either/or situation is actually a both/and situation. Let’s take the example of trauma. There is clearly an objective thing called trauma. We can draw out objective facts about trauma and how it interacts with other concepts in the social world such as family relationships and mental health. However, that understanding is always bound within a specific cultural and historical context. Moreover, each person’s individual experience and conceptualization of trauma is also true. Much like a client who tells you their truth through their stories and reflections, when a participant in a research study tells you what their trauma means to them, it is real even though only they experience and know it that way. By using both objective and subjective analytic lenses, we can explore different aspects of trauma—what it means to everyone, always, everywhere, and what is means to one person or group of people, in a specific place and time.

Epistemology: Assumptions about how we know things
Having discussed what is true, we can proceed to the next natural question—how can we come to know what is real and true? This is epistemology. Epistemology is derived from the Ancient Greek epistēmē which refers to systematic or reliable knowledge (as opposed to doxa, or “belief”). Basically, it means “rational discourse about knowledge,” and the focus is the study of knowledge and methods used to generate knowledge. Epistemology has a history as long as philosophy, and lies at the foundation of both scientific and philosophical knowledge.
Epistemological questions include:
- What is knowledge?
- How can we claim to know anything at all?
- What does it mean to know something?
- What makes a belief justified?
- What is the relationship between the knower and what can be known?
While these philosophical questions can seem far removed from real-world interaction, thinking about these kinds of questions in the context of research helps you target your inquiry by informing your methods and helping you revise your working question. Epistemology is closely connected to method as they are both concerned with how to create and validate knowledge. Research methods are essentially epistemologies – by following a certain process we support our claim to know about the things we have been researching. Inappropriate or poorly followed methods can undermine claims to have produced new knowledge or discovered a new truth. This can have implications for future studies that build on the data and/or conceptual framework used.
Research methods can be thought of as essentially stripped down, purpose-specific epistemologies. The knowledge claims that underlie the results of surveys, focus groups, and other common research designs ultimately rest on epistemological assumptions of their methods. Focus groups and other qualitative methods usually rely on subjective epistemological (and ontological) assumptions. Surveys and and other quantitative methods usually rely on objective epistemological assumptions. These epistemological assumptions often entail congruent subjective or objective ontological assumptions about the ultimate questions about reality.
Objective vs. subjective epistemologies
One key consideration here is the status of ‘truth’ within a particular epistemology or research method. If, for instance, some approaches emphasize subjective knowledge and deny the possibility of an objective truth, what does this mean for choosing a research method?
We began to answer this question in Chapter 1 when we described the scientific method and objective and subjective truths. Epistemological subjectivism focuses on what people think and feel about a situation, while epistemological objectivism focuses on objective facts irrelevant to our interpretation of a situation (Lin, 2015).[14]
While there are many important questions about epistemology to ask (e.g., “How can I be sure of what I know?” or “What can I not know?” see Willis, 2007[15] for more), from a pragmatic perspective most relevant epistemological question in the social sciences is whether truth is better accessed using numerical data or words and performances. Generally, scientists approaching research with an objective epistemology (and realist ontology) will use quantitative methods to arrive at scientific truth. Quantitative methods examine numerical data to precisely describe and predict elements of the social world. For example, while people can have different definitions for poverty, an objective measurement such as an annual income of “less than $25,100 for a family of four” provides a precise measurement that can be compared to incomes from all other people in any society from any time period, and refers to real quantities of money that exist in the world. Mathematical relationships are uniquely useful in that they allow comparisons across individuals as well as time and space. In this book, we will review the most common designs used in quantitative research: surveys and experiments. These types of studies usually rely on the epistemological assumption that mathematics can represent the phenomena and relationships we observe in the social world.
Although mathematical relationships are useful, they are limited in what they can tell you. While you can learn use quantitative methods to measure individuals’ experiences and thought processes, you will miss the story behind the numbers. To analyze stories scientifically, we need to examine their expression in interviews, journal entries, performances, and other cultural artifacts using qualitative methods. Because social science studies human interaction and the reality we all create and share in our heads, subjectivists focus on language and other ways we communicate our inner experience. Qualitative methods allow us to scientifically investigate language and other forms of expression—to pursue research questions that explore the words people write and speak. This is consistent with epistemological subjectivism’s focus on individual and shared experiences, interpretations, and stories.
It is important to note that qualitative methods are entirely compatible with seeking objective truth. Approaching qualitative analysis with a more objective perspective, we look simply at what was said and examine its surface-level meaning. If a person says they brought their kids to school that day, then that is what is true. A researcher seeking subjective truth may focus on how the person says the words—their tone of voice, facial expressions, metaphors, and so forth. By focusing on these things, the researcher can understand what it meant to the person to say they dropped their kids off at school. Perhaps in describing dropping their children off at school, the person thought of their parents doing the same thing or tried to understand why their kid didn’t wave back to them as they left the car. In this way, subjective truths are deeper, more personalized, and difficult to generalize.

Self-determination and free will
When scientists observe social phenomena, they often take the perspective of determinism, meaning that what is seen is the result of processes that occurred earlier in time (i.e., cause and effect). This process is represented in the classical formulation of a research question which asks “what is the relationship between X (cause) and Y (effect)?” By framing a research question in such a way, the scientist is disregarding any reciprocal influence that Y has on X. Moreover, the scientist also excludes human agency from the equation. It is simply that a cause will necessitate an effect. For example, a researcher might find that few people living in neighborhoods with higher rates of poverty graduate from high school, and thus conclude that poverty causes adolescents to drop out of school. This conclusion, however, does not address the story behind the numbers. Each person who is counted as graduating or dropping out has a unique story of why they made the choices they did. Perhaps they had a mentor or parent that helped them succeed. Perhaps they faced the choice between employment to support family members or continuing in school.
For this reason, determinism is critiqued as reductionistic in the social sciences because people have agency over their actions. This is unlike the natural sciences like physics. While a table isn’t aware of the friction it has with the floor, parents and children are likely aware of the friction in their relationships and act based on how they interpret that conflict. The opposite of determinism is free will, that humans can choose how they act and their behavior and thoughts are not solely determined by what happened prior in a neat, cause-and-effect relationship. Researchers adopting a perspective of free will view the process of, continuing with our education example, seeking higher education as the result of a number of mutually influencing forces and the spontaneous and implicit processes of human thought. For these researchers, the picture painted by determinism is too simplistic.
A similar dichotomy can be found in the debate between individualism and holism. When you hear something like “the disease model of addiction leads to policies that pathologize and oppress people who use drugs,” the speaker is making a methodologically holistic argument. They are making a claim that abstract social forces (the disease model, policies) can cause things to change. A methodological individualist would critique this argument by saying that the disease model of addiction doesn’t actually cause anything by itself. From this perspective, it is the individuals, rather than any abstract social force, who oppress people who use drugs. The disease model itself doesn’t cause anything to change; the individuals who follow the precepts of the disease model are the agents who actually oppress people in reality. To an individualist, all social phenomena are the result of individual human action and agency. To a holist, social forces can determine outcomes for individuals without individuals playing a causal role, undercutting free will and research projects that seek to maximize human agency.
Exercises
- Examine an article from your literature review
- Is human action, or free will, informing how the authors think about the people in their study?
- Or are humans more passive and what happens to them more determined by the social forces that influence their life?
- Reflect on how this project’s assumptions may differ from your own assumptions about free will and determinism. For example, my beliefs about self-determination and free will always inform my social work practice. However, my working question and research project may rely on social theories that are deterministic and do not address human agency.
Radical change
Another assumption scientists make is around the nature of the social world. Is it an orderly place that remains relatively stable over time? Or is it a place of constant change and conflict? The view of the social world as an orderly place can help a researcher describe how things fit together to create a cohesive whole. For example, systems theory can help you understand how different systems interact with and influence one another, drawing energy from one place to another through an interconnected network with a tendency towards homeostasis. This is a more consensus-focused and status-quo-oriented perspective. Yet, this view of the social world cannot adequately explain the radical shifts and revolutions that occur. It also leaves little room for human action and free will. In this more radical space, change consists of the fundamental assumptions about how the social world works.
For example, when writing a previous edition, there were protests are taking place across the world to remember the killing of George Floyd by Minneapolis police and other victims of police violence and systematic racism. Public support of Black Lives Matter, an anti-racist activist group that focuses on police violence and criminal justice reform, has experienced a radical shift in public support in just two weeks since the killing, equivalent to the previous 21 months of advocacy and social movement organizing (Cohn & Quealy, 2020).[16] Abolition of police and prisons, once a fringe idea, has moved into the conversation about remaking the criminal justice system from the ground-up, centering its historic and current role as an oppressive system for Black Americans. Seemingly overnight, reducing the money spent on police and giving that money to social services became a moderate political position.
A researcher centering change may choose to understand this transformation or even incorporate radical anti-racist ideas into the design and methods of their study. For an example of how to do so, see this participatory action research study working with Black and Latino youth (Bautista et al., 2013).[17] Contrastingly, a researcher centering consensus and the status quo might focus on incremental changes what people currently think about the topic. For example, see this survey of social work student attitudes on poverty and race that seeks to understand the status quo of student attitudes and suggest small changes that might change things for the better (Constance-Huggins et al., 2020).[18] To be clear, both studies contribute to racial justice. However, you can see by examining the methods section of each article how the participatory action research article addresses power and values as a core part of their research design, qualitative ethnography and deep observation over many years, in ways that privilege the voice of people with the least power. In this way, it seeks to rectify the epistemic injustice of excluding and oversimplifying Black and Latino youth. Contrast this more radical approach with the more traditional approach taken in the second article, in which they measured student attitudes using a survey developed by researchers.
Exercises
- Examine an article from your literature review
- Traditional studies will be less participatory. The researcher will determine the research question, how to measure it, data collection, etc.
- Radical studies will be more participatory. The researcher seek to undermine power imbalances at each stage of the research process.
- Pragmatically, more participatory studies take longer to complete and are less suited to projects that need to be completed in a short time frame.

Axiology: Assumptions about values
Axiology is the study of values and value judgements (literally “rational discourse about values [a xía]”). In philosophy this field is subdivided into ethics (the study of morality) and aesthetics (the study of beauty, taste and judgement). For the hard-nosed scientist, the relevance of axiology might not be obvious. After all, what difference do one’s feelings make for the data collected? Don’t we spend a long time trying to teach researchers to be objective and remove their values from the scientific method?
Like ontology and epistemology, the import of axiology is typically built into research projects and exists “below the surface”. You might not consciously engage with values in a research project, but they are still there. Similarly, you might not hear many researchers refer to their axiological commitments but they might well talk about their values and ethics, their positionality, or a commitment to social justice.
Our values focus and motivate our research. These values could include a commitment to scientific rigor, or to always act ethically as a researcher. At a more general level we might ask: What matters? Why do research at all? How does it contribute to human wellbeing? Almost all research projects are grounded in trying to answer a question that matters or has consequences. Some research projects are even explicit in their intention to improve things rather than observe them. This is most closely associated with “critical” approaches.
Critical and radical views of science focus on how to spread knowledge and information in a way that combats oppression. These questions are central for creating research projects that fight against the objective structures of oppression—like unequal pay—and their subjective counterparts in the mind—like internalized sexism. For example, a more critical research project would fight not only against statutes of limitations for sexual assault but on how women have internalized rape culture as well. Its explicit goal would be to fight oppression and to inform practice on women’s liberation. For this reason, creating change is baked into the research questions and methods used in more critical and radical research projects.
As part of studying radical change and oppression, we are likely employing a model of science that puts values front-and-center within a research project. All social work research is values-driven, as we are a values-driven profession. Historically, though, most social scientists have argued for values-free science. Scientists agree that science helps human progress, but they hold that researchers should remain as objective as possible—which means putting aside politics and personal values that might bias their results, similar to the cognitive biases we discussed in section 1.1. Over the course of last century, this perspective was challenged by scientists who approached research from an explicitly political and values-driven perspective. As we discussed earlier in this section, feminist critiques strive to understand how sexism biases research questions, samples, measures, and conclusions, while decolonization critiques try to de-center the Western perspective of science and truth.
Linking axiology, epistemology, and ontology
It is important to note that both values-central and values-neutral perspectives are useful in furthering social justice. Values-neutral science is helpful at predicting phenomena. Indeed, it matches well with objectivist ontologies and epistemologies. Let’s examine a measure of depression, the Patient Health Questionnaire (PSQ-9). The authors of this measure spent years creating a measure that accurately and reliably measures the concept of depression. This measure is assumed to measure depression in any person, and scales like this are often translated into other languages (and subsequently validated) for more widespread use . The goal is to measure depression in a valid and reliable manner. We can use this objective measure to predict relationships with other risk and protective factors, such as substance use or poverty, as well as evaluate the impact of evidence-based treatments for depression like narrative therapy.
While measures like the PSQ-9 help with prediction, they do not allow you to understand an individual person’s experience of depression. To do so, you need to listen to their stories and how they make sense of the world. The goal of understanding isn’t to predict what will happen next, but to empathically connect with the person and truly understand what’s happening from their perspective. Understanding fits best in subjectivist epistemologies and ontologies, as they allow for multiple truths (i.e. that multiple interpretations of the same situation are valid). Although all researchers addressing depression are working towards socially just ends, the values commitments researchers make as part of the research process influence them to adopt objective or subjective ontologies and epistemologies.
Many quantitative researchers now identify as postpositivist. Postpositivism retains the idea that truth should be considered objective, but asserts that our experiences of such truths are necessarily imperfect because they are ameliorated by our values and experiences. Understanding how postpositivism has updated itself in light of the developments in other research paradigms is instructive for developing your own paradigmatic framework. Epistemologically, postpositivists operate on the assumption that human knowledge is based not on the assessments from an objective individual, but rather upon human conjectures. As human knowledge is thus unavoidably conjectural and uncertain, though assertions about what is true and why it is true can be modified or withdrawn in the light of further investigation. However, postpositivism is not a form of relativism, and generally retains the idea of objective truth.
These epistemological assumptions are based on ontological assumptions that an objective reality exists, but contra positivists, they believe reality can be known only imperfectly and probabilistically. While positivists believe that research is or can be value-free or value-neutral, postpositivists take the position that bias is undesired but inevitable, and therefore the investigator must work to detect and try to correct it. Postpositivists work to understand how their axiology (i.e., values and beliefs) may have influenced their research, including through their choice of measures, populations, questions, and definitions, as well as through their interpretation and analysis of their work. Methodologically, they use mixed methods and both quantitative and qualitative methods, accepting the problematic nature of “objective” truths and seeking to find ways to come to a better, yet ultimately imperfect understanding of what is true. A popular form of postpositivism is critical realism, which lies between positivism and interpretivism.
Social workers must understand measurement theory to engage in social justice work. That’s because measurement theory and its supporting philosophical assumptions will help sharpen your perceptions of the social world. They help social workers build heuristics that can help identify the fundamental assumptions at the heart of social conflict and social problems. They alert you to the patterns in the underlying assumptions that different people make and how those assumptions shape their worldview, what they view as true, and what they hope to accomplish. Understanding these deeper structures behind research evidence is a true gift of social work research. Because we acknowledge the usefulness and truth value of multiple philosophies and worldviews contained in this chapter, we can arrive at a deeper and more nuanced understanding of the social world.
Exercises
What role will values play in your study?
- Are you looking to be as objective as possible, putting aside your own values?
- Or are you infusing values into each aspect of your research design?
Remember that although social work is a values-based profession, that does not mean that all social work research is values-informed. The majority of social work research is objective and tries to be value-neutral in how it approaches research.
- Clayson, D. E. (2018). Student evaluation of teaching and matters of reliability. Assessment & Evaluation in Higher Education, 43(4), 666-681. ↵
- Clayson, D. E. (2018). Student evaluation of teaching and matters of reliability. Assessment & Evaluation in Higher Education, 43(4), 666-681. ↵
- Uttl, B., White, C. A., & Gonzalez, D. W. (2017). Meta-analysis of faculty's teaching effectiveness: Student evaluation of teaching ratings and student learning are not related. Studies in Educational Evaluation, 54, 22-42. ↵
- Benton, S. L., & Cashin, W. E. (2014). Student ratings of instruction in college and university courses. In Higher education: Handbook of theory and research (pp. 279-326). Springer, Dordrecht. ↵
- Boring, A., Ottoboni, K., & Stark, P. (2016). Student evaluations of teaching (mostly) do not measure teaching effectiveness. ScienceOpen Research. ↵
- Uttl, B., & Smibert, D. (2017). Student evaluations of teaching: teaching quantitative courses can be hazardous to one’s career. Peer Journal, 5, e3299. ↵
- Heffernan, T. (2021). Sexism, racism, prejudice, and bias: a literature review and synthesis of research surrounding student evaluations of courses and teaching. Assessment & Evaluation in Higher Education, 1-11. ↵
- Koerth, M. & Thomson-DeVeaux, A. (2020, August 3). Many Americans are convinced crime is rising in the U.S. They're wrong. FiveThirtyEight. Retrieved from: https://fivethirtyeight.com/features/many-americans-are-convinced-crime-is-rising-in-the-u-s-theyre-wrong ↵
- Burrell, G. & Morgan, G. (1979). Sociological paradigms and organizational analysis. Routledge. Guba, E. (ed.) (1990). The paradigm dialog. SAGE. ↵
- Kincheloe, J. L. & Tobin, K. (2009). The much exaggerated death of positivism. Cultural studies of science education, 4, 513-528. ↵
- Kivuna, C. & Kuyini, A. B. (2017). Understanding and applying research paradigms in educational contexts. International Journal of Higher Education, 6(5), 26-41. https://eric.ed.gov/?id=EJ1154775 ↵
- Burrell, G. & Morgan, G. (1979). Sociological paradigms and organizational analysis. Routledge. ↵
- Here are links to two HBSE open textbooks, if you are unfamiliar with social work theories. https://uark.pressbooks.pub/hbse1/ and https://uark.pressbooks.pub/humanbehaviorandthesocialenvironment2/ ↵
- Lin, C. T. (2016). A critique of epistemic subjectivity. Philosophia, 44(3), 915-920. ↵
- Wills, J. W. (2007). World views, paradigms and the practice of social science research. Thousand Oaks, CA: Sage. ↵
- Cohn, N. & Quealy, K. (2020, June 10). How public opinion has moved on Black Lives Matter. The New York Times. Retrieved from: https://www.nytimes.com/interactive/2020/06/10/upshot/black-lives-matter-attitudes.html ↵
- Bautista, M., Bertrand, M., Morrell, E., Scorza, D. A., & Matthews, C. (2013). Participatory action research and city youth: Methodological insights from the Council of Youth Research. Teachers College Record, 115(10), 1-23. ↵
- Constance-Huggins, M., Davis, A., & Yang, J. (2020). Race Still Matters: The Relationship Between Racial and Poverty Attitudes Among Social Work Students. Advances in Social Work, 20(1), 132-151. ↵
is a statistical model that links unobservable theoretical constructs (i.e., conceptual definitions) and observable properties a researcher measures (i.e., operational definitions) within a sample or data set
Conditions that are not directly observable and represent states of being, experiences, and ideas.
Clues that demonstrate the presence, intensity, or other aspects of a concept in the real world
an unobservable variable that can be operationalized into observable indicators a researcher can measure
assumptions the researcher makes about the errors in their measurements
assumption that the errors associated with a measurement model are normally distributed, statistically unbiased, and possessing a small variance (Jacobs & Wallach, 2022)
The value in the middle when all our values are placed in numerical order. Also called the 50th percentile.
the measurements obtained from measurement model are accurate representations of the latent variable
The extent to which a measurement method appears “on its face” to measure the construct of interest
The extent to which a measure “covers” the construct of interest, i.e., it's comprehensiveness to measure the construct.
a component of content validity, If a construct has multiple context dependent, even conflicting, theoretical understandings
the operationalization incorporates measurements of those—and only those—observable properties (and other unobservable theoretical constructs, if appropriate) thought to be related to the construct
the operationalization captures the structure of the relationships between the incorporated observable properties (and other unobservable theoretical constructs, if appropriate) and the construct purported to be measured, as well as the interrelationships between them
The extent to which scores on a measure are not correlated with measures of variables that are conceptually distinct.
A type of criterion validity that examines how well your tool predicts a future criterion.
the extent to which the measurements obtained from a measurement model support substantively interesting hypotheses about the construct purported to be measured
the impact on society and target populations of the measurement model and how it influences our understanding of the underlying social construct
individuals or groups who have an interest in the outcome of the study you conduct
the people or organizations who control access to the population you want to study
a single truth, observed without bias, that is universally applicable
one truth among many, bound within a social and cultural context
a paradigm guided by the principles of objectivity, knowability, and deductive logic
a set of common philosophical (ontological, epistemological, and axiological) assumptions that inform research
assumptions about what is real and true
assumptions about how we come to know what is real and true
quantitative methods examine numerical data to precisely describe and predict elements of the social world
qualitative methods interpret language and behavior to understand the world from the perspectives of other people
assumptions about the role of values in research
