
19 Single-subjects design
Need to organize the beginning of this chapter. It’s just copypasta at the moment
- General idea is this:
- So far, in this book, we have discussed group-based designs. But to understand how someone can use statistics or qualitative data to demonstrate what is true, we will boil it down to a single person.
Learning Objectives
- Explain what single-subject research is, including how it differs from other types of psychological research.
- Explain who uses single-subject research and why.
What Is Single-Subject Research?
Single-subject research is a type of quantitative research that involves studying in detail the behavior of each of a small number of participants. Note that the term single-subject does not mean that only one participant is studied; it is more typical for there to be somewhere between two and 10 participants. (This is why single-subject research designs are sometimes called small-n designs, where n is the statistical symbol for the sample size.) Single-subject research can be contrasted with group research, which typically involves studying large numbers of participants and examining their behavior primarily in terms of group means, standard deviations, and so on. The majority of this textbook is devoted to understanding group research, which is the most common approach in psychology. But single-subject research is an important alternative, and it is the primary approach in some more applied areas of psychology.
Before continuing, it is important to distinguish single-subject research from case studies and other more qualitative approaches that involve studying in detail a small number of participants. As described in Chapter 6, case studies involve an in-depth analysis and description of an individual, which is typically primarily qualitative in nature. More broadly speaking, qualitative research focuses on understanding people’s subjective experience by observing behavior and collecting relatively unstructured data (e.g., detailed interviews) and analyzing those data using narrative rather than quantitative techniques. Single-subject research, in contrast, focuses on understanding objective behavior through experimental manipulation and control, collecting highly structured data, and analyzing those data quantitatively.
Assumptions of Single-Subject Research
Again, single-subject research involves studying a small number of participants and focusing intensively on the behavior of each one. But why take this approach instead of the group approach? There are several important assumptions underlying single-subject research, and it will help to consider them now.
First and foremost is the assumption that it is important to focus intensively on the behavior of individual participants. One reason for this is that group research can hide individual differences and generate results that do not represent the behavior of any individual. For example, a treatment that has a positive effect for half the people exposed to it but a negative effect for the other half would, on average, appear to have no effect at all. Single-subject research, however, would likely reveal these individual differences. A second reason to focus intensively on individuals is that sometimes it is the behavior of a particular individual that is primarily of interest. A school psychologist, for example, might be interested in changing the behavior of a particular disruptive student. Although previous published research (both single-subject and group research) is likely to provide some guidance on how to do this, conducting a study on this student would be more direct and probably more effective.
A second assumption of single-subject research is that it is important to discover causal relationships through the manipulation of an independent variable, the careful measurement of a dependent variable, and the control of extraneous variables. For this reason, single-subject research is often considered a type of experimental research with good internal validity. Recall, for example, that Hall and his colleagues measured their dependent variable (studying) many times—first under a no-treatment control condition, then under a treatment condition (positive teacher attention), and then again under the control condition. Because there was a clear increase in studying when the treatment was introduced, a decrease when it was removed, and an increase when it was reintroduced, there is little doubt that the treatment was the cause of the improvement.
A third assumption of single-subject research is that it is important to study strong and consistent effects that have biological or social importance. Applied researchers, in particular, are interested in treatments that have substantial effects on important behaviors and that can be implemented reliably in the real-world contexts in which they occur. This is sometimes referred to as social validity (Wolf, 1976)[1]. The study by Hall and his colleagues, for example, had good social validity because it showed strong and consistent effects of positive teacher attention on a behavior that is of obvious importance to teachers, parents, and students. Furthermore, the teachers found the treatment easy to implement, even in their often-chaotic elementary school classrooms.
Who Uses Single-Subject Research?
Single-subject research has been around as long as the field of psychology itself. In the late 1800s, one of psychology’s founders, Wilhelm Wundt, studied sensation and consciousness by focusing intensively on each of a small number of research participants. Herman Ebbinghaus’s research on memory and Ivan Pavlov’s research on classical conditioning are other early examples, both of which are still described in almost every introductory psychology textbook.
In the middle of the 20th century, B. F. Skinner clarified many of the assumptions underlying single-subject research and refined many of its techniques (Skinner, 1938)[2]. He and other researchers then used it to describe how rewards, punishments, and other external factors affect behavior over time. This work was carried out primarily using nonhuman subjects—mostly rats and pigeons. This approach, which Skinner called the experimental analysis of behavior—remains an important subfield of psychology and continues to rely almost exclusively on single-subject research. For excellent examples of this work, look at any issue of the Journal of the Experimental Analysis of Behavior. By the 1960s, many researchers were interested in using this approach to conduct applied research primarily with humans—a subfield now called applied behavior analysis (Baer, Wolf, & Risley, 1968)[3]. Applied behavior analysis plays an especially important role in contemporary research on developmental disabilities, education, organizational behavior, and health, among many other areas. Excellent examples of this work (including the study by Hall and his colleagues) can be found in the Journal of Applied Behavior Analysis.
Although most contemporary single-subject research is conducted from the behavioral perspective, it can in principle be used to address questions framed in terms of any theoretical perspective. For example, a studying technique based on cognitive principles of learning and memory could be evaluated by testing it on individual high school students using the single-subject approach. The single-subject approach can also be used by clinicians who take any theoretical perspective—behavioral, cognitive, psychodynamic, or humanistic—to study processes of therapeutic change with individual clients and to document their clients’ improvement (Kazdin, 1982)[4].
Learning Objectives
- Describe the basic elements of a single-subject research design.
- Design simple single-subject studies using reversal and multiple-baseline designs.
- Explain how single-subject research designs address the issue of internal validity.
- Interpret the results of simple single-subject studies based on the visual inspection of graphed data.
General Features of Single-Subject Designs
Before looking at any specific single-subject research designs, it will be helpful to consider some features that are common to most of them. Many of these features are illustrated in Figure 10.1, which shows the results of a generic single-subject study. First, the dependent variable (represented on the y-axis of the graph) is measured repeatedly over time (represented by the x-axis) at regular intervals. Second, the study is divided into distinct phases, and the participant is tested under one condition per phase. The conditions are often designated by capital letters: A, B, C, and so on. Thus Figure 10.1 represents a design in which the participant was tested first in one condition (A), then tested in another condition (B), and finally retested in the original condition (A). (This is called a reversal design and will be discussed in more detail shortly.)
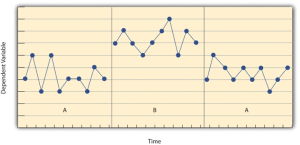
Another important aspect of single-subject research is that the change from one condition to the next does not usually occur after a fixed amount of time or number of observations. Instead, it depends on the participant’s behavior. Specifically, the researcher waits until the participant’s behavior in one condition becomes fairly consistent from observation to observation before changing conditions. This is sometimes referred to as the steady state strategy (Sidman, 1960)[5]. The idea is that when the dependent variable has reached a steady state, then any change across conditions will be relatively easy to detect. Recall that we encountered this same principle when discussing experimental research more generally. The effect of an independent variable is easier to detect when the “noise” in the data is minimized.
Reversal Designs
The most basic single-subject research design is the reversal design, also called the ABA design. During the first phase, A, a baseline is established for the dependent variable. This is the level of responding before any treatment is introduced, and therefore the baseline phase is a kind of control condition. When steady state responding is reached, phase B begins as the researcher introduces the treatment. There may be a period of adjustment to the treatment during which the behavior of interest becomes more variable and begins to increase or decrease. Again, the researcher waits until that dependent variable reaches a steady state so that it is clear whether and how much it has changed. Finally, the researcher removes the treatment and again waits until the dependent variable reaches a steady state. This basic reversal design can also be extended with the reintroduction of the treatment (ABAB), another return to baseline (ABABA), and so on.
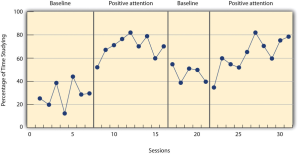
The study by Hall and his colleagues employed an ABAB reversal design. Figure 10.2 approximates the data for Robbie. The percentage of time he spent studying (the dependent variable) was low during the first baseline phase, increased during the first treatment phase until it leveled off, decreased during the second baseline phase, and again increased during the second treatment phase.
Why is the reversal—the removal of the treatment—considered to be necessary in this type of design? Why use an ABA design, for example, rather than a simpler AB design? Notice that an AB design is essentially an interrupted time-series design applied to an individual participant. Recall that one problem with that design is that if the dependent variable changes after the treatment is introduced, it is not always clear that the treatment was responsible for the change. It is possible that something else changed at around the same time and that this extraneous variable is responsible for the change in the dependent variable. But if the dependent variable changes with the introduction of the treatment and then changes back with the removal of the treatment (assuming that the treatment does not create a permanent effect), it is much clearer that the treatment (and removal of the treatment) is the cause. In other words, the reversal greatly increases the internal validity of the study.
There are close relatives of the basic reversal design that allow for the evaluation of more than one treatment. In a multiple-treatment reversal design, a baseline phase is followed by separate phases in which different treatments are introduced. For example, a researcher might establish a baseline of studying behavior for a disruptive student (A), then introduce a treatment involving positive attention from the teacher (B), and then switch to a treatment involving mild punishment for not studying (C). The participant could then be returned to a baseline phase before reintroducing each treatment—perhaps in the reverse order as a way of controlling for carryover effects. This particular multiple-treatment reversal design could also be referred to as an ABCACB design.
In an alternating treatments design, two or more treatments are alternated relatively quickly on a regular schedule. For example, positive attention for studying could be used one day and mild punishment for not studying the next, and so on. Or one treatment could be implemented in the morning and another in the afternoon. The alternating treatments design can be a quick and effective way of comparing treatments, but only when the treatments are fast acting.
Multiple-Baseline Designs
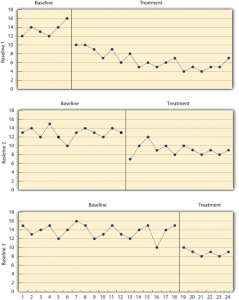
There are two potential problems with the reversal design—both of which have to do with the removal of the treatment. One is that if a treatment is working, it may be unethical to remove it. For example, if a treatment seemed to reduce the incidence of self-injury in a child with an intellectual delay, it would be unethical to remove that treatment just to show that the incidence of self-injury increases. The second problem is that the dependent variable may not return to baseline when the treatment is removed. For example, when positive attention for studying is removed, a student might continue to study at an increased rate. This could mean that the positive attention had a lasting effect on the student’s studying, which of course would be good. But it could also mean that the positive attention was not really the cause of the increased studying in the first place. Perhaps something else happened at about the same time as the treatment—for example, the student’s parents might have started rewarding him for good grades. One solution to these problems is to use a multiple-baseline design, which is represented in Figure 10.3. There are three different types of multiple-baseline designs which we will now consider.
Multiple-Baseline Design Across Participants
In one version of the design, a baseline is established for each of several participants, and the treatment is then introduced for each one. In essence, each participant is tested in an AB design. The key to this design is that the treatment is introduced at a different time for each participant. The idea is that if the dependent variable changes when the treatment is introduced for one participant, it might be a coincidence. But if the dependent variable changes when the treatment is introduced for multiple participants—especially when the treatment is introduced at different times for the different participants—then it is unlikely to be a coincidence.
As an example, consider a study by Scott Ross and Robert Horner (Ross & Horner, 2009)[6]. They were interested in how a school-wide bullying prevention program affected the bullying behavior of particular problem students. At each of three different schools, the researchers studied two students who had regularly engaged in bullying. During the baseline phase, they observed the students for 10-minute periods each day during lunch recess and counted the number of aggressive behaviors they exhibited toward their peers. After 2 weeks, they implemented the program at one school. After 2 more weeks, they implemented it at the second school. And after 2 more weeks, they implemented it at the third school. They found that the number of aggressive behaviors exhibited by each student dropped shortly after the program was implemented at the student’s school. Notice that if the researchers had only studied one school or if they had introduced the treatment at the same time at all three schools, then it would be unclear whether the reduction in aggressive behaviors was due to the bullying program or something else that happened at about the same time it was introduced (e.g., a holiday, a television program, a change in the weather). But with their multiple-baseline design, this kind of coincidence would have to happen three separate times—a very unlikely occurrence—to explain their results.
Multiple-Baseline Design Across Behaviors
In another version of the multiple-baseline design, multiple baselines are established for the same participant but for different dependent variables, and the treatment is introduced at a different time for each dependent variable. Imagine, for example, a study on the effect of setting clear goals on the productivity of an office worker who has two primary tasks: making sales calls and writing reports. Baselines for both tasks could be established. For example, the researcher could measure the number of sales calls made and reports written by the worker each week for several weeks. Then the goal-setting treatment could be introduced for one of these tasks, and at a later time the same treatment could be introduced for the other task. The logic is the same as before. If productivity increases on one task after the treatment is introduced, it is unclear whether the treatment caused the increase. But if productivity increases on both tasks after the treatment is introduced—especially when the treatment is introduced at two different times—then it seems much clearer that the treatment was responsible.
Multiple-Baseline Design Across Settings
In yet a third version of the multiple-baseline design, multiple baselines are established for the same participant but in different settings. For example, a baseline might be established for the amount of time a child spends reading during his free time at school and during his free time at home. Then a treatment such as positive attention might be introduced first at school and later at home. Again, if the dependent variable changes after the treatment is introduced in each setting, then this gives the researcher confidence that the treatment is, in fact, responsible for the change.
Data Analysis in Single-Subject Research
In addition to its focus on individual participants, single-subject research differs from group research in the way the data are typically analyzed. As we have seen throughout the book, group research involves combining data across participants. Group data are described using statistics such as means, standard deviations, correlation coefficients, and so on to detect general patterns. Finally, inferential statistics are used to help decide whether the result for the sample is likely to generalize to the population. Single-subject research, by contrast, relies heavily on a very different approach called visual inspection. This means plotting individual participants’ data as shown throughout this chapter, looking carefully at those data, and making judgments about whether and to what extent the independent variable had an effect on the dependent variable. Inferential statistics are typically not used.
In visually inspecting their data, single-subject researchers take several factors into account. One of them is changes in the level of the dependent variable from condition to condition. If the dependent variable is much higher or much lower in one condition than another, this suggests that the treatment had an effect. A second factor is trend, which refers to gradual increases or decreases in the dependent variable across observations. If the dependent variable begins increasing or decreasing with a change in conditions, then again this suggests that the treatment had an effect. It can be especially telling when a trend changes directions—for example, when an unwanted behavior is increasing during baseline but then begins to decrease with the introduction of the treatment. A third factor is latency, which is the time it takes for the dependent variable to begin changing after a change in conditions. In general, if a change in the dependent variable begins shortly after a change in conditions, this suggests that the treatment was responsible.
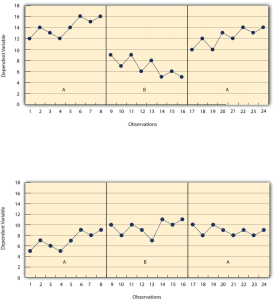
In the top panel of Figure 10.4, there are fairly obvious changes in the level and trend of the dependent variable from condition to condition. Furthermore, the latencies of these changes are short; the change happens immediately. This pattern of results strongly suggests that the treatment was responsible for the changes in the dependent variable. In the bottom panel of Figure 10.4, however, the changes in level are fairly small. And although there appears to be an increasing trend in the treatment condition, it looks as though it might be a continuation of a trend that had already begun during baseline. This pattern of results strongly suggests that the treatment was not responsible for any changes in the dependent variable—at least not to the extent that single-subject researchers typically hope to see.
The results of single-subject research can also be analyzed using statistical procedures—and this is becoming more common. There are many different approaches, and single-subject researchers continue to debate which are the most useful. One approach parallels what is typically done in group research. The mean and standard deviation of each participant’s responses under each condition are computed and compared, and inferential statistical tests such as the t test or analysis of variance are applied (Fisch, 2001)[7]. (Note that averaging across participants is less common.) Another approach is to compute the percentage of non-overlapping data (PND) for each participant (Scruggs & Mastropieri, 2001)[8]. This is the percentage of responses in the treatment condition that are more extreme than the most extreme response in a relevant control condition. In the study of Hall and his colleagues, for example, all measures of Robbie’s study time in the first treatment condition were greater than the highest measure in the first baseline, for a PND of 100%. The greater the percentage of non-overlapping data, the stronger the treatment effect. Still, formal statistical approaches to data analysis in single-subject research are generally considered a supplement to visual inspection, not a replacement for it.
Image Description
Figure 10.2 long description: Line graph showing the results of a study with an ABAB reversal design. The dependent variable was low during first baseline phase; increased during the first treatment; decreased during the second baseline, but was still higher than during the first baseline; and was highest during the second treatment phase. [Return to Figure 10.2]
Figure 10.3 long description: Three line graphs showing the results of a generic multiple-baseline study, in which different baselines are established and treatment is introduced to participants at different times.
For Baseline 1, treatment is introduced one-quarter of the way into the study. The dependent variable ranges between 12 and 16 units during the baseline, but drops down to 10 units with treatment and mostly decreases until the end of the study, ranging between 4 and 10 units.
For Baseline 2, treatment is introduced halfway through the study. The dependent variable ranges between 10 and 15 units during the baseline, then has a sharp decrease to 7 units when treatment is introduced. However, the dependent variable increases to 12 units soon after the drop and ranges between 8 and 10 units until the end of the study.
For Baseline 3, treatment is introduced three-quarters of the way into the study. The dependent variable ranges between 12 and 16 units for the most part during the baseline, with one drop down to 10 units. When treatment is introduced, the dependent variable drops down to 10 units and then ranges between 8 and 9 units until the end of the study. [Return to Figure 10.3]
Figure 10.4 long description: Two graphs showing the results of a generic single-subject study with an ABA design. In the first graph, under condition A, level is high and the trend is increasing. Under condition B, level is much lower than under condition A and the trend is decreasing. Under condition A again, level is about as high as the first time and the trend is increasing. For each change, latency is short, suggesting that the treatment is the reason for the change.
In the second graph, under condition A, level is relatively low and the trend is increasing. Under condition B, level is a little higher than during condition A and the trend is increasing slightly. Under condition A again, level is a little lower than during condition B and the trend is decreasing slightly. It is difficult to determine the latency of these changes, since each change is rather minute, which suggests that the treatment is ineffective. [Return to Figure 10.4]
Learning Objectives
- Explain some of the points of disagreement between advocates of single-subject research and advocates of group research.
- Identify several situations in which single-subject research would be appropriate and several others in which group research would be appropriate.
Single-subject research is similar to group research—especially experimental group research—in many ways. They are both quantitative approaches that try to establish causal relationships by manipulating an independent variable, measuring a dependent variable, and controlling extraneous variables. But there are important differences between these approaches too, and these differences sometimes lead to disagreements. It is worth addressing the most common points of disagreement between single-subject researchers and group researchers and how these disagreements can be resolved. As we will see, single-subject research and group research are probably best conceptualized as complementary approaches.
Data Analysis
One set of disagreements revolves around the issue of data analysis. Some advocates of group research worry that visual inspection is inadequate for deciding whether and to what extent a treatment has affected a dependent variable. One specific concern is that visual inspection is not sensitive enough to detect weak effects. A second is that visual inspection can be unreliable, with different researchers reaching different conclusions about the same set of data (Danov & Symons, 2008)[9]. A third is that the results of visual inspection—an overall judgment of whether or not a treatment was effective—cannot be clearly and efficiently summarized or compared across studies (unlike the measures of relationship strength typically used in group research).
In general, single-subject researchers share these concerns. However, they also argue that their use of the steady state strategy, combined with their focus on strong and consistent effects, minimizes most of them. If the effect of a treatment is difficult to detect by visual inspection because the effect is weak or the data are noisy, then single-subject researchers look for ways to increase the strength of the effect or reduce the noise in the data by controlling extraneous variables (e.g., by administering the treatment more consistently). If the effect is still difficult to detect, then they are likely to consider it neither strong enough nor consistent enough to be of further interest. Many single-subject researchers also point out that statistical analysis is becoming increasingly common and that many of them are using this as a supplement to visual inspection—especially for the purpose of comparing results across studies (Scruggs & Mastropieri, 2001)[10].
Turning the tables, some advocates of single-subject research worry about the way that group researchers analyze their data. Specifically, they point out that focusing on group means can be highly misleading. Again, imagine that a treatment has a strong positive effect on half the people exposed to it and an equally strong negative effect on the other half. In a traditional between-subjects experiment, the positive effect on half the participants in the treatment condition would be statistically cancelled out by the negative effect on the other half. The mean for the treatment group would then be the same as the mean for the control group, making it seem as though the treatment had no effect when in fact it had a strong effect on every single participant!
But again, group researchers share this concern. Although they do focus on group statistics, they also emphasize the importance of examining distributions of individual scores. For example, if some participants were positively affected by a treatment and others negatively affected by it, this would produce a bimodal distribution of scores and could be detected by looking at a histogram of the data. The use of within-subjects designs is another strategy that allows group researchers to observe effects at the individual level and even to specify what percentage of individuals exhibit strong, medium, weak, and even negative effects. Finally, factorial designs can be used to examine whether the effects of an independent variable on a dependent variable differ in different groups of participants (introverts vs. extraverts).
External Validity
The second issue about which single-subject and group researchers sometimes disagree has to do with external validity—the ability to generalize the results of a study beyond the people and specific situation actually studied. In particular, advocates of group research point out the difficulty in knowing whether results for just a few participants are likely to generalize to others in the population. Imagine, for example, that in a single-subject study, a treatment has been shown to reduce self-injury for each of two children with intellectual disabilities. Even if the effect is strong for these two children, how can one know whether this treatment is likely to work for other children with intellectual delays?
Again, single-subject researchers share this concern. In response, they note that the strong and consistent effects they are typically interested in—even when observed in small samples—are likely to generalize to others in the population. Single-subject researchers also note that they place a strong emphasis on replicating their research results. When they observe an effect with a small sample of participants, they typically try to replicate it with another small sample—perhaps with a slightly different type of participant or under slightly different conditions. Each time they observe similar results, they rightfully become more confident in the generality of those results. Single-subject researchers can also point to the fact that the principles of classical and operant conditioning—most of which were discovered using the single-subject approach—have been successfully generalized across an incredibly wide range of species and situations.
And, once again turning the tables, single-subject researchers have concerns of their own about the external validity of group research. One extremely important point they make is that studying large groups of participants does not entirely solve the problem of generalizing to other individuals. Imagine, for example, a treatment that has been shown to have a small positive effect on average in a large group study. It is likely that although many participants exhibited a small positive effect, others exhibited a large positive effect, and still others exhibited a small negative effect. When it comes to applying this treatment to another large group, we can be fairly sure that it will have a small effect on average. But when it comes to applying this treatment to another individual, we cannot be sure whether it will have a small, a large, or even a negative effect. Another point that single-subject researchers make is that group researchers also face a similar problem when they study a single situation and then generalize their results to other situations. For example, researchers who conduct a study on the effect of cell phone use on drivers on a closed oval track probably want to apply their results to drivers in many other real-world driving situations. But notice that this requires generalizing from a single situation to a population of situations. Thus the ability to generalize is based on much more than just the sheer number of participants one has studied. It requires a careful consideration of the similarity of the participants and situations studied to the population of participants and situations to which one wants to generalize (Shadish, Cook, & Campbell, 2002)[11].
Single-Subject and Group Research as Complementary Methods
As with quantitative and qualitative research, it is probably best to conceptualize single-subject research and group research as complementary methods that have different strengths and weaknesses and that are appropriate for answering different kinds of research questions (Kazdin, 1982)[12]. Single-subject research is particularly good for testing the effectiveness of treatments on individuals when the focus is on strong, consistent, and biologically or socially important effects. It is also especially useful when the behavior of particular individuals is of interest. Clinicians who work with only one individual at a time may find that it is their only option for doing systematic quantitative research.
Group research, on the other hand, is ideal for testing the effectiveness of treatments at the group level. Among the advantages of this approach is that it allows researchers to detect weak effects, which can be of interest for many reasons. For example, finding a weak treatment effect might lead to refinements of the treatment that eventually produce a larger and more meaningful effect. Group research is also good for studying interactions between treatments and participant characteristics. For example, if a treatment is effective for those who are high in motivation to change and ineffective for those who are low in motivation to change, then a group design can detect this much more efficiently than a single-subject design. Group research is also necessary to answer questions that cannot be addressed using the single-subject approach, including questions about independent variables that cannot be manipulated (e.g., number of siblings, extraversion, culture).
Finally, it is important to understand that the single-subject and group approaches represent different research traditions. This factor is probably the most important one affecting which approach a researcher uses. Researchers in the experimental analysis of behavior and applied behavior analysis learn to conceptualize their research questions in ways that are amenable to the single-subject approach. Researchers in most other areas of psychology learn to conceptualize their research questions in ways that are amenable to the group approach. At the same time, there are many topics in psychology in which research from the two traditions have informed each other and been successfully integrated. One example is research suggesting that both animals and humans have an innate “number sense”—an awareness of how many objects or events of a particular type have they have experienced without actually having to count them (Dehaene, 2011)[13]. Single-subject research with rats and birds and group research with human infants have shown strikingly similar abilities in those populations to discriminate small numbers of objects and events. This number sense—which probably evolved long before humans did—may even be the foundation of humans’ advanced mathematical abilities.
The Principle of Converging Evidence
Now that you have been introduced to many of the most commonly used research methods in psychology it should be readily apparent that no design is perfect. Every research design has strengths and weakness. True experiments typically have high internal validity but may have problems with external validity, while non-experimental research (e.g., correlational research) often has good external validity but poor internal validity. Each study brings us closer to the truth but no single study can ever be considered definitive. This is one reason why, in science, we say there is no such thing as scientific proof, there is only scientific evidence.
While the media will often try to reach strong conclusions on the basis of the findings of one study, scientists focus on evaluating a body of research. Scientists evaluate theories not by waiting for the perfect experiment but by looking at the overall trends in a number of partially flawed studies. The idea of converging evidence tells us to examine the pattern of flaws running through the research literature because the nature of this pattern can either support or undermine the conclusions we wish to draw. Suppose the findings from a number of different studies were largely consistent in supporting a particular conclusion. If all of the studies were flawed in a similar way, for example, if all of the studies were correlational and contained the third variable problem and the directionality problem, this would undermine confidence in the conclusions drawn because the consistency of the outcome may simply have resulted from a particular flaw that all of the studies shared. On the other hand, if all of the studies were flawed in different ways and the weakness of some of the studies were the strength of others (the low external validity of a true experiment was balanced by the high external validity of a correlational study), then we could be more confident in our conclusions.
While there are fundamental tradeoffs in different research methods, the diverse set of approaches used by psychologists have complementary strengths that allow us to search for converging evidence. We can reach meaningful conclusions and come closer to understanding truth by examining a large number of different studies each with different strengths and weakness. If the result of a large number of studies all conducted using different designs converge on the same conclusion then our confidence in that conclusion can be increased dramatically. In science, we strive for progress, not perfection.
Key Takeaways
- Single-subject research—which involves testing a small number of participants and focusing intensively on the behavior of each individual—is an important alternative to group research in psychology.
- Single-subject studies must be distinguished from qualitative research on a single person or small number of individuals. Unlike more qualitative research, single-subject research focuses on understanding objective behavior through experimental manipulation and control, collecting highly structured data, and analyzing those data quantitatively.
- Single-subject research has been around since the beginning of the field of psychology. Today it is most strongly associated with the behavioral theoretical perspective, but it can in principle be used to study behavior from any perspective.
- Single-subject research designs typically involve measuring the dependent variable repeatedly over time and changing conditions (e.g., from baseline to treatment) when the dependent variable has reached a steady state. This approach allows the researcher to see whether changes in the independent variable are causing changes in the dependent variable.
- In a reversal design, the participant is tested in a baseline condition, then tested in a treatment condition, and then returned to baseline. If the dependent variable changes with the introduction of the treatment and then changes back with the return to baseline, this provides strong evidence of a treatment effect.
- In a multiple-baseline design, baselines are established for different participants, different dependent variables, or different settings—and the treatment is introduced at a different time on each baseline. If the introduction of the treatment is followed by a change in the dependent variable on each baseline, this provides strong evidence of a treatment effect.
- Single-subject researchers typically analyze their data by graphing them and making judgments about whether the independent variable is affecting the dependent variable based on level, trend, and latency.
- Differences between single-subject research and group research sometimes lead to disagreements between single-subject and group researchers. These disagreements center on the issues of data analysis and external validity (especially generalization to other people).
- Single-subject research and group research are probably best seen as complementary methods, with different strengths and weaknesses, that are appropriate for answering different kinds of research questions.
Exercises
- Practice: Find and read a published article in psychology that reports new single-subject research. (An archive of articles published in the Journal of Applied Behavior Analysis can be found at http://www.ncbi.nlm.nih.gov/pmc/journals/309/) Write a short summary of the study.
- Practice: Design a simple single-subject study (using either a reversal or multiple-baseline design) to answer the following questions. Be sure to specify the treatment, operationally define the dependent variable, decide when and where the observations will be made, and so on.
- Does positive attention from a parent increase a child’s tooth-brushing behavior?
- Does self-testing while studying improve a student’s performance on weekly spelling tests?
- Does regular exercise help relieve depression?
- Practice: Create a graph that displays the hypothetical results for the study you designed in Exercise 1. Write a paragraph in which you describe what the results show. Be sure to comment on level, trend, and latency.
- Discussion: Imagine you have conducted a single-subject study showing a positive effect of a treatment on the behavior of a man with social anxiety disorder. Your research has been criticized on the grounds that it cannot be generalized to others. How could you respond to this criticism?
- Discussion: Imagine you have conducted a group study showing a positive effect of a treatment on the behavior of a group of people with social anxiety disorder, but your research has been criticized on the grounds that “average” effects cannot be generalized to individuals. How could you respond to this criticism?
- Practice: Redesign as a group study the study by Hall and his colleagues described at the beginning of this chapter, and list the strengths and weaknesses of your new study compared with the original study.
- Practice: The generation effect refers to the fact that people who generate information as they are learning it (e.g., by self-testing) recall it better later than do people who simply review information. Design a single-subject study on the generation effect applied to university students learning brain anatomy.
- Wolf, M. (1976). Social validity: The case for subjective measurement or how applied behavior analysis is finding its heart. Journal of Applied Behavior Analysis, 11, 203–214. ↵
- Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. New York, NY: Appleton-Century-Crofts. ↵
- Baer, D. M., Wolf, M. M., & Risley, T. R. (1968). Some current dimensions of applied behavior analysis. Journal of Applied Behavior Analysis, 1, 91–97. ↵
- Kazdin, A. E. (1982). Single-case research designs: Methods for clinical and applied settings. New York, NY: Oxford University Press. ↵
- Sidman, M. (1960). Tactics of scientific research: Evaluating experimental data in psychology. Boston, MA: Authors Cooperative. ↵
- Ross, S. W., & Horner, R. H. (2009). Bully prevention in positive behavior support. Journal of Applied Behavior Analysis, 42, 747–759. ↵
- Fisch, G. S. (2001). Evaluating data from behavioral analysis: Visual inspection or statistical models. Behavioral Processes, 54, 137–154. ↵
- Scruggs, T. E., & Mastropieri, M. A. (2001). How to summarize single-participant research: Ideas and applications. Exceptionality, 9, 227–244. ↵
- Danov, S. E., & Symons, F. E. (2008). A survey evaluation of the reliability of visual inspection and functional analysis graphs. Behavior Modification, 32, 828–839. ↵
- Scruggs, T. E., & Mastropieri, M. A. (2001). How to summarize single-participant research: Ideas and applications. Exceptionality, 9, 227–244. ↵
- Shadish, W. R., Cook, T. D., & Campbell, D. T. (2002). Experimental and quasi-experimental designs for generalized causal inference. Boston, MA: Houghton Mifflin. ↵
- Kazdin, A. E. (1982). Single-case research designs: Methods for clinical and applied settings. New York, NY: Oxford University Press. ↵
- Dehaene, S. (2011). The number sense: How the mind creates mathematics (2nd ed.). New York, NY: Oxford. ↵
Chapter Outline
- Developing your theoretical framework
- Conceptual definitions
- Inductive & deductive reasoning
- Nomothetic causal explanations
Content warning: examples in this chapter include references to sexual harassment, domestic violence, gender-based violence, the child welfare system, substance use disorders, neonatal abstinence syndrome, child abuse, racism, and sexism.
11.1 Developing your theoretical framework
Learning Objectives
Learners will be able to...
- Differentiate between theories that explain specific parts of the social world versus those that are more broad and sweeping in their conclusions
- Identify the theoretical perspectives that are relevant to your project and inform your thinking about it
- Define key concepts in your working question and develop a theoretical framework for how you understand your topic.
Theories provide a way of looking at the world and of understanding human interaction. Paradigms are grounded in big assumptions about the world—what is real, how do we create knowledge—whereas theories describe more specific phenomena. Well, we are still oversimplifying a bit. Some theories try to explain the whole world, while others only try to explain a small part. Some theories can be grouped together based on common ideas but retain their own individual and unique features. Our goal is to help you find a theoretical framework that helps you understand your topic more deeply and answer your working question.
Theories: Big and small
In your human behavior and the social environment (HBSE) class, you were introduced to the major theoretical perspectives that are commonly used in social work. These are what we like to call big-T 'T'heories. When you read about systems theory, you are actually reading a synthesis of decades of distinct, overlapping, and conflicting theories that can be broadly classified within systems theory. For example, within systems theory, some approaches focus more on family systems while others focus on environmental systems, though the core concepts remain similar.
Different theorists define concepts in their own way, and as a result, their theories may explore different relationships with those concepts. For example, Deci and Ryan's (1985)[1] self-determination theory discusses motivation and establishes that it is contingent on meeting one's needs for autonomy, competency, and relatedness. By contrast, ecological self-determination theory, as written by Abery & Stancliffe (1996),[2] argues that self-determination is the amount of control exercised by an individual over aspects of their lives they deem important across the micro, meso, and macro levels. If self-determination were an important concept in your study, you would need to figure out which of the many theories related to self-determination helps you address your working question.
Theories can provide a broad perspective on the key concepts and relationships in the world or more specific and applied concepts and perspectives. Table 7.2 summarizes two commonly used lists of big-T Theoretical perspectives in social work. See if you can locate some of the theories that might inform your project.
| Payne's (2014)[3] practice theories | Hutchison's (2014)[4] theoretical perspectives |
| Psychodynamic | Systems |
| Crisis and task-centered | Conflict |
| Cognitive-behavioral | Exchange and choice |
| Systems/ecological | Social constructionist |
| Macro practice/social development/social pedagogy | Psychodynamic |
| Strengths/solution/narrative | Developmental |
| Humanistic/existential/spiritual | Social behavioral |
| Critical | Humanistic |
| Feminist | |
| Anti-discriminatory/multi-cultural sensitivity |

Competing theoretical explanations
Within each area of specialization in social work, there are many other theories that aim to explain more specific types of interactions. For example, within the study of sexual harassment, different theories posit different explanations for why harassment occurs.
One theory, first developed by criminologists, is called routine activities theory. It posits that sexual harassment is most likely to occur when a workplace lacks unified groups and when potentially vulnerable targets and motivated offenders are both present (DeCoster, Estes, & Mueller, 1999).[5]
Other theories of sexual harassment, called relational theories, suggest that one's existing relationships are the key to understanding why and how workplace sexual harassment occurs and how people will respond when it does occur (Morgan, 1999).[6] Relational theories focus on the power that different social relationships provide (e.g., married people who have supportive partners at home might be more likely than those who lack support at home to report sexual harassment when it occurs).
Finally, feminist theories of sexual harassment take a different stance. These theories posit that the organization of our current gender system, wherein those who are the most masculine have the most power, best explains the occurrence of workplace sexual harassment (MacKinnon, 1979).[7] As you might imagine, which theory a researcher uses to examine the topic of sexual harassment will shape the questions asked about harassment. It will also shape the explanations the researcher provides for why harassment occurs.
For a graduate student beginning their study of a new topic, it may be intimidating to learn that there are so many theories beyond what you’ve learned in your theory classes. What’s worse is that there is no central database of theories on your topic. However, as you review the literature in your area, you will learn more about the theories scientists have created to explain how your topic works in the real world. There are other good sources for theories, in addition to journal articles. Books often contain works of theoretical and philosophical importance that are beyond the scope of an academic journal. Do a search in your university library for books on your topic, and you are likely to find theorists talking about how to make sense of your topic. You don't necessarily have to agree with the prevailing theories about your topic, but you do need to be aware of them so you can apply theoretical ideas to your project.
Applying big-T theories to your topic
The key to applying theories to your topic is learning the key concepts associated with that theory and the relationships between those concepts, or propositions. Again, your HBSE class should have prepared you with some of the most important concepts from the theoretical perspectives listed in Table 7.2. For example, the conflict perspective sees the world as divided into dominant and oppressed groups who engage in conflict over resources. If you were applying these theoretical ideas to your project, you would need to identify which groups in your project are considered dominant or oppressed groups, and which resources they were struggling over. This is a very general example. Challenge yourself to find small-t theories about your topic that will help you understand it in much greater detail and specificity. If you have chosen a topic that is relevant to your life and future practice, you will be doing valuable work shaping your ideas towards social work practice.
Integrating theory into your project can be easy, or it can take a bit more effort. Some people have a strong and explicit theoretical perspective that they carry with them at all times. For me, you'll probably see my work drawing from exchange and choice, social constructionist, and critical theory. Maybe you have theoretical perspectives you naturally employ, like Afrocentric theory or person-centered practice. If so, that's a great place to start since you might already be using that theory (even subconsciously) to inform your understanding of your topic. But if you aren't aware of whether you are using a theoretical perspective when you think about your topic, try writing a paragraph off the top of your head or talking with a friend explaining what you think about that topic. Try matching it with some of the ideas from the broad theoretical perspectives from Table 7.2. This can ground you as you search for more specific theories. Some studies are designed to test whether theories apply the real world while others are designed to create new theories or variations on existing theories. Consider which feels more appropriate for your project and what you want to know.
Another way to easily identify the theories associated with your topic is to look at the concepts in your working question. Are these concepts commonly found in any of the theoretical perspectives in Table 7.2? Take a look at the Payne and Hutchison texts and see if any of those look like the concepts and relationships in your working question or if any of them match with how you think about your topic. Even if they don't possess the exact same wording, similar theories can help serve as a starting point to finding other theories that can inform your project. Remember, HBSE textbooks will give you not only the broad statements of theories but also sources from specific theorists and sub-theories that might be more applicable to your topic. Skim the references and suggestions for further reading once you find something that applies well.
Exercises
Choose a theoretical perspective from Hutchison, Payne, or another theory textbook that is relevant to your project. Using their textbooks or other reputable sources, identify :
- At least five important concepts from the theory
- What relationships the theory establishes between these important concepts (e.g., as x increases, the y decreases)
- How you can use this theory to better understand the concepts and variables in your project?
Developing your own theoretical framework
Hutchison's and Payne's frameworks are helpful for surveying the whole body of literature relevant to social work, which is why they are so widely used. They are one framework, or way of thinking, about all of the theories social workers will encounter that are relevant to practice. Social work researchers should delve further and develop a theoretical or conceptual framework of their own based on their reading of the literature. In Chapter 8, we will develop your theoretical framework further, identifying the cause-and-effect relationships that answer your working question. Developing a theoretical framework is also instructive for revising and clarifying your working question and identifying concepts that serve as keywords for additional literature searching. The greater clarity you have with your theoretical perspective, the easier each subsequent step in the research process will be.
Getting acquainted with the important theoretical concepts in a new area can be challenging. While social work education provides a broad overview of social theory, you will find much greater fulfillment out of reading about the theories related to your topic area. We discussed some strategies for finding theoretical information in Chapter 3 as part of literature searching. To extend that conversation a bit, some strategies for searching for theories in the literature include:
- Using keywords like "theory," "conceptual," or "framework" in queries to better target the search at sources that talk about theory.
- Consider searching for these keywords in the title or abstract, specifically
- Looking at the references and cited by links within theoretical articles and textbooks
- Looking at books, edited volumes, and textbooks that discuss theory
- Talking with a scholar on your topic, or asking a professor if they can help connect you to someone
- Looking at how researchers use theory in their research projects
- Nice authors are clear about how they use theory to inform their research project, usually in the introduction and discussion section.
- Starting with a Big-T Theory and looking for sub-theories or specific theorists that directly address your topic area
- For example, from the broad umbrella of systems theory, you might pick out family systems theory if you want to understand the effectiveness of a family counseling program.
It's important to remember that knowledge arises within disciplines, and that disciplines have different theoretical frameworks for explaining the same topic. While it is certainly important for the social work perspective to be a part of your analysis, social workers benefit from searching across disciplines to come to a more comprehensive understanding of the topic. Reaching across disciplines can provide uncommon insights during conceptualization, and once the study is completed, a multidisciplinary researcher will be able to share results in a way that speaks to a variety of audiences. A study by An and colleagues (2015)[8] uses game theory from the discipline of economics to understand problems in the Temporary Assistance for Needy Families (TANF) program. In order to receive TANF benefits, mothers must cooperate with paternity and child support requirements unless they have "good cause," as in cases of domestic violence, in which providing that information would put the mother at greater risk of violence. Game theory can help us understand how TANF recipients and caseworkers respond to the incentives in their environment, and highlight why the design of the "good cause" waiver program may not achieve its intended outcome of increasing access to benefits for survivors of family abuse.
Of course, there are natural limits on the depth with which student researchers can and should engage in a search for theory about their topic. At minimum, you should be able to draw connections across studies and be able to assess the relative importance of each theory within the literature. Just because you found one article applying your theory (like game theory, in our example above) does not mean it is important or often used in the domestic violence literature. Indeed, it would be much more common in the family violence literature to find psychological theories of trauma, feminist theories of power and control, and similar theoretical perspectives used to inform research projects rather than game theory, which is equally applicable to survivors of family violence as workers and bosses at a corporation. Consider using the Cited By feature to identify articles, books, and other sources of theoretical information that are seminal or well-cited in the literature. Similarly, by using the name of a theory in the keywords of a search query (along with keywords related to your topic), you can get a sense of how often the theory is used in your topic area. You should have a sense of what theories are commonly used to analyze your topic, even if you end up choosing a different one to inform your project.

Theories that are not cited or used as often are still immensely valuable. As we saw before with TANF and "good cause" waivers, using theories from other disciplines can produce uncommon insights and help you make a new contribution to the social work literature. Given the privileged position that the social work curriculum places on theories developed by white men, students may want to explore Afrocentricity as a social work practice theory (Pellebon, 2007)[9] or abolitionist social work (Jacobs et al., 2021)[10] when deciding on a theoretical framework for their research project that addresses concepts of racial justice. Start with your working question, and explain how each theory helps you answer your question. Some explanations are going to feel right, and some concepts will feel more salient to you than others. Keep in mind that this is an iterative process. Your theoretical framework will likely change as you continue to conceptualize your research project, revise your research question, and design your study.
By trying on many different theoretical explanations for your topic area, you can better clarify your own theoretical framework. Some of you may be fortunate enough to find theories that match perfectly with how you think about your topic, are used often in the literature, and are therefore relatively straightforward to apply. However, many of you may find that a combination of theoretical perspectives is most helpful for you to investigate your project. For example, maybe the group counseling program for which you are evaluating client outcomes draws from both motivational interviewing and cognitive behavioral therapy. In order to understand the change happening in the client population, you would need to know each theory separately as well as how they work in tandem with one another. Because theoretical explanations and even the definitions of concepts are debated by scientists, it may be helpful to find a specific social scientist or group of scientists whose perspective on the topic you find matches with your understanding of the topic. Of course, it is also perfectly acceptable to develop your own theoretical framework, though you should be able to articulate how your framework fills a gap within the literature.
If you are adapting theoretical perspectives in your study, it is important to clarify the original authors' definitions of each concept. Jabareen (2009)[11] offers that conceptual frameworks are not merely collections of concepts but, rather, constructs in which each concept plays an integral role.[12] A conceptual framework is a network of linked concepts that together provide a comprehensive understanding of a phenomenon. Each concept in a conceptual framework plays an ontological or epistemological role in the framework, and it is important to assess whether the concepts and relationships in your framework make sense together. As your framework takes shape, you will find yourself integrating and grouping together concepts, thinking about the most important or least important concepts, and how each concept is causally related to others.
Much like paradigm, theory plays a supporting role for the conceptualization of your research project. Recall the ice float from Figure 7.1. Theoretical explanations support the design and methods you use to answer your research question. In student projects that lack a theoretical framework, I often see the biases and errors in reasoning that we discussed in Chapter 1 that get in the way of good social science. That's because theories mark which concepts are important, provide a framework for understanding them, and measure their interrelationships. If you are missing this foundation, you will operate on informal observation, messages from authority, and other forms of unsystematic and unscientific thinking we reviewed in Chapter 1.
Theory-informed inquiry is incredibly helpful for identifying key concepts and how to measure them in your research project, but there is a risk in aligning research too closely with theory. The theory-ladenness of facts and observations produced by social science research means that we may be making our ideas real through research. This is a potential source of confirmation bias in social science. Moreover, as Tan (2016)[13] demonstrates, social science often proceeds by adopting as true the perspective of Western and Global North countries, and cross-cultural research is often when ethnocentric and biased ideas are most visible. In her example, a researcher from the West studying teacher-centric classrooms in China that rely partially on rote memorization may view them as less advanced than student-centered classrooms developed in a Western country simply because of Western philosophical assumptions about the importance of individualism and self-determination. Developing a clear theoretical framework is a way to guard against biased research, and it will establish a firm foundation on which you will develop the design and methods for your study.
Key Takeaways
- Just as empirical evidence is important for conceptualizing a research project, so too are the key concepts and relationships identified by social work theory.
- Using theory your theory textbook will provide you with a sense of the broad theoretical perspectives in social work that might be relevant to your project.
- Try to find small-t theories that are more specific to your topic area and relevant to your working question.
Exercises
- In Chapter 2, you developed a concept map for your proposal. Take a moment to revisit your concept map now as your theoretical framework is taking shape. Make any updates to the key concepts and relationships in your concept map.
. If you need a refresher, we have embedded a short how-to video from the University of Guelph Library (CC-BY-NC-SA 4.0) that we also used in Chapter 2.
11.2 Conceptual definitions
Learning Objectives
Learners will be able to...
- Define measurement and conceptualization
- Apply Kaplan’s three categories to determine the complexity of measuring a given variable
- Identify the role previous research and theory play in defining concepts
- Distinguish between unidimensional and multidimensional concepts
- Critically apply reification to how you conceptualize the key variables in your research project
In social science, when we use the term measurement, we mean the process by which we describe and ascribe meaning to the key facts, concepts, or other phenomena that we are investigating. At its core, measurement is about defining one’s terms in as clear and precise a way as possible. Of course, measurement in social science isn’t quite as simple as using a measuring cup or spoon, but there are some basic tenets on which most social scientists agree when it comes to measurement. We’ll explore those, as well as some of the ways that measurement might vary depending on your unique approach to the study of your topic.
An important point here is that measurement does not require any particular instruments or procedures. What it does require is a systematic procedure for assigning scores, meanings, and descriptions to individuals or objects so that those scores represent the characteristic of interest. You can measure phenomena in many different ways, but you must be sure that how you choose to measure gives you information and data that lets you answer your research question. If you're looking for information about a person's income, but your main points of measurement have to do with the money they have in the bank, you're not really going to find the information you're looking for!
The question of what social scientists measure can be answered by asking yourself what social scientists study. Think about the topics you’ve learned about in other social work classes you’ve taken or the topics you’ve considered investigating yourself. Let’s consider Melissa Milkie and Catharine Warner’s study (2011)[14] of first graders’ mental health. In order to conduct that study, Milkie and Warner needed to have some idea about how they were going to measure mental health. What does mental health mean, exactly? And how do we know when we’re observing someone whose mental health is good and when we see someone whose mental health is compromised? Understanding how measurement works in research methods helps us answer these sorts of questions.
As you might have guessed, social scientists will measure just about anything that they have an interest in investigating. For example, those who are interested in learning something about the correlation between social class and levels of happiness must develop some way to measure both social class and happiness. Those who wish to understand how well immigrants cope in their new locations must measure immigrant status and coping. Those who wish to understand how a person’s gender shapes their workplace experiences must measure gender and workplace experiences (and get more specific about which experiences are under examination). You get the idea. Social scientists can and do measure just about anything you can imagine observing or wanting to study. Of course, some things are easier to observe or measure than others.

Observing your variables
In 1964, philosopher Abraham Kaplan (1964)[15] wrote The Conduct of Inquiry, which has since become a classic work in research methodology (Babbie, 2010).[16] In his text, Kaplan describes different categories of things that behavioral scientists observe. One of those categories, which Kaplan called “observational terms,” is probably the simplest to measure in social science. Observational terms are the sorts of things that we can see with the naked eye simply by looking at them. Kaplan roughly defines them as conditions that are easy to identify and verify through direct observation. If, for example, we wanted to know how the conditions of playgrounds differ across different neighborhoods, we could directly observe the variety, amount, and condition of equipment at various playgrounds.
Indirect observables, on the other hand, are less straightforward to assess. In Kaplan's framework, they are conditions that are subtle and complex that we must use existing knowledge and intuition to define. If we conducted a study for which we wished to know a person’s income, we’d probably have to ask them their income, perhaps in an interview or a survey. Thus, we have observed income, even if it has only been observed indirectly. Birthplace might be another indirect observable. We can ask study participants where they were born, but chances are good we won’t have directly observed any of those people being born in the locations they report.
Sometimes the measures that we are interested in are more complex and more abstract than observational terms or indirect observables. Think about some of the concepts you’ve learned about in other social work classes—for example, ethnocentrism. What is ethnocentrism? Well, from completing an introduction to social work class you might know that it has something to do with the way a person judges another’s culture. But how would you measure it? Here’s another construct: bureaucracy. We know this term has something to do with organizations and how they operate but measuring such a construct is trickier than measuring something like a person’s income. The theoretical concepts of ethnocentrism and bureaucracy represent ideas whose meanings we have come to agree on. Though we may not be able to observe these abstractions directly, we can observe their components.
Kaplan referred to these more abstract things that behavioral scientists measure as constructs. Constructs are “not observational either directly or indirectly” (Kaplan, 1964, p. 55),[17] but they can be defined based on observables. For example, the construct of bureaucracy could be measured by counting the number of supervisors that need to approve routine spending by public administrators. The greater the number of administrators that must sign off on routine matters, the greater the degree of bureaucracy. Similarly, we might be able to ask a person the degree to which they trust people from different cultures around the world and then assess the ethnocentrism inherent in their answers. We can measure constructs like bureaucracy and ethnocentrism by defining them in terms of what we can observe.[18]
The idea of coming up with your own measurement tool might sound pretty intimidating at this point. The good news is that if you find something in the literature that works for you, you can use it (with proper attribution, of course). If there are only pieces of it that you like, you can reuse those pieces (with proper attribution and describing/justifying any changes). You don't always have to start from scratch!
Exercises
Look at the variables in your research question.
- Classify them as direct observables, indirect observables, or constructs.
- Do you think measuring them will be easy or hard?
- What are your first thoughts about how to measure each variable? No wrong answers here, just write down a thought about each variable.

Measurement starts with conceptualization
In order to measure the concepts in your research question, we first have to understand what we think about them. As an aside, the word concept has come up quite a bit, and it is important to be sure we have a shared understanding of that term. A concept is the notion or image that we conjure up when we think of some cluster of related observations or ideas. For example, masculinity is a concept. What do you think of when you hear that word? Presumably, you imagine some set of behaviors and perhaps even a particular style of self-presentation. Of course, we can’t necessarily assume that everyone conjures up the same set of ideas or images when they hear the word masculinity. While there are many possible ways to define the term and some may be more common or have more support than others, there is no universal definition of masculinity. What counts as masculine may shift over time, from culture to culture, and even from individual to individual (Kimmel, 2008). This is why defining our concepts is so important.\
Not all researchers clearly explain their theoretical or conceptual framework for their study, but they should! Without understanding how a researcher has defined their key concepts, it would be nearly impossible to understand the meaning of that researcher’s findings and conclusions. Back in Chapter 7, you developed a theoretical framework for your study based on a survey of the theoretical literature in your topic area. If you haven't done that yet, consider flipping back to that section to familiarize yourself with some of the techniques for finding and using theories relevant to your research question. Continuing with our example on masculinity, we would need to survey the literature on theories of masculinity. After a few queries on masculinity, I found a wonderful article by Wong (2010)[19] that analyzed eight years of the journal Psychology of Men & Masculinity and analyzed how often different theories of masculinity were used. Not only can I get a sense of which theories are more accepted and which are more marginal in the social science on masculinity, I am able to identify a range of options from which I can find the theory or theories that will inform my project.
Exercises
Identify a specific theory (or more than one theory) and how it helps you understand...
- Your independent variable(s).
- Your dependent variable(s).
- The relationship between your independent and dependent variables.
Rather than completing this exercise from scratch, build from your theoretical or conceptual framework developed in previous chapters.
In quantitative methods, conceptualization involves writing out clear, concise definitions for our key concepts. These are the kind of definitions you are used to, like the ones in a dictionary. A conceptual definition involves defining a concept in terms of other concepts, usually by making reference to how other social scientists and theorists have defined those concepts in the past. Of course, new conceptual definitions are created all the time because our conceptual understanding of the world is always evolving.
Conceptualization is deceptively challenging—spelling out exactly what the concepts in your research question mean to you. Following along with our example, think about what comes to mind when you read the term masculinity. How do you know masculinity when you see it? Does it have something to do with men or with social norms? If so, perhaps we could define masculinity as the social norms that men are expected to follow. That seems like a reasonable start, and at this early stage of conceptualization, brainstorming about the images conjured up by concepts and playing around with possible definitions is appropriate. However, this is just the first step. At this point, you should be beyond brainstorming for your key variables because you have read a good amount of research about them
In addition, we should consult previous research and theory to understand the definitions that other scholars have already given for the concepts we are interested in. This doesn’t mean we must use their definitions, but understanding how concepts have been defined in the past will help us to compare our conceptualizations with how other scholars define and relate concepts. Understanding prior definitions of our key concepts will also help us decide whether we plan to challenge those conceptualizations or rely on them for our own work. Finally, working on conceptualization is likely to help in the process of refining your research question to one that is specific and clear in what it asks. Conceptualization and operationalization (next section) are where "the rubber meets the road," so to speak, and you have to specify what you mean by the question you are asking. As your conceptualization deepens, you will often find that your research question becomes more specific and clear.
If we turn to the literature on masculinity, we will surely come across work by Michael Kimmel, one of the preeminent masculinity scholars in the United States. After consulting Kimmel’s prior work (2000; 2008),[20] we might tweak our initial definition of masculinity. Rather than defining masculinity as “the social norms that men are expected to follow,” perhaps instead we’ll define it as “the social roles, behaviors, and meanings prescribed for men in any given society at any one time” (Kimmel & Aronson, 2004, p. 503).[21] Our revised definition is more precise and complex because it goes beyond addressing one aspect of men’s lives (norms), and addresses three aspects: roles, behaviors, and meanings. It also implies that roles, behaviors, and meanings may vary across societies and over time. Using definitions developed by theorists and scholars is a good idea, though you may find that you want to define things your own way.
As you can see, conceptualization isn’t as simple as applying any random definition that we come up with to a term. Defining our terms may involve some brainstorming at the very beginning. But conceptualization must go beyond that, to engage with or critique existing definitions and conceptualizations in the literature. Once we’ve brainstormed about the images associated with a particular word, we should also consult prior work to understand how others define the term in question. After we’ve identified a clear definition that we’re happy with, we should make sure that every term used in our definition will make sense to others. Are there terms used within our definition that also need to be defined? If so, our conceptualization is not yet complete. Our definition includes the concept of "social roles," so we should have a definition for what those mean and become familiar with role theory to help us with our conceptualization. If we don't know what roles are, how can we study them?
Let's say we do all of that. We have a clear definition of the term masculinity with reference to previous literature and we also have a good understanding of the terms in our conceptual definition...then we're done, right? Not so fast. You’ve likely met more than one man in your life, and you’ve probably noticed that they are not the same, even if they live in the same society during the same historical time period. This could mean there are dimensions of masculinity. In terms of social scientific measurement, concepts can be said to have multiple dimensions when there are multiple elements that make up a single concept. With respect to the term masculinity, dimensions could based on gender identity, gender performance, sexual orientation, etc.. In any of these cases, the concept of masculinity would be considered to have multiple dimensions.
While you do not need to spell out every possible dimension of the concepts you wish to measure, it is important to identify whether your concepts are unidimensional (and therefore relatively easy to define and measure) or multidimensional (and therefore require multi-part definitions and measures). In this way, how you conceptualize your variables determines how you will measure them in your study. Unidimensional concepts are those that are expected to have a single underlying dimension. These concepts can be measured using a single measure or test. Examples include simple concepts such as a person’s weight, time spent sleeping, and so forth.
One frustrating this is that there is no clear demarcation between concepts that are inherently unidimensional or multidimensional. Even something as simple as age could be broken down into multiple dimensions including mental age and chronological age, so where does conceptualization stop? How far down the dimensional rabbit hole do we have to go? Researchers should consider two things. First, how important is this variable in your study? If age is not important in your study (maybe it is a control variable), it seems like a waste of time to do a lot of work drawing from developmental theory to conceptualize this variable. A unidimensional measure from zero to dead is all the detail we need. On the other hand, if we were measuring the impact of age on masculinity, conceptualizing our independent variable (age) as multidimensional may provide a richer understanding of its impact on masculinity. Finally, your conceptualization will lead directly to your operationalization of the variable, and once your operationalization is complete, make sure someone reading your study could follow how your conceptual definitions informed the measures you chose for your variables.
Exercises
Write a conceptual definition for your independent and dependent variables.
- Cite and attribute definitions to other scholars, if you use their words.
- Describe how your definitions are informed by your theoretical framework.
- Place your definition in conversation with other theories and conceptual definitions commonly used in the literature.
- Are there multiple dimensions of your variables?
- Are any of these dimensions important for you to measure?

Do researchers actually know what we're talking about?
Conceptualization proceeds differently in qualitative research compared to quantitative research. Since qualitative researchers are interested in the understandings and experiences of their participants, it is less important for them to find one fixed definition for a concept before starting to interview or interact with participants. The researcher’s job is to accurately and completely represent how their participants understand a concept, not to test their own definition of that concept.
If you were conducting qualitative research on masculinity, you would likely consult previous literature like Kimmel’s work mentioned above. From your literature review, you may come up with a working definition for the terms you plan to use in your study, which can change over the course of the investigation. However, the definition that matters is the definition that your participants share during data collection. A working definition is merely a place to start, and researchers should take care not to think it is the only or best definition out there.
In qualitative inquiry, your participants are the experts (sound familiar, social workers?) on the concepts that arise during the research study. Your job as the researcher is to accurately and reliably collect and interpret their understanding of the concepts they describe while answering your questions. Conceptualization of concepts is likely to change over the course of qualitative inquiry, as you learn more information from your participants. Indeed, getting participants to comment on, extend, or challenge the definitions and understandings of other participants is a hallmark of qualitative research. This is the opposite of quantitative research, in which definitions must be completely set in stone before the inquiry can begin.
The contrast between qualitative and quantitative conceptualization is instructive for understanding how quantitative methods (and positivist research in general) privilege the knowledge of the researcher over the knowledge of study participants and community members. Positivism holds that the researcher is the "expert," and can define concepts based on their expert knowledge of the scientific literature. This knowledge is in contrast to the lived experience that participants possess from experiencing the topic under examination day-in, day-out. For this reason, it would be wise to remind ourselves not to take our definitions too seriously and be critical about the limitations of our knowledge.
Conceptualization must be open to revisions, even radical revisions, as scientific knowledge progresses. While I’ve suggested consulting prior scholarly definitions of our concepts, you should not assume that prior, scholarly definitions are more real than the definitions we create. Likewise, we should not think that our own made-up definitions are any more real than any other definition. It would also be wrong to assume that just because definitions exist for some concept that the concept itself exists beyond some abstract idea in our heads. Building on the paradigmatic ideas behind interpretivism and the critical paradigm, researchers call the assumption that our abstract concepts exist in some concrete, tangible way is known as reification. It explores the power dynamics behind how we can create reality by how we define it.
Returning again to our example of masculinity. Think about our how our notions of masculinity have developed over the past few decades, and how different and yet so similar they are to patriarchal definitions throughout history. Conceptual definitions become more or less popular based on the power arrangements inside of social science the broader world. Western knowledge systems are privileged, while others are viewed as unscientific and marginal. The historical domination of social science by white men from WEIRD countries meant that definitions of masculinity were imbued their cultural biases and were designed explicitly and implicitly to preserve their power. This has inspired movements for cognitive justice as we seek to use social science to achieve global development.
Key Takeaways
- Measurement is the process by which we describe and ascribe meaning to the key facts, concepts, or other phenomena that we are investigating.
- Kaplan identified three categories of things that social scientists measure including observational terms, indirect observables, and constructs.
- Some concepts have multiple elements or dimensions.
- Researchers often use measures previously developed and studied by other researchers.
- Conceptualization is a process that involves coming up with clear, concise definitions.
- Conceptual definitions are based on the theoretical framework you are using for your study (and the paradigmatic assumptions underlying those theories).
- Whether your conceptual definitions come from your own ideas or the literature, you should be able to situate them in terms of other commonly used conceptual definitions.
- Researchers should acknowledge the limited explanatory power of their definitions for concepts and how oppression can shape what explanations are considered true or scientific.
Exercises
Think historically about the variables in your research question.
- How has our conceptual definition of your topic changed over time?
- What scholars or social forces were responsible for this change?
Take a critical look at your conceptual definitions.
- How participants might define terms for themselves differently, in terms of their daily experience?
- On what cultural assumptions are your conceptual definitions based?
- Are your conceptual definitions applicable across all cultures that will be represented in your sample?
11.3 Inductive and deductive reasoning
Learning Objectives
Learners will be able to...
- Describe inductive and deductive reasoning and provide examples of each
- Identify how inductive and deductive reasoning are complementary
Congratulations! You survived the chapter on theories and paradigms. My experience has been that many students have a difficult time thinking about theories and paradigms because they perceive them as "intangible" and thereby hard to connect to social work research. I even had one student who said she got frustrated just reading the word "philosophy."
Rest assured, you do not need to become a theorist or philosopher to be an effective social worker or researcher. However, you should have a good sense of what theory or theories will be relevant to your project, as well as how this theory, along with your working question, fit within the three broad research paradigms we reviewed. If you don't have a good idea about those at this point, it may be a good opportunity to pause and read more about the theories related to your topic area.
Theories structure and inform social work research. The converse is also true: research can structure and inform theory. The reciprocal relationship between theory and research often becomes evident to students when they consider the relationships between theory and research in inductive and deductive approaches to research. In both cases, theory is crucial. But the relationship between theory and research differs for each approach.
While inductive and deductive approaches to research are quite different, they can also be complementary. Let’s start by looking at each one and how they differ from one another. Then we’ll move on to thinking about how they complement one another.
Inductive reasoning
A researcher using inductive reasoning begins by collecting data that is relevant to their topic of interest. Once a substantial amount of data have been collected, the researcher will then step back from data collection to get a bird’s eye view of their data. At this stage, the researcher looks for patterns in the data, working to develop a theory that could explain those patterns. Thus, when researchers take an inductive approach, they start with a particular set of observations and move to a more general set of propositions about those experiences. In other words, they move from data to theory, or from the specific to the general. Figure 8.1 outlines the steps involved with an inductive approach to research.

There are many good examples of inductive research, but we’ll look at just a few here. One fascinating study in which the researchers took an inductive approach is Katherine Allen, Christine Kaestle, and Abbie Goldberg’s (2011)[22] study of how boys and young men learn about menstruation. To understand this process, Allen and her colleagues analyzed the written narratives of 23 young cisgender men in which the men described how they learned about menstruation, what they thought of it when they first learned about it, and what they think of it now. By looking for patterns across all 23 cisgender men’s narratives, the researchers were able to develop a general theory of how boys and young men learn about this aspect of girls’ and women’s biology. They conclude that sisters play an important role in boys’ early understanding of menstruation, that menstruation makes boys feel somewhat separated from girls, and that as they enter young adulthood and form romantic relationships, young men develop more mature attitudes about menstruation. Note how this study began with the data—men’s narratives of learning about menstruation—and worked to develop a theory.
In another inductive study, Kristin Ferguson and colleagues (Ferguson, Kim, & McCoy, 2011)[23] analyzed empirical data to better understand how to meet the needs of young people who are homeless. The authors analyzed focus group data from 20 youth at a homeless shelter. From these data they developed a set of recommendations for those interested in applied interventions that serve homeless youth. The researchers also developed hypotheses for others who might wish to conduct further investigation of the topic. Though Ferguson and her colleagues did not test their hypotheses, their study ends where most deductive investigations begin: with a theory and a hypothesis derived from that theory. Section 8.4 discusses the use of mixed methods research as a way for researchers to test hypotheses created in a previous component of the same research project.
You will notice from both of these examples that inductive reasoning is most commonly found in studies using qualitative methods, such as focus groups and interviews. Because inductive reasoning involves the creation of a new theory, researchers need very nuanced data on how the key concepts in their working question operate in the real world. Qualitative data is often drawn from lengthy interactions and observations with the individuals and phenomena under examination. For this reason, inductive reasoning is most often associated with qualitative methods, though it is used in both quantitative and qualitative research.
Deductive reasoning
If inductive reasoning is about creating theories from raw data, deductive reasoning is about testing theories using data. Researchers using deductive reasoning take the steps described earlier for inductive research and reverse their order. They start with a compelling social theory, create a hypothesis about how the world should work, collect raw data, and analyze whether their hypothesis was confirmed or not. That is, deductive approaches move from a more general level (theory) to a more specific (data); whereas inductive approaches move from the specific (data) to general (theory).
A deductive approach to research is the one that people typically associate with scientific investigation. Students in English-dominant countries that may be confused by inductive vs. deductive research can rest part of the blame on Sir Arthur Conan Doyle, creator of the Sherlock Holmes character. As Craig Vasey points out in his breezy introduction to logic book chapter, Sherlock Holmes more often used inductive rather than deductive reasoning (despite claiming to use the powers of deduction to solve crimes). By noticing subtle details in how people act, behave, and dress, Holmes finds patterns that others miss. Using those patterns, he creates a theory of how the crime occurred, dramatically revealed to the authorities just in time to arrest the suspect. Indeed, it is these flashes of insight into the patterns of data that make Holmes such a keen inductive reasoner. In social work practice, rather than detective work, inductive reasoning is supported by the intuitions and practice wisdom of social workers, just as Holmes' reasoning is sharpened by his experience as a detective.
So, if deductive reasoning isn't Sherlock Holmes' observation and pattern-finding, how does it work? It starts with what you have already done in Chapters 3 and 4, reading and evaluating what others have done to study your topic. It continued with Chapter 5, discovering what theories already try to explain how the concepts in your working question operate in the real world. Tapping into this foundation of knowledge on their topic, the researcher studies what others have done, reads existing theories of whatever phenomenon they are studying, and then tests hypotheses that emerge from those theories. Figure 8.2 outlines the steps involved with a deductive approach to research.

While not all researchers follow a deductive approach, many do. We’ll now take a look at a couple excellentrecent examples of deductive research.
In a study of US law enforcement responses to hate crimes, Ryan King and colleagues (King, Messner, & Baller, 2009)[24] hypothesized that law enforcement’s response would be less vigorous in areas of the country that had a stronger history of racial violence. The authors developed their hypothesis from prior research and theories on the topic. They tested the hypothesis by analyzing data on states’ lynching histories and hate crime responses. Overall, the authors found support for their hypothesis and illustrated an important application of critical race theory.
In another recent deductive study, Melissa Milkie and Catharine Warner (2011)[25] studied the effects of different classroom environments on first graders’ mental health. Based on prior research and theory, Milkie and Warner hypothesized that negative classroom features, such as a lack of basic supplies and heat, would be associated with emotional and behavioral problems in children. One might associate this research with Maslow's hierarchy of needs or systems theory. The researchers found support for their hypothesis, demonstrating that policymakers should be paying more attention to the mental health outcomes of children’s school experiences, just as they track academic outcomes (American Sociological Association, 2011).[26]
Complementary approaches
While inductive and deductive approaches to research seem quite different, they can actually be rather complementary. In some cases, researchers will plan for their study to include multiple components, one inductive and the other deductive. In other cases, a researcher might begin a study with the plan to conduct either inductive or deductive research, but then discovers along the way that the other approach is needed to help illuminate findings. Here is an example of each such case.
Dr. Amy Blackstone (n.d.), author of Principles of sociological inquiry: Qualitative and quantitative methods, relates a story about her mixed methods research on sexual harassment.
We began the study knowing that we would like to take both a deductive and an inductive approach in our work. We therefore administered a quantitative survey, the responses to which we could analyze in order to test hypotheses, and also conducted qualitative interviews with a number of the survey participants. The survey data were well suited to a deductive approach; we could analyze those data to test hypotheses that were generated based on theories of harassment. The interview data were well suited to an inductive approach; we looked for patterns across the interviews and then tried to make sense of those patterns by theorizing about them.
For one paper (Uggen & Blackstone, 2004)[27], we began with a prominent feminist theory of the sexual harassment of adult women and developed a set of hypotheses outlining how we expected the theory to apply in the case of younger women’s and men’s harassment experiences. We then tested our hypotheses by analyzing the survey data. In general, we found support for the theory that posited that the current gender system, in which heteronormative men wield the most power in the workplace, explained workplace sexual harassment—not just of adult women but of younger women and men as well. In a more recent paper (Blackstone, Houle, & Uggen, 2006),[28] we did not hypothesize about what we might find but instead inductively analyzed interview data, looking for patterns that might tell us something about how or whether workers’ perceptions of harassment change as they age and gain workplace experience. From this analysis, we determined that workers’ perceptions of harassment did indeed shift as they gained experience and that their later definitions of harassment were more stringent than those they held during adolescence. Overall, our desire to understand young workers’ harassment experiences fully—in terms of their objective workplace experiences, their perceptions of those experiences, and their stories of their experiences—led us to adopt both deductive and inductive approaches in the work. (Blackstone, n.d., p. 21)[29]
Researchers may not always set out to employ both approaches in their work but sometimes find that their use of one approach leads them to the other. One such example is described eloquently in Russell Schutt’s Investigating the Social World (2006).[30] As Schutt describes, researchers Sherman and Berk (1984)[31] conducted an experiment to test two competing theories of the effects of punishment on deterring deviance (in this case, domestic violence).Specifically, Sherman and Berk hypothesized that deterrence theory (see Williams, 2005[32] for more information on that theory) would provide a better explanation of the effects of arresting accused batterers than labeling theory. Deterrence theory predicts that arresting an accused spouse batterer will reduce future incidents of violence. Conversely, labeling theory predicts that arresting accused spouse batterers will increase future incidents (see Policastro & Payne, 2013[33] for more information on that theory). Figure 8.3 summarizes the two competing theories and the hypotheses Sherman and Berk set out to test.
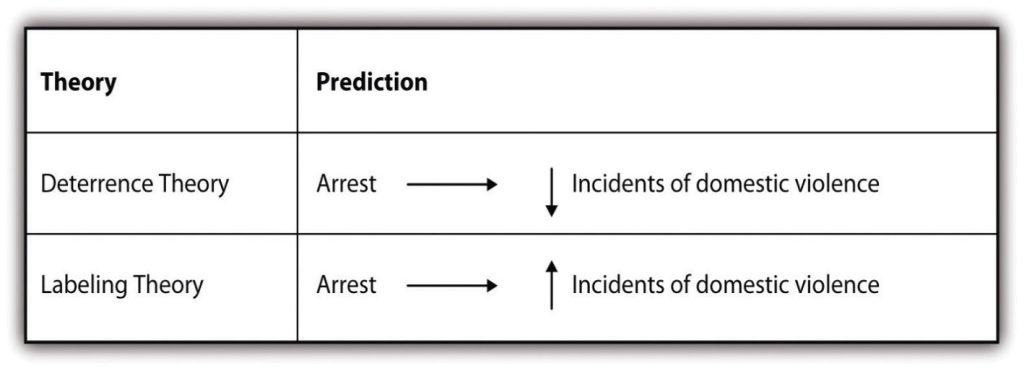
Research from these follow-up studies were mixed. In some cases, arrest deterred future incidents of violence. In other cases, it did not. This left the researchers with new data that they needed to explain. The researchers therefore took an inductive approach in an effort to make sense of their latest empirical observations. The new studies revealed that arrest seemed to have a deterrent effect for those who were married and employed, but that it led to increased offenses for those who were unmarried and unemployed. Researchers thus turned to control theory, which posits that having some stake in conformity through the social ties provided by marriage and employment, as the better explanation (see Davis et al., 2000[35] for more information on this theory).
What the original Sherman and Berk study, along with the follow-up studies, show us is that we might start with a deductive approach to research, but then, if confronted by new data we must make sense of, we may move to an inductive approach. We will expand on these possibilities in section 8.4 when we discuss mixed methods research.
Ethical and critical considerations
Deductive and inductive reasoning, just like other components of the research process comes with ethical and cultural considerations for researchers. Specifically, deductive research is limited by existing theory. Because scientific inquiry has been shaped by oppressive forces such as sexism, racism, and colonialism, what is considered theory is largely based in Western, white-male-dominant culture. Thus, researchers doing deductive research may artificially limit themselves to ideas that were derived from this context. Non-Western researchers, international social workers, and practitioners working with non-dominant groups may find deductive reasoning of limited help if theories do not adequately describe other cultures.
While these flaws in deductive research may make inductive reasoning seem more appealing, on closer inspection you'll find similar issues apply. A researcher using inductive reasoning applies their intuition and lived experience when analyzing participant data. They will take note of particular themes, conceptualize their definition, and frame the project using their unique psychology. Since everyone's internal world is shaped by their cultural and environmental context, inductive reasoning conducted by Western researchers may unintentionally reinforcing lines of inquiry that derive from cultural oppression.
Inductive reasoning is also shaped by those invited to provide the data to be analyzed. For example, I recently worked with a student who wanted to understand the impact of child welfare supervision on children born dependent on opiates and methamphetamine. Due to the potential harm that could come from interviewing families and children who are in foster care or under child welfare supervision, the researcher decided to use inductive reasoning and to only interview child welfare workers.
Talking to practitioners is a good idea for feasibility, as they are less vulnerable than clients. However, any theory that emerges out of these observations will be substantially limited, as it would be devoid of the perspectives of parents, children, and other community members who could provide a more comprehensive picture of the impact of child welfare involvement on children. Notice that each of these groups has less power than child welfare workers in the service relationship. Attending to which groups were used to inform the creation of a theory and the power of those groups is an important critical consideration for social work researchers.
As you can see, when researchers apply theory to research they must wrestle with the history and hierarchy around knowledge creation in that area. In deductive studies, the researcher is positioned as the expert, similar to the positivist paradigm presented in Chapter 5. We've discussed a few of the limitations on the knowledge of researchers in this subsection, but the position of the "researcher as expert" is inherently problematic. However, it should also not be taken to an extreme. A researcher who approaches inductive inquiry as a naïve learner is also inherently problematic. Just as competence in social work practice requires a baseline of knowledge prior to entering practice, so does competence in social work research. Because a truly naïve intellectual position is impossible—we all have preexisting ways we view the world and are not fully aware of how they may impact our thoughts—researchers should be well-read in the topic area of their research study but humble enough to know that there is always much more to learn.
Key Takeaways
- Inductive reasoning begins with a set of empirical observations, seeking patterns in those observations, and then theorizing about those patterns.
- Deductive reasoning begins with a theory, developing hypotheses from that theory, and then collecting and analyzing data to test the truth of those hypotheses.
- Inductive and deductive reasoning can be employed together for a more complete understanding of the research topic.
- Though researchers don’t always set out to use both inductive and deductive reasoning in their work, they sometimes find that new questions arise in the course of an investigation that can best be answered by employing both approaches.
Exercises
- Identify one theory and how it helps you understand your topic and working question.
I encourage you to find a specific theory from your topic area, rather than relying only on the broad theoretical perspectives like systems theory or the strengths perspective. Those broad theoretical perspectives are okay...but I promise that searching for theories about your topic will help you conceptualize and design your research project.
- Using the theory you identified, describe what you expect the answer to be to your working question.
11.4
Learning Objectives
Learners will be able to...
- Define and provide an example of idiographic causal relationships
- Describe the role of causality in quantitative research as compared to qualitative research
- Identify, define, and describe each of the main criteria for nomothetic causal relationships
- Describe the difference between and provide examples of independent, dependent, and control variables
- Define hypothesis, state a clear hypothesis, and discuss the respective roles of quantitative and qualitative research when it comes to hypotheses
Causality refers to the idea that one event, behavior, or belief will result in the occurrence of another, subsequent event, behavior, or belief. In other words, it is about cause and effect. It seems simple, but you may be surprised to learn there is more than one way to explain how one thing causes another. How can that be? How could there be many ways to understand causality?
Think back to our discussion in Section 5.3 on paradigms [insert chapter link plus link to section 1.2]. You’ll remember the positivist paradigm as the one that believes in objectivity. Positivists look for causal explanations that are universally true for everyone, everywhere because they seek objective truth. Interpretivists, on the other hand, look for causal explanations that are true for individuals or groups in a specific time and place because they seek subjective truths. Remember that for interpretivists, there is not one singular truth that is true for everyone, but many truths created and shared by others.
"Are you trying to generalize or nah?"
One of my favorite classroom moments occurred in the early days of my teaching career. Students were providing peer feedback on their working questions. I overheard one group who was helping someone rephrase their research question. A student asked, “Are you trying to generalize or nah?” Teaching is full of fun moments like that one. Answering that one question can help you understand how to conceptualize and design your research project.
Nomothetic causal explanations are incredibly powerful. They allow scientists to make predictions about what will happen in the future, with a certain margin of error. Moreover, they allow scientists to generalize—that is, make claims about a large population based on a smaller sample of people or items. Generalizing is important. We clearly do not have time to ask everyone their opinion on a topic or test a new intervention on every person. We need a type of causal explanation that helps us predict and estimate truth in all situations.
Generally, nomothetic causal relationships work best for explanatory research projects [INSERT SECTION LINK]. They also tend to use quantitative research: by boiling things down to numbers, one can use the universal language of mathematics to use statistics to explore those relationships. On the other hand, descriptive and exploratory projects often fit better with idiographic causality. These projects do not usually try to generalize, but instead investigate what is true for individuals, small groups, or communities at a specific point in time. You will learn about this type of causality in the next section. Here, we will assume you have an explanatory working question. For example, you may want to know about the risk and protective factors for a specific diagnosis or how a specific therapy impacts client outcomes.
What do nomothetic causal explanations look like?
Nomothetic causal explanations express relationships between variables. The term variable has a scientific definition. This one from Gillespie & Wagner (2018) "a logical grouping of attributes that can be observed and measured and is expected to vary from person to person in a population" (p. 9).[36] More practically, variables are the key concepts in your working question. You know, the things you plan to observe when you actually do your research project, conduct your surveys, complete your interviews, etc. These things have two key properties. First, they vary, as in they do not remain constant. "Age" varies by number. "Gender" varies by category. But they both vary. Second, they have attributes. So the variable "health professions" has attributes or categories, such as social worker, nurse, counselor, etc.
It's also worth reviewing what is not a variable. Well, things that don't change (or vary) aren't variables. If you planned to do a study on how gender impacts earnings but your study only contained women, that concept would not vary. Instead, it would be a constant. Another common mistake I see in students' explanatory questions is mistaking an attribute for a variable. "Men" is not a variable. "Gender" is a variable. "Virginia" is not a variable. The variable is the "state or territory" in which someone or something is physically located.
When one variable causes another, we have what researchers call independent and dependent variables. For example, in a study investigating the impact of spanking on aggressive behavior, spanking would be the independent variable and aggressive behavior would be the dependent variable. An independent variable is the cause, and a dependent variable is the effect. Why are they called that? Dependent variables depend on independent variables. If all of that gets confusing, just remember the graphical relationship in Figure 8.5.
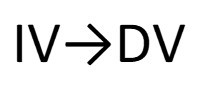
Exercises
Write out your working question, as it exists now. As we said previously in the subsection, we assume you have an explanatory research question for learning this section.
- Write out a diagram similar to Figure 8.5.
- Put your independent variable on the left and the dependent variable on the right.
Check:
- Can your variables vary?
- Do they have different attributes or categories that vary from person to person?
- How does the theory you identified in section 8.1 help you understand this causal relationship?
If the theory you've identified isn't much help to you or seems unrelated, it's a good indication that you need to read more literature about the theories related to your topic.
For some students, your working question may not be specific enough to list an independent or dependent variable clearly. You may have "risk factors" in place of an independent variable, for example. Or "effects" as a dependent variable. If that applies to your research question, get specific for a minute even if you have to revise this later. Think about which specific risk factors or effects you are interested in. Consider a few options for your independent and dependent variable and create diagrams similar to Figure 8.5.
Finally, you are likely to revisit your working question so you may have to come back to this exercise to clarify the causal relationship you want to investigate.
For a ten-cent word like "nomothetic," these causal relationships should look pretty basic to you. They should look like "x causes y." Indeed, you may be looking at your causal explanation and thinking, "wow, there are so many other things I'm missing in here." In fact, maybe my dependent variable sometimes causes changes in my independent variable! For example, a working question asking about poverty and education might ask how poverty makes it more difficult to graduate college or how high college debt impacts income inequality after graduation. Nomothetic causal relationships are slices of reality. They boil things down to two (or often more) key variables and assert a one-way causal explanation between them. This is by design, as they are trying to generalize across all people to all situations. The more complicated, circular, and often contradictory causal explanations are idiographic, which we will cover in the next section of this chapter.
Developing a hypothesis
A hypothesis is a statement describing a researcher’s expectation regarding what they anticipate finding. Hypotheses in quantitative research are a nomothetic causal relationship that the researcher expects to determine is true or false. A hypothesis is written to describe the expected relationship between the independent and dependent variables. In other words, write the answer to your working question using your variables. That's your hypothesis! Make sure you haven't introduced new variables into your hypothesis that are not in your research question. If you have, write out your hypothesis as in Figure 8.5.
A good hypothesis should be testable using social science research methods. That is, you can use a social science research project (like a survey or experiment) to test whether it is true or not. A good hypothesis is also specific about the relationship it explores. For example, a student project that hypothesizes, "families involved with child welfare agencies will benefit from Early Intervention programs," is not specific about what benefits it plans to investigate. For this student, I advised her to take a look at the empirical literature and theory about Early Intervention and see what outcomes are associated with these programs. This way, she could more clearly state the dependent variable in her hypothesis, perhaps looking at reunification, attachment, or developmental milestone achievement in children and families under child welfare supervision.
Your hypothesis should be an informed prediction based on a theory or model of the social world. For example, you may hypothesize that treating mental health clients with warmth and positive regard is likely to help them achieve their therapeutic goals. That hypothesis would be based on the humanistic practice models of Carl Rogers. Using previous theories to generate hypotheses is an example of deductive research. If Rogers’ theory of unconditional positive regard is accurate, a study comparing clinicians who used it versus those who did not would show more favorable treatment outcomes for clients receiving unconditional positive regard.
Let’s consider a couple of examples. In research on sexual harassment (Uggen & Blackstone, 2004),[37] one might hypothesize, based on feminist theories of sexual harassment, that more females than males will experience specific sexually harassing behaviors. What is the causal relationship being predicted here? Which is the independent and which is the dependent variable? In this case, researchers hypothesized that a person’s sex (independent variable) would predict their likelihood to experience sexual harassment (dependent variable).
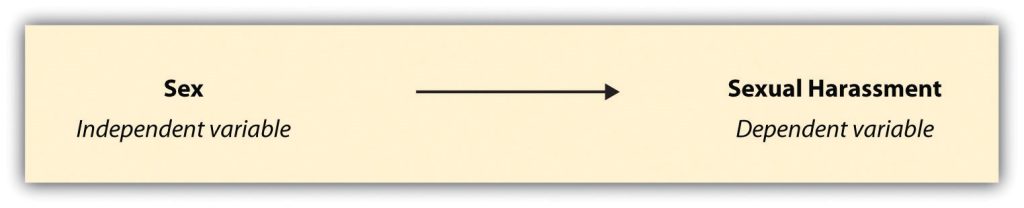
Sometimes researchers will hypothesize that a relationship will take a specific direction. As a result, an increase or decrease in one area might be said to cause an increase or decrease in another. For example, you might choose to study the relationship between age and support for legalization of marijuana. Perhaps you’ve taken a sociology class and, based on the theories you’ve read, you hypothesize that age is negatively related to support for marijuana legalization.[38] What have you just hypothesized?
You have hypothesized that as people get older, the likelihood of their supporting marijuana legalization decreases. Thus, as age (your independent variable) moves in one direction (up), support for marijuana legalization (your dependent variable) moves in another direction (down). So, a direct relationship (or positive correlation) involve two variables going in the same direction and an inverse relationship (or negative correlation) involve two variables going in opposite directions. If writing hypotheses feels tricky, it is sometimes helpful to draw them out and depict each of the two hypotheses we have just discussed.
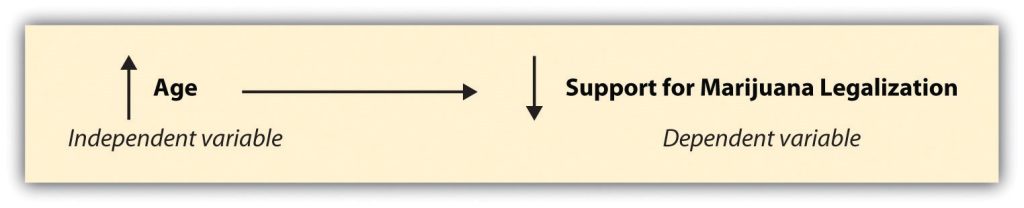
It’s important to note that once a study starts, it is unethical to change your hypothesis to match the data you find. For example, what happens if you conduct a study to test the hypothesis from Figure 8.7 on support for marijuana legalization, but you find no relationship between age and support for legalization? It means that your hypothesis was incorrect, but that’s still valuable information. It would challenge what the existing literature says on your topic, demonstrating that more research needs to be done to figure out the factors that impact support for marijuana legalization. Don’t be embarrassed by negative results, and definitely don’t change your hypothesis to make it appear correct all along!
Criteria for establishing a nomothetic causal relationship
Let’s say you conduct your study and you find evidence that supports your hypothesis, as age increases, support for marijuana legalization decreases. Success! Causal explanation complete, right? Not quite.
You’ve only established one of the criteria for causality. The criteria for causality must include all of the following: covariation, plausibility, temporality, and nonspuriousness. In our example from Figure 8.7, we have established only one criteria—covariation. When variables covary, they vary together. Both age and support for marijuana legalization vary in our study. Our sample contains people of varying ages and varying levels of support for marijuana legalization. If, for example, we only included 16-year-olds in our study, age would be a constant, not a variable.
Just because there might be some correlation between two variables does not mean that a causal relationship between the two is really plausible. Plausibility means that in order to make the claim that one event, behavior, or belief causes another, the claim has to make sense. It makes sense that people from previous generations would have different attitudes towards marijuana than younger generations. People who grew up in the time of Reefer Madness or the hippies may hold different views than those raised in an era of legalized medicinal and recreational use of marijuana. Plausibility is of course helped by basing your causal explanation in existing theoretical and empirical findings.
Once we’ve established that there is a plausible relationship between the two variables, we also need to establish whether the cause occurred before the effect, the criterion of temporality. A person’s age is a quality that appears long before any opinions on drug policy, so temporally the cause comes before the effect. It wouldn’t make any sense to say that support for marijuana legalization makes a person’s age increase. Even if you could predict someone’s age based on their support for marijuana legalization, you couldn’t say someone’s age was caused by their support for legalization of marijuana.
Finally, scientists must establish nonspuriousness. A spurious relationship is one in which an association between two variables appears to be causal but can in fact be explained by some third variable. This third variable is often called a confound or confounding variable because it clouds and confuses the relationship between your independent and dependent variable, making it difficult to discern the true causal relationship is.

Continuing with our example, we could point to the fact that older adults are less likely to have used marijuana recreationally. Maybe it is actually recreational use of marijuana that leads people to be more open to legalization, not their age. In this case, our confounding variable would be recreational marijuana use. Perhaps the relationship between age and attitudes towards legalization is a spurious relationship that is accounted for by previous use. This is also referred to as the third variable problem, where a seemingly true causal relationship is actually caused by a third variable not in the hypothesis. In this example, the relationship between age and support for legalization could be more about having tried marijuana than the age of the person.
Quantitative researchers are sensitive to the effects of potentially spurious relationships. As a result, they will often measure these third variables in their study, so they can control for their effects in their statistical analysis. These are called control variables, and they refer to potentially confounding variables whose effects are controlled for mathematically in the data analysis process. Control variables can be a bit confusing, and we will discuss them more in Chapter 10, but think about it as an argument between you, the researcher, and a critic.
Researcher: “The older a person is, the less likely they are to support marijuana legalization.”
Critic: “Actually, it’s more about whether a person has used marijuana before. That is what truly determines whether someone supports marijuana legalization.”
Researcher: “Well, I measured previous marijuana use in my study and mathematically controlled for its effects in my analysis. Age explains most of the variation in attitudes towards marijuana legalization.”
Let’s consider a few additional, real-world examples of spuriousness. Did you know, for example, that high rates of ice cream sales have been shown to cause drowning? Of course, that’s not really true, but there is a positive relationship between the two. In this case, the third variable that causes both high ice cream sales and increased deaths by drowning is time of year, as the summer season sees increases in both (Babbie, 2010).[39]
Here’s another good one: it is true that as the salaries of Presbyterian ministers in Massachusetts rise, so too does the price of rum in Havana, Cuba. Well, duh, you might be saying to yourself. Everyone knows how much ministers in Massachusetts love their rum, right? Not so fast. Both salaries and rum prices have increased, true, but so has the price of just about everything else (Huff & Geis, 1993).[40]
Finally, research shows that the more firefighters present at a fire, the more damage is done at the scene. What this statement leaves out, of course, is that as the size of a fire increases so too does the amount of damage caused as does the number of firefighters called on to help (Frankfort-Nachmias & Leon-Guerrero, 2011).[41] In each of these examples, it is the presence of a confounding variable that explains the apparent relationship between the two original variables.
In sum, the following criteria must be met for a nomothetic causal relationship:
- The two variables must vary together.
- The relationship must be plausible.
- The cause must precede the effect in time.
- The relationship must be nonspurious (not due to a confounding variable).
The hypothetico-dedutive method
The primary way that researchers in the positivist paradigm use theories is sometimes called the hypothetico-deductive method (although this term is much more likely to be used by philosophers of science than by scientists themselves). Researchers choose an existing theory. Then, they make a prediction about some new phenomenon that should be observed if the theory is correct. Again, this prediction is called a hypothesis. The researchers then conduct an empirical study to test the hypothesis. Finally, they reevaluate the theory in light of the new results and revise it if necessary.
This process is usually conceptualized as a cycle because the researchers can then derive a new hypothesis from the revised theory, conduct a new empirical study to test the hypothesis, and so on. As Figure 8.8 shows, this approach meshes nicely with the process of conducting a research project—creating a more detailed model of “theoretically motivated” or “theory-driven” research. Together, they form a model of theoretically motivated research.
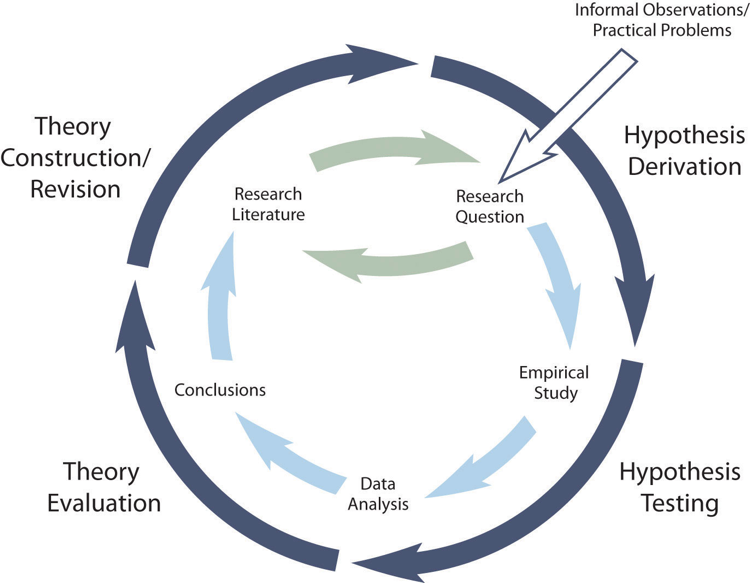
Keep in mind the hypothetico-deductive method is only one way of using social theory to inform social science research. It starts with describing one or more existing theories, deriving a hypothesis from one of those theories, testing your hypothesis in a new study, and finally reevaluating the theory based on the results data analyses. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with a hypothesis derived from a different theory.
But what if your research question is more interpretive? What if it is less about theory-testing and more about theory-building? This is what our next chapters will cover: the process of inductively deriving theory from people's stories and experiences. This process looks different than that depicted in Figure 8.8. It still starts with your research question and answering that question by conducting a research study. But instead of testing a hypothesis you created based on a theory, you will create a theory of your own that explain the data you collected. This format works well for qualitative research questions and for research questions that existing theories do not address.
Key Takeaways
- In positivist and quantitative studies, the goal is often to understand the more general causes of some phenomenon rather than the idiosyncrasies of one particular instance, as in an idiographic causal relationship.
- Nomothetic causal explanations focus on objectivity, prediction, and generalization.
- Criteria for nomothetic causal relationships require the relationship be plausible and nonspurious; and that the cause must precede the effect in time.
- In a nomothetic causal relationship, the independent variable causes changes in the dependent variable.
- Hypotheses are statements, drawn from theory, which describe a researcher’s expectation about a relationship between two or more variables.
Exercises
- Write out your working question and hypothesis.
- Defend your hypothesis in a short paragraph, using arguments based on the theory you identified in section 8.1.
- Review the criteria for a nomothetic causal relationship. Critique your short paragraph about your hypothesis using these criteria.
- Are there potentially confounding variables, issues with time order, or other problems you can identify in your reasoning?
Inductive & deductive (deductive focus)
Nomothetic causal explanations
Positivism
Chapter Outline
- Ethical and social justice considerations in measurement
- Post-positivism: Assumptions of quantitative methods
- Researcher positionality
- Assessing measurement quality and fighting oppression
Content warning: TBD.
12.1 Ethical and social justice considerations in measurement
Learning Objectives
Learners will be able to...
- Identify potential cultural, ethical, and social justice issues in measurement.
With your variables operationalized, it's time to take a step back and look at how measurement in social science impact our daily lives. As we will see, how we measure things is both shaped by power arrangements inside our society, and more insidiously, by establishing what is scientifically true, measures have their own power to influence the world. Just like reification in the conceptual world, how we operationally define concepts can reinforce or fight against oppressive forces.

Data equity
How we decide to measure our variables determines what kind of data we end up with in our research project. Because scientific processes are a part of our sociocultural context, the same biases and oppressions we see in the real world can be manifested or even magnified in research data. Jagadish and colleagues (2021)[42] presents four dimensions of data equity that are relevant to consider: in representation of non-dominant groups within data sets; in how data is collected, analyzed, and combined across datasets; in equitable and participatory access to data, and finally in the outcomes associated with the data collection. Historically, we have mostly focused on the outcomes of measures producing outcomes that are biased in one way or another, and this section reviews many such examples. However, it is important to note that equity must also come from designing measures that respond to questions like:
- Are groups historically suppressed from the data record represented in the sample?
- Are equity data gathered by researchers and used to uncover and quantify inequity?
- Are the data accessible across domains and levels of expertise, and can community members participate in the design, collection, and analysis of the public data record?
- Are the data collected used to monitor and mitigate inequitable impacts?
So, it's not just about whether measures work for one population for another. Data equity is about the context in which data are created from how we measure people and things. We agree with these authors that data equity should be considered within the context of automated decision-making systems and recognizing a broader literature around the role of administrative systems in creating and reinforcing discrimination. To combat the inequitable processes and outcomes we describe below, researchers must foreground equity as a core component of measurement.
Flawed measures & missing measures
At the end of every semester, students in just about every university classroom in the United States complete similar student evaluations of teaching (SETs). Since every student is likely familiar with these, we can recognize many of the concepts we discussed in the previous sections. There are number of rating scale questions that ask you to rate the professor, class, and teaching effectiveness on a scale of 1-5. Scores are averaged across students and used to determine the quality of teaching delivered by the faculty member. SETs scores are often a principle component of how faculty are reappointed to teaching positions. Would it surprise you to learn that student evaluations of teaching are of questionable quality? If your instructors are assessed with a biased or incomplete measure, how might that impact your education?
Most often, student scores are averaged across questions and reported as a final average. This average is used as one factor, often the most important factor, in a faculty member's reappointment to teaching roles. We learned in this chapter that rating scales are ordinal, not interval or ratio, and the data are categories not numbers. Although rating scales use a familiar 1-5 scale, the numbers 1, 2, 3, 4, & 5 are really just helpful labels for categories like "excellent" or "strongly agree." If we relabeled these categories as letters (A-E) rather than as numbers (1-5), how would you average them?
Averaging ordinal data is methodologically dubious, as the numbers are merely a useful convention. As you will learn in Chapter 14, taking the median value is what makes the most sense with ordinal data. Median values are also less sensitive to outliers. So, a single student who has strong negative or positive feelings towards the professor could bias the class's SETs scores higher or lower than what the "average" student in the class would say, particularly for classes with few students or in which fewer students completed evaluations of their teachers.
We care about teaching quality because more effective teachers will produce more knowledgeable and capable students. However, student evaluations of teaching are not particularly good indicators of teaching quality and are not associated with the independently measured learning gains of students (i.e., test scores, final grades) (Uttl et al., 2017).[43] This speaks to the lack of criterion validity. Higher teaching quality should be associated with better learning outcomes for students, but across multiple studies stretching back years, there is no association that cannot be better explained by other factors. To be fair, there are scholars who find that SETs are valid and reliable. For a thorough defense of SETs as well as a historical summary of the literature see Benton & Cashin (2012).[44]
Even though student evaluations of teaching often contain dozens of questions, researchers often find that the questions are so highly interrelated that one concept (or factor, as it is called in a factor analysis) explains a large portion of the variance in teachers' scores on student evaluations (Clayson, 2018).[45] Personally, I believe based on completing SETs myself that factor is probably best conceptualized as student satisfaction, which is obviously worthwhile to measure, but is conceptually quite different from teaching effectiveness or whether a course achieved its intended outcomes. The lack of a clear operational and conceptual definition for the variable or variables being measured in student evaluations of teaching also speaks to a lack of content validity. Researchers check content validity by comparing the measurement method with the conceptual definition, but without a clear conceptual definition of the concept measured by student evaluations of teaching, it's not clear how we can know our measure is valid. Indeed, the lack of clarity around what is being measured in teaching evaluations impairs students' ability to provide reliable and valid evaluations. So, while many researchers argue that the class average SETs scores are reliable in that they are consistent over time and across classes, it is unclear what exactly is being measured even if it is consistent (Clayson, 2018).[46]
As a faculty member, there are a number of things I can do to influence my evaluations and disrupt validity and reliability. Since SETs scores are associated with the grades students perceive they will receive (e.g., Boring et al., 2016),[47] guaranteeing everyone a final grade of A in my class will likely increase my SETs scores and my chances at tenure and promotion. I could time an email reminder to complete SETs with releasing high grades for a major assignment to boost my evaluation scores. On the other hand, student evaluations might be coincidentally timed with poor grades or difficult assignments that will bias student evaluations downward. Students may also infer I am manipulating them and give me lower SET scores as a result. To maximize my SET scores and chances and promotion, I also need to select which courses I teach carefully. Classes that are more quantitatively oriented generally receive lower ratings than more qualitative and humanities-driven classes, which makes my decision to teach social work research a poor strategy (Uttl & Smibert, 2017).[48] The only manipulative strategy I will admit to using is bringing food (usually cookies or donuts) to class during the period in which students are completing evaluations. Measurement is impacted by context.
As a white cis-gender male educator, I am adversely impacted by SETs because of their sketchy validity, reliability, and methodology. The other flaws with student evaluations actually help me while disadvantaging teachers from oppressed groups. Heffernan (2021)[49] provides a comprehensive overview of the sexism, racism, ableism, and prejudice baked into student evaluations:
"In all studies relating to gender, the analyses indicate that the highest scores are awarded in subjects filled with young, white, male students being taught by white English first language speaking, able-bodied, male academics who are neither too young nor too old (approx. 35–50 years of age), and who the students believe are heterosexual. Most deviations from this scenario in terms of student and academic demographics equates to lower SET scores. These studies thus highlight that white, able-bodied, heterosexual, men of a certain age are not only the least affected, they benefit from the practice. When every demographic group who does not fit this image is significantly disadvantaged by SETs, these processes serve to further enhance the position of the already privileged" (p. 5).
The staggering consistency of studies examining prejudice in SETs has led to some rather superficial reforms like reminding students to not submit racist or sexist responses in the written instructions given before SETs. Yet, even though we know that SETs are systematically biased against women, people of color, and people with disabilities, the overwhelming majority of universities in the United States continue to use them to evaluate faculty for promotion or reappointment. From a critical perspective, it is worth considering why university administrators continue to use such a biased and flawed instrument. SETs produce data that make it easy to compare faculty to one another and track faculty members over time. Furthermore, they offer students a direct opportunity to voice their concerns and highlight what went well.
As the people with the greatest knowledge about what happened in the classroom as whether it met their expectations, providing students with open-ended questions is the most productive part of SETs. Personally, I have found focus groups written, facilitated, and analyzed by student researchers to be more insightful than SETs. MSW student activists and leaders may look for ways to evaluate faculty that are more methodologically sound and less systematically biased, creating institutional change by replacing or augmenting traditional SETs in their department. There is very rarely student input on the criteria and methodology for teaching evaluations, yet students are the most impacted by helpful or harmful teaching practices.
Students should fight for better assessment in the classroom because well-designed assessments provide documentation to support more effective teaching practices and discourage unhelpful or discriminatory practices. Flawed assessments like SETs, can lead to a lack of information about problems with courses, instructors, or other aspects of the program. Think critically about what data your program uses to gauge its effectiveness. How might you introduce areas of student concern into how your program evaluates itself? Are there issues with food or housing insecurity, mentorship of nontraditional and first generation students, or other issues that faculty should consider when they evaluate their program? Finally, as you transition into practice, think about how your agency measures its impact and how it privileges or excludes client and community voices in the assessment process.
Let's consider an example from social work practice. Let's say you work for a mental health organization that serves youth impacted by community violence. How should you measure the impact of your services on your clients and their community? Schools may be interested in reducing truancy, self-injury, or other behavioral concerns. However, by centering delinquent behaviors in how we measure our impact, we may be inattentive to the role of trauma, family dynamics, and other cognitive and social processes beyond "delinquent behavior." Indeed, we may bias our interventions by focusing on things that are not as important to clients' needs. Social workers want to make sure their programs are improving over time, and we rely on our measures to indicate what to change and what to keep. If our measures present a partial or flawed view, we lose our ability to establish and act on scientific truths.
While writing this section, one of the authors wrote this commentary article addressing potential racial bias in social work licensing exams. If you are interested in an example of missing or flawed measures that relates to systems your social work practice is governed by (rather than SETs which govern our practice in higher education) check it out!
You may also be interested in similar arguments against the standard grading scale (A-F), and why grades (numerical, letter, etc.) do not do a good job of measuring learning. Think critically about the role that grades play in your life as a student, your self-concept, and your relationships with teachers. Your test and grade anxiety is due in part to how your learning is measured. Those measurements end up becoming an official record of your scholarship and allow employers or funders to compare you to other scholars. The stakes for measurement are the same for participants in your research study.

Self-reflection and measurement
Student evaluations of teaching are just like any other measure. How we decide to measure what we are researching is influenced by our backgrounds, including our culture, implicit biases, and individual experiences. For me as a middle-class, cisgender white woman, the decisions I make about measurement will probably default to ones that make the most sense to me and others like me, and thus measure characteristics about us most accurately if I don't think carefully about it. There are major implications for research here because this could affect the validity of my measurements for other populations.
This doesn't mean that standardized scales or indices, for instance, won't work for diverse groups of people. What it means is that researchers must not ignore difference in deciding how to measure a variable in their research. Doing so may serve to push already marginalized people further into the margins of academic research and, consequently, social work intervention. Social work researchers, with our strong orientation toward celebrating difference and working for social justice, are obligated to keep this in mind for ourselves and encourage others to think about it in their research, too.
This involves reflecting on what we are measuring, how we are measuring, and why we are measuring. Do we have biases that impacted how we operationalized our concepts? Did we include stakeholders and gatekeepers in the development of our concepts? This can be a way to gain access to vulnerable populations. What feedback did we receive on our measurement process and how was it incorporated into our work? These are all questions we should ask as we are thinking about measurement. Further, engaging in this intentionally reflective process will help us maximize the chances that our measurement will be accurate and as free from bias as possible.
The NASW Code of Ethics discusses social work research and the importance of engaging in practices that do not harm participants. This is especially important considering that many of the topics studied by social workers are those that are disproportionately experienced by marginalized and oppressed populations. Some of these populations have had negative experiences with the research process: historically, their stories have been viewed through lenses that reinforced the dominant culture's standpoint. Thus, when thinking about measurement in research projects, we must remember that the way in which concepts or constructs are measured will impact how marginalized or oppressed persons are viewed. It is important that social work researchers examine current tools to ensure appropriateness for their population(s). Sometimes this may require researchers to use existing tools. Other times, this may require researchers to adapt existing measures or develop completely new measures in collaboration with community stakeholders. In summary, the measurement protocols selected should be tailored and attentive to the experiences of the communities to be studied.
Unfortunately, social science researchers do not do a great job of sharing their measures in a way that allows social work practitioners and administrators to use them to evaluate the impact of interventions and programs on clients. Few scales are published under an open copyright license that allows other people to view it for free and share it with others. Instead, the best way to find a scale mentioned in an article is often to simply search for it in Google with ".pdf" or ".docx" in the query to see if someone posted a copy online (usually in violation of copyright law). As we discussed in Chapter 4, this is an issue of information privilege, or the structuring impact of oppression and discrimination on groups' access to and use of scholarly information. As a student at a university with a research library, you can access the Mental Measurement Yearbook to look up scales and indexes that measure client or program outcomes while researchers unaffiliated with university libraries cannot do so. Similarly, the vast majority of scholarship in social work and allied disciplines does not share measures, data, or other research materials openly, a best practice in open and collaborative science. In many cases, the public paid for these research materials as part of grants; yet the projects close off access to much of the study information. It is important to underscore these structural barriers to using valid and reliable scales in social work practice. An invalid or unreliable outcome test may cause ineffective or harmful programs to persist or may worsen existing prejudices and oppressions experienced by clients, communities, and practitioners.
But it's not just about reflecting and identifying problems and biases in our measurement, operationalization, and conceptualization—what are we going to do about it? Consider this as you move through this book and become a more critical consumer of research. Sometimes there isn't something you can do in the immediate sense—the literature base at this moment just is what it is. But how does that inform what you will do later?
A place to start: Stop oversimplifying race
We will address many more of the critical issues related to measurement in the next chapter. One way to get started in bringing cultural awareness to scientific measurement is through a critical examination of how we analyze race quantitatively. There are many important methodological objections to how we measure the impact of race. We encourage you to watch Dr. Abigail Sewell's three-part workshop series called "Nested Models for Critical Studies of Race & Racism" for the Inter-university Consortium for Political and Social Research (ICPSR). She discusses how to operationalize and measure inequality, racism, and intersectionality and critiques researchers' attempts to oversimplify or overlook racism when we measure concepts in social science. If you are interested in developing your social work research skills further, consider applying for financial support from your university to attend an ICPSR summer seminar like Dr. Sewell's where you can receive more advanced and specialized training in using research for social change.
- Part 1: Creating Measures of Supraindividual Racism (2-hour video)
- Part 2: Evaluating Population Risks of Supraindividual Racism (2-hour video)
- Part 3: Quantifying Intersectionality (2-hour video)
Key Takeaways
- Social work researchers must be attentive to personal and institutional biases in the measurement process that affect marginalized groups.
- What is measured and how it is measured is shaped by power, and social workers must be critical and self-reflective in their research projects.
Exercises
Think about your current research question and the tool(s) that you see researchers use to gather data.
- How does their positionality and experience shape what variables they are choosing to measure and how they measure concepts?
- Evaluate the measures in your study for potential biases.
- If you are using measures developed by another researcher to inform your ideas, investigate whether the measure is valid and reliable in other studies across cultures.
10.2 Post-positivism: The assumptions of quantitative methods
Learning Objectives
Learners will be able to...
- Ground your research project and working question in the philosophical assumptions of social science
- Define the terms 'ontology' and 'epistemology' and explain how they relate to quantitative and qualitative research methods
- Apply feminist, anti-racist, and decolonization critiques of social science to your project
- Define axiology and describe the axiological assumptions of research projects
What are your assumptions?
Social workers must understand measurement theory to engage in social justice work. That's because measurement theory and its supporting philosophical assumptions will help sharpen your perceptions of the social world. They help social workers build heuristics that can help identify the fundamental assumptions at the heart of social conflict and social problems. They alert you to the patterns in the underlying assumptions that different people make and how those assumptions shape their worldview, what they view as true, and what they hope to accomplish. In the next section, we will review feminist and other critical perspectives on research, and they should help inform you of how assumptions about research can reinforce oppression.
Understanding these deeper structures behind research evidence is a true gift of social work research. Because we acknowledge the usefulness and truth value of multiple philosophies and worldviews contained in this chapter, we can arrive at a deeper and more nuanced understanding of the social world.
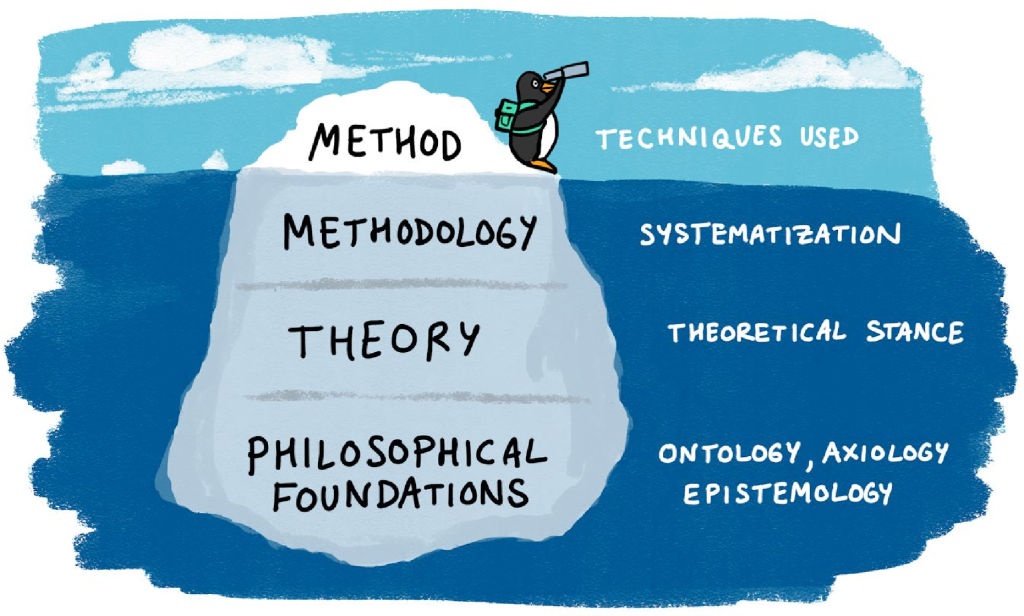
Building your ice float
Before we can dive into philosophy, we need to recall out conversation from Chapter 1 about objective truth and subjective truths. Let's test your knowledge with a quick example. Is crime on the rise in the United States? A recent Five Thirty Eight article highlights the disparity between historical trends on crime that are at or near their lowest in the thirty years with broad perceptions by the public that crime is on the rise (Koerth & Thomson-DeVeaux, 2020).[50] Social workers skilled at research can marshal objective truth through statistics, much like the authors do, to demonstrate that people's perceptions are not based on a rational interpretation of the world. Of course, that is not where our work ends. Subjective truths might decenter this narrative of ever-increasing crime, deconstruct its racist and oppressive origins, or simply document how that narrative shapes how individuals and communities conceptualize their world.
Objective does not mean right, and subjective does not mean wrong. Researchers must understand what kind of truth they are searching for so they can choose a theoretical framework, methodology, and research question that matches. As we discussed in Chapter 1, researchers seeking objective truth (one of the philosophical foundations at the bottom of Figure 7.1) often employ quantitative methods (one of the methods at the top of Figure 7.1). Similarly, researchers seeking subjective truths (again, at the bottom of Figure 7.1) often employ qualitative methods (at the top of Figure 7.1). This chapter is about the connective tissue, and by the time you are done reading, you should have a first draft of a theoretical and philosophical (a.k.a. paradigmatic) framework for your study.
Ontology: Assumptions about what is real & true
In section 1.2, we reviewed the two types of truth that social work researchers seek—objective truth and subjective truths —and linked these with the methods—quantitative and qualitative—that researchers use to study the world. If those ideas aren’t fresh in your mind, you may want to navigate back to that section for an introduction.
These two types of truth rely on different assumptions about what is real in the social world—i.e., they have a different ontology. Ontology refers to the study of being (literally, it means “rational discourse about being”). In philosophy, basic questions about existence are typically posed as ontological, e.g.:
- What is there?
- What types of things are there?
- How can we describe existence?
- What kind of categories can things go into?
- Are the categories of existence hierarchical?
Objective vs. subjective ontologies
At first, it may seem silly to question whether the phenomena we encounter in the social world are real. Of course you exist, your thoughts exist, your computer exists, and your friends exist. You can see them with your eyes. This is the ontological framework of realism, which simply means that the concepts we talk about in science exist independent of observation (Burrell & Morgan, 1979).[51] Obviously, when we close our eyes, the universe does not disappear. You may be familiar with the philosophical conundrum: "If a tree falls in a forest and no one is around to hear it, does it make a sound?"
The natural sciences, like physics and biology, also generally rely on the assumption of realism. Lone trees falling make a sound. We assume that gravity and the rest of physics are there, even when no one is there to observe them. Mitochondria are easy to spot with a powerful microscope, and we can observe and theorize about their function in a cell. The gravitational force is invisible, but clearly apparent from observable facts, such as watching an apple fall from a tree. Of course, out theories about gravity have changed over the years. Improvements were made when observations could not be correctly explained using existing theories and new theories emerged that provided a better explanation of the data.
As we discussed in section 1.2, culture-bound syndromes are an excellent example of where you might come to question realism. Of course, from a Western perspective as researchers in the United States, we think that the Diagnostic and Statistical Manual (DSM) classification of mental health disorders is real and that these culture-bound syndromes are aberrations from the norm. But what about if you were a person from Korea experiencing Hwabyeong? Wouldn't you consider the Western diagnosis of somatization disorder to be incorrect or incomplete? This conflict raises the question–do either Hwabyeong or DSM diagnoses like post-traumatic stress disorder (PTSD) really exist at all...or are they just social constructs that only exist in our minds?
If your answer is “no, they do not exist,” you are adopting the ontology of anti-realism (or relativism), or the idea that social concepts do not exist outside of human thought. Unlike the realists who seek a single, universal truth, the anti-realists perceive a sea of truths, created and shared within a social and cultural context. Unlike objective truth, which is true for all, subjective truths will vary based on who you are observing and the context in which you are observing them. The beliefs, opinions, and preferences of people are actually truths that social scientists measure and describe. Additionally, subjective truths do not exist independent of human observation because they are the product of the human mind. We negotiate what is true in the social world through language, arriving at a consensus and engaging in debate within our socio-cultural context.
These theoretical assumptions should sound familiar if you've studied social constructivism or symbolic interactionism in your other MSW courses, most likely in human behavior in the social environment (HBSE).[52] From an anti-realist perspective, what distinguishes the social sciences from natural sciences is human thought. When we try to conceptualize trauma from an anti-realist perspective, we must pay attention to the feelings, opinions, and stories in people's minds. In their most radical formulations, anti-realists propose that these feelings and stories are all that truly exist.
What happens when a situation is incorrectly interpreted? Certainly, who is correct about what is a bit subjective. It depends on who you ask. Even if you can determine whether a person is actually incorrect, they think they are right. Thus, what may not be objectively true for everyone is nevertheless true to the individual interpreting the situation. Furthermore, they act on the assumption that they are right. We all do. Much of our behaviors and interactions are a manifestation of our personal subjective truth. In this sense, even incorrect interpretations are truths, even though they are true only to one person or a group of misinformed people. This leads us to question whether the social concepts we think about really exist. For researchers using subjective ontologies, they might only exist in our minds; whereas, researchers who use objective ontologies which assume these concepts exist independent of thought.
How do we resolve this dichotomy? As social workers, we know that often times what appears to be an either/or situation is actually a both/and situation. Let's take the example of trauma. There is clearly an objective thing called trauma. We can draw out objective facts about trauma and how it interacts with other concepts in the social world such as family relationships and mental health. However, that understanding is always bound within a specific cultural and historical context. Moreover, each person's individual experience and conceptualization of trauma is also true. Much like a client who tells you their truth through their stories and reflections, when a participant in a research study tells you what their trauma means to them, it is real even though only they experience and know it that way. By using both objective and subjective analytic lenses, we can explore different aspects of trauma—what it means to everyone, always, everywhere, and what is means to one person or group of people, in a specific place and time.

Epistemology: Assumptions about how we know things
Having discussed what is true, we can proceed to the next natural question—how can we come to know what is real and true? This is epistemology. Epistemology is derived from the Ancient Greek epistēmē which refers to systematic or reliable knowledge (as opposed to doxa, or “belief”). Basically, it means “rational discourse about knowledge,” and the focus is the study of knowledge and methods used to generate knowledge. Epistemology has a history as long as philosophy, and lies at the foundation of both scientific and philosophical knowledge.
Epistemological questions include:
- What is knowledge?
- How can we claim to know anything at all?
- What does it mean to know something?
- What makes a belief justified?
- What is the relationship between the knower and what can be known?
While these philosophical questions can seem far removed from real-world interaction, thinking about these kinds of questions in the context of research helps you target your inquiry by informing your methods and helping you revise your working question. Epistemology is closely connected to method as they are both concerned with how to create and validate knowledge. Research methods are essentially epistemologies – by following a certain process we support our claim to know about the things we have been researching. Inappropriate or poorly followed methods can undermine claims to have produced new knowledge or discovered a new truth. This can have implications for future studies that build on the data and/or conceptual framework used.
Research methods can be thought of as essentially stripped down, purpose-specific epistemologies. The knowledge claims that underlie the results of surveys, focus groups, and other common research designs ultimately rest on epistemological assumptions of their methods. Focus groups and other qualitative methods usually rely on subjective epistemological (and ontological) assumptions. Surveys and and other quantitative methods usually rely on objective epistemological assumptions. These epistemological assumptions often entail congruent subjective or objective ontological assumptions about the ultimate questions about reality.
Objective vs. subjective epistemologies
One key consideration here is the status of ‘truth’ within a particular epistemology or research method. If, for instance, some approaches emphasize subjective knowledge and deny the possibility of an objective truth, what does this mean for choosing a research method?
We began to answer this question in Chapter 1 when we described the scientific method and objective and subjective truths. Epistemological subjectivism focuses on what people think and feel about a situation, while epistemological objectivism focuses on objective facts irrelevant to our interpretation of a situation (Lin, 2015).[53]
While there are many important questions about epistemology to ask (e.g., "How can I be sure of what I know?" or "What can I not know?" see Willis, 2007[54] for more), from a pragmatic perspective most relevant epistemological question in the social sciences is whether truth is better accessed using numerical data or words and performances. Generally, scientists approaching research with an objective epistemology (and realist ontology) will use quantitative methods to arrive at scientific truth. Quantitative methods examine numerical data to precisely describe and predict elements of the social world. For example, while people can have different definitions for poverty, an objective measurement such as an annual income of "less than $25,100 for a family of four" provides a precise measurement that can be compared to incomes from all other people in any society from any time period, and refers to real quantities of money that exist in the world. Mathematical relationships are uniquely useful in that they allow comparisons across individuals as well as time and space. In this book, we will review the most common designs used in quantitative research: surveys and experiments. These types of studies usually rely on the epistemological assumption that mathematics can represent the phenomena and relationships we observe in the social world.
Although mathematical relationships are useful, they are limited in what they can tell you. While you can learn use quantitative methods to measure individuals' experiences and thought processes, you will miss the story behind the numbers. To analyze stories scientifically, we need to examine their expression in interviews, journal entries, performances, and other cultural artifacts using qualitative methods. Because social science studies human interaction and the reality we all create and share in our heads, subjectivists focus on language and other ways we communicate our inner experience. Qualitative methods allow us to scientifically investigate language and other forms of expression—to pursue research questions that explore the words people write and speak. This is consistent with epistemological subjectivism's focus on individual and shared experiences, interpretations, and stories.
It is important to note that qualitative methods are entirely compatible with seeking objective truth. Approaching qualitative analysis with a more objective perspective, we look simply at what was said and examine its surface-level meaning. If a person says they brought their kids to school that day, then that is what is true. A researcher seeking subjective truth may focus on how the person says the words—their tone of voice, facial expressions, metaphors, and so forth. By focusing on these things, the researcher can understand what it meant to the person to say they dropped their kids off at school. Perhaps in describing dropping their children off at school, the person thought of their parents doing the same thing or tried to understand why their kid didn't wave back to them as they left the car. In this way, subjective truths are deeper, more personalized, and difficult to generalize.

Self-determination and free will
When scientists observe social phenomena, they often take the perspective of determinism, meaning that what is seen is the result of processes that occurred earlier in time (i.e., cause and effect). This process is represented in the classical formulation of a research question which asks "what is the relationship between X (cause) and Y (effect)?" By framing a research question in such a way, the scientist is disregarding any reciprocal influence that Y has on X. Moreover, the scientist also excludes human agency from the equation. It is simply that a cause will necessitate an effect. For example, a researcher might find that few people living in neighborhoods with higher rates of poverty graduate from high school, and thus conclude that poverty causes adolescents to drop out of school. This conclusion, however, does not address the story behind the numbers. Each person who is counted as graduating or dropping out has a unique story of why they made the choices they did. Perhaps they had a mentor or parent that helped them succeed. Perhaps they faced the choice between employment to support family members or continuing in school.
For this reason, determinism is critiqued as reductionistic in the social sciences because people have agency over their actions. This is unlike the natural sciences like physics. While a table isn't aware of the friction it has with the floor, parents and children are likely aware of the friction in their relationships and act based on how they interpret that conflict. The opposite of determinism is free will, that humans can choose how they act and their behavior and thoughts are not solely determined by what happened prior in a neat, cause-and-effect relationship. Researchers adopting a perspective of free will view the process of, continuing with our education example, seeking higher education as the result of a number of mutually influencing forces and the spontaneous and implicit processes of human thought. For these researchers, the picture painted by determinism is too simplistic.
A similar dichotomy can be found in the debate between individualism and holism. When you hear something like "the disease model of addiction leads to policies that pathologize and oppress people who use drugs," the speaker is making a methodologically holistic argument. They are making a claim that abstract social forces (the disease model, policies) can cause things to change. A methodological individualist would critique this argument by saying that the disease model of addiction doesn't actually cause anything by itself. From this perspective, it is the individuals, rather than any abstract social force, who oppress people who use drugs. The disease model itself doesn't cause anything to change; the individuals who follow the precepts of the disease model are the agents who actually oppress people in reality. To an individualist, all social phenomena are the result of individual human action and agency. To a holist, social forces can determine outcomes for individuals without individuals playing a causal role, undercutting free will and research projects that seek to maximize human agency.
Exercises
- Examine an article from your literature review
- Is human action, or free will, informing how the authors think about the people in their study?
- Or are humans more passive and what happens to them more determined by the social forces that influence their life?
- Reflect on how this project's assumptions may differ from your own assumptions about free will and determinism. For example, my beliefs about self-determination and free will always inform my social work practice. However, my working question and research project may rely on social theories that are deterministic and do not address human agency.
Radical change
Another assumption scientists make is around the nature of the social world. Is it an orderly place that remains relatively stable over time? Or is it a place of constant change and conflict? The view of the social world as an orderly place can help a researcher describe how things fit together to create a cohesive whole. For example, systems theory can help you understand how different systems interact with and influence one another, drawing energy from one place to another through an interconnected network with a tendency towards homeostasis. This is a more consensus-focused and status-quo-oriented perspective. Yet, this view of the social world cannot adequately explain the radical shifts and revolutions that occur. It also leaves little room for human action and free will. In this more radical space, change consists of the fundamental assumptions about how the social world works.
For example, at the time of this writing, protests are taking place across the world to remember the killing of George Floyd by Minneapolis police and other victims of police violence and systematic racism. Public support of Black Lives Matter, an anti-racist activist group that focuses on police violence and criminal justice reform, has experienced a radical shift in public support in just two weeks since the killing, equivalent to the previous 21 months of advocacy and social movement organizing (Cohn & Quealy, 2020).[55] Abolition of police and prisons, once a fringe idea, has moved into the conversation about remaking the criminal justice system from the ground-up, centering its historic and current role as an oppressive system for Black Americans. Seemingly overnight, reducing the money spent on police and giving that money to social services became a moderate political position.
A researcher centering change may choose to understand this transformation or even incorporate radical anti-racist ideas into the design and methods of their study. For an example of how to do so, see this participatory action research study working with Black and Latino youth (Bautista et al., 2013).[56] Contrastingly, a researcher centering consensus and the status quo might focus on incremental changes what people currently think about the topic. For example, see this survey of social work student attitudes on poverty and race that seeks to understand the status quo of student attitudes and suggest small changes that might change things for the better (Constance-Huggins et al., 2020).[57] To be clear, both studies contribute to racial justice. However, you can see by examining the methods section of each article how the participatory action research article addresses power and values as a core part of their research design, qualitative ethnography and deep observation over many years, in ways that privilege the voice of people with the least power. In this way, it seeks to rectify the epistemic injustice of excluding and oversimplifying Black and Latino youth. Contrast this more radical approach with the more traditional approach taken in the second article, in which they measured student attitudes using a survey developed by researchers.
Exercises
- Examine an article from your literature review
- Traditional studies will be less participatory. The researcher will determine the research question, how to measure it, data collection, etc.
- Radical studies will be more participatory. The researcher seek to undermine power imbalances at each stage of the research process.
- Pragmatically, more participatory studies take longer to complete and are less suited to projects that need to be completed in a short time frame.

Axiology: Assumptions about values
Axiology is the study of values and value judgements (literally “rational discourse about values [a xía]”). In philosophy this field is subdivided into ethics (the study of morality) and aesthetics (the study of beauty, taste and judgement). For the hard-nosed scientist, the relevance of axiology might not be obvious. After all, what difference do one’s feelings make for the data collected? Don’t we spend a long time trying to teach researchers to be objective and remove their values from the scientific method?
Like ontology and epistemology, the import of axiology is typically built into research projects and exists “below the surface”. You might not consciously engage with values in a research project, but they are still there. Similarly, you might not hear many researchers refer to their axiological commitments but they might well talk about their values and ethics, their positionality, or a commitment to social justice.
Our values focus and motivate our research. These values could include a commitment to scientific rigor, or to always act ethically as a researcher. At a more general level we might ask: What matters? Why do research at all? How does it contribute to human wellbeing? Almost all research projects are grounded in trying to answer a question that matters or has consequences. Some research projects are even explicit in their intention to improve things rather than observe them. This is most closely associated with “critical” approaches.
Critical and radical views of science focus on how to spread knowledge and information in a way that combats oppression. These questions are central for creating research projects that fight against the objective structures of oppression—like unequal pay—and their subjective counterparts in the mind—like internalized sexism. For example, a more critical research project would fight not only against statutes of limitations for sexual assault but on how women have internalized rape culture as well. Its explicit goal would be to fight oppression and to inform practice on women's liberation. For this reason, creating change is baked into the research questions and methods used in more critical and radical research projects.
As part of studying radical change and oppression, we are likely employing a model of science that puts values front-and-center within a research project. All social work research is values-driven, as we are a values-driven profession. Historically, though, most social scientists have argued for values-free science. Scientists agree that science helps human progress, but they hold that researchers should remain as objective as possible—which means putting aside politics and personal values that might bias their results, similar to the cognitive biases we discussed in section 1.1. Over the course of last century, this perspective was challenged by scientists who approached research from an explicitly political and values-driven perspective. As we discussed earlier in this section, feminist critiques strive to understand how sexism biases research questions, samples, measures, and conclusions, while decolonization critiques try to de-center the Western perspective of science and truth.
Linking axiology, epistemology, and ontology
It is important to note that both values-central and values-neutral perspectives are useful in furthering social justice. Values-neutral science is helpful at predicting phenomena. Indeed, it matches well with objectivist ontologies and epistemologies. Let's examine a measure of depression, the Patient Health Questionnaire (PSQ-9). The authors of this measure spent years creating a measure that accurately and reliably measures the concept of depression. This measure is assumed to measure depression in any person, and scales like this are often translated into other languages (and subsequently validated) for more widespread use . The goal is to measure depression in a valid and reliable manner. We can use this objective measure to predict relationships with other risk and protective factors, such as substance use or poverty, as well as evaluate the impact of evidence-based treatments for depression like narrative therapy.
While measures like the PSQ-9 help with prediction, they do not allow you to understand an individual person's experience of depression. To do so, you need to listen to their stories and how they make sense of the world. The goal of understanding isn't to predict what will happen next, but to empathically connect with the person and truly understand what's happening from their perspective. Understanding fits best in subjectivist epistemologies and ontologies, as they allow for multiple truths (i.e. that multiple interpretations of the same situation are valid). Although all researchers addressing depression are working towards socially just ends, the values commitments researchers make as part of the research process influence them to adopt objective or subjective ontologies and epistemologies.
Exercises
What role will values play in your study?
- Are you looking to be as objective as possible, putting aside your own values?
- Or are you infusing values into each aspect of your research design?
Remember that although social work is a values-based profession, that does not mean that all social work research is values-informed. The majority of social work research is objective and tries to be value-neutral in how it approaches research.
Positivism: Researcher as "expert"
Positivism (and post-positivism) is the dominant paradigm in social science. We define paradigm a set of common philosophical (ontological, epistemological, and axiological) assumptions that inform research. The four paradigms we describe in this section refer to patterns in how groups of researchers resolve philosophical questions. Some assumptions naturally make sense together, and paradigms grow out of researchers with shared assumptions about what is important and how to study it. Paradigms are like “analytic lenses” and a provide framework on top of which we can build theoretical and empirical knowledge (Kuhn, 1962).[58] Consider this video of an interview with world-famous physicist Richard Feynman in which he explains why "when you explain a 'why,' you have to be in some framework that you allow something to be true. Otherwise, you are perpetually asking why." In order to answer basic physics question like "what is happening when two magnets attract?" or a social work research question like "what is the impact of this therapeutic intervention on depression," you must understand the assumptions you are making about social science and the social world. Paradigmatic assumptions about objective and subjective truth support methodological choices like whether to conduct interviews or send out surveys, for example.
When you think of science, you are probably thinking of positivistic science--like the kind the physicist Richard Feynman did. It has its roots in the scientific revolution of the Enlightenment. Positivism is based on the idea that we can come to know facts about the natural world through our experiences of it. The processes that support this are the logical and analytic classification and systemization of these experiences. Through this process of empirical analysis, Positivists aim to arrive at descriptions of law-like relationships and mechanisms that govern the world we experience.
Positivists have traditionally claimed that the only authentic knowledge we have of the world is empirical and scientific. Essentially, positivism downplays any gap between our experiences of the world and the way the world really is; instead, positivism determines objective “facts” through the correct methodological combination of observation and analysis. Data collection methods typically include quantitative measurement, which is supposed to overcome the individual biases of the researcher.
Positivism aspires to high standards of validity and reliability supported by evidence, and has been applied extensively in both physical and social sciences. Its goal is familiar to all students of science: iteratively expanding the evidence base of what we know is true. We can know our observations and analysis describe real world phenomena because researchers separate themselves and objectively observe the world, placing a deep epistemological separation between “the knower” and “what is known" and reducing the possibility of bias. We can all see the logic in separating yourself as much as possible from your study so as not to bias it, even if we know we cannot do so perfectly.
However, the criticism often made of positivism with regard to human and social sciences (e.g. education, psychology, sociology) is that positivism is scientistic; which is to say that it overlooks differences between the objects in the natural world (tables, atoms, cells, etc.) and the subjects in the social work (self-aware people living in a complex socio-historical context). In pursuit of the generalizable truth of “hard” science, it fails to adequately explain the many aspects of human experience don’t conform to this way of collecting data. Furthermore, by viewing science as an idealized pursuit of pure knowledge, positivists may ignore the many ways in which power structures our access to scientific knowledge, the tools to create it, and the capital to participate in the scientific community.
Kivunja & Kuyini (2017)[59] describe the essential features of positivism as:
- A belief that theory is universal and law-like generalizations can be made across contexts
- The assumption that context is not important
- The belief that truth or knowledge is ‘out there to be discovered’ by research
- The belief that cause and effect are distinguishable and analytically separable
- The belief that results of inquiry can be quantified
- The belief that theory can be used to predict and to control outcomes
- The belief that research should follow the scientific method of investigation
- Rests on formulation and testing of hypotheses
- Employs empirical or analytical approaches
- Pursues an objective search for facts
- Believes in ability to observe knowledge
- The researcher’s ultimate aim is to establish a comprehensive universal theory, to account for human and social behavior
- Application of the scientific method
Many quantitative researchers now identify as postpositivist. Postpositivism retains the idea that truth should be considered objective, but asserts that our experiences of such truths are necessarily imperfect because they are ameliorated by our values and experiences. Understanding how postpositivism has updated itself in light of the developments in other research paradigms is instructive for developing your own paradigmatic framework. Epistemologically, postpositivists operate on the assumption that human knowledge is based not on the assessments from an objective individual, but rather upon human conjectures. As human knowledge is thus unavoidably conjectural and uncertain, though assertions about what is true and why it is true can be modified or withdrawn in the light of further investigation. However, postpositivism is not a form of relativism, and generally retains the idea of objective truth.
These epistemological assumptions are based on ontological assumptions that an objective reality exists, but contra positivists, they believe reality can be known only imperfectly and probabilistically. While positivists believe that research is or can be value-free or value-neutral, postpositivists take the position that bias is undesired but inevitable, and therefore the investigator must work to detect and try to correct it. Postpositivists work to understand how their axiology (i.e., values and beliefs) may have influenced their research, including through their choice of measures, populations, questions, and definitions, as well as through their interpretation and analysis of their work. Methodologically, they use mixed methods and both quantitative and qualitative methods, accepting the problematic nature of “objective” truths and seeking to find ways to come to a better, yet ultimately imperfect understanding of what is true. A popular form of postpositivism is critical realism, which lies between positivism and interpretivism.
Is positivism right for your project?
Positivism is concerned with understanding what is true for everybody. Social workers whose working question fits best with the positivist paradigm will want to produce data that are generalizable and can speak to larger populations. For this reason, positivistic researchers favor quantitative methods—probability sampling, experimental or survey design, and multiple, and standardized instruments to measure key concepts.
A positivist orientation to research is appropriate when your research question asks for generalizable truths. For example, your working question may look something like: does my agency's housing intervention lead to fewer periods of homelessness for our clients? It is necessary to study such a relationship quantitatively and objectively. When social workers speak about social problems impacting societies and individuals, they reference positivist research, including experiments and surveys of the general populations. Positivist research is exceptionally good at producing cause-and-effect explanations that apply across many different situations and groups of people. There are many good reasons why positivism is the dominant research paradigm in the social sciences.
Critiques of positivism stem from two major issues. First and foremost, positivism may not fit the messy, contradictory, and circular world of human relationships. A positivistic approach does not allow the researcher to understand another person's subjective mental state in detail. This is because the positivist orientation focuses on quantifiable, generalizable data—and therefore encompasses only a small fraction of what may be true in any given situation. This critique is emblematic of the interpretivist paradigm, which we will describe when we conceptualize qualitative research methods.
Also in qualitative methods, we will describe the critical paradigm, which critiques the positivist paradigm (and the interpretivist paradigm) for focusing too little on social change, values, and oppression. Positivists assume they know what is true, but they often do not incorporate the knowledge and experiences of oppressed people, even when those community members are directly impacted by the research. Positivism has been critiqued as ethnocentrist, patriarchal, and classist (Kincheloe & Tobin, 2009).[60] This leads them to do research on, rather than with populations by excluding them from the conceptualization, design, and impact of a project, a topic we discussed in section 2.4. It also leads them to ignore the historical and cultural context that is important to understanding the social world. The result can be a one-dimensional and reductionist view of reality.
Exercises
- From your literature search, identify an empirical article that uses quantitative methods to answer a research question similar to your working question or about your research topic.
- Review the assumptions of the positivist research paradigm.
- Discuss in a few sentences how the author's conclusions are based on some of these paradigmatic assumptions. How might a researcher operating from a different paradigm (e.g., interpretivism, critical) critique these assumptions as well as the conclusions of this study?
10.3 Researcher positionality
Learning Objectives
Learners will be able to...
- Define positionality and explain its impact on the research process
- Identify your positionality using reflexivity
- Reflect on the strengths and limitations of researching as an outsider or insider to the population under study
Most research studies will use the assumptions of positivism or postpositivism to inform their measurement decisions. It is important for researchers to take a step back from the research process and examine their relationship with the topic. Because positivistic research methods require the researcher to be objective, research in this paradigm requires a similar reflexive self-awareness that clinical practice does to ensure that unconscious biases and positionality are not manifested through one's work. The assumptions of positivistic inquiry work best when the researcher's subjectivity is as far removed from the observation and analysis as possible.
Positionality
Student researchers in the social sciences are usually required to identify and articulate their positionality. Frequently teachers and supervisors will expect work to include information about the student’s positionality and its influence on their research. Yet for those commencing a research journey, this may often be difficult and challenging, as students are unlikely to have been required to do so in previous studies. Novice researchers often have difficulty both in identifying exactly what positionality is and in outlining their own. This paper explores researcher positionality and its influence on the research process, so that new researchers may better understand why it is important. Researcher positionality is explained, reflexivity is discussed, and the ‘insider-outsider’ debate is critiqued.
The term positionality both describes an individual’s world view and the position they adopt about a research task and its social and political context (Foote & Bartell 2011, Savin-Baden & Major, 2013 and Rowe, 2014). The individual’s world view or ‘where the researcher is coming from’ concerns ontological assumptions (an individual’s beliefs about the nature of social reality and what is knowable about the world), epistemological assumptions (an individual’s beliefs about the nature of knowledge) and assumptions about human nature and agency (individual’s assumptions about the way we interact with our environment and relate to it) (Sikes, 2004, Bahari, 2010, Scotland, 2012, Ormston, et al. 2014, Marsh, et al. 2018 and Grix, 2019). These are colored by an individual’s values and beliefs that are shaped by their political allegiance, religious faith, gender, sexuality, historical and geographical location, ethnicity, race, social class, and status, (dis) abilities and so on (Sikes, 2004, Wellington, et al. 2005 and Marsh, et al. 2018). Positionality “reflects the position that the researcher has chosen to adopt within a given research study” (Savin-Baden & Major, 2013 p.71, emphasis mine). It influences both how research is conducted, its outcomes, and results (Rowe, 2014). It also influences what a researcher has chosen to investigate in prima instantia pertractis (Malterud, 2001; Grix, 2019).
Positionality is normally identified by locating the researcher about three areas: (1) the subject under investigation, (2) the research participants, and (3) the research context and process (ibid.). Some aspects of positionality are culturally ascribed or generally regarded as being fixed, for example, gender, race, skin-color, nationality. Others, such as political views, personal life-history, and experiences, are more fluid, subjective, and contextual (Chiseri-Strater, 1996). The fixed aspects may predispose someone towards a particular point or point of view, however, that does not mean that these necessarily automatically lead to particular views or perspectives. For example, one may think it would be antithetical for a black African-American to be a member of a white, conservative, right-wing, racist, supremacy group, and, equally, that such a group would not want African-American members. Yet Jansson(2010), in his research on The League of the South, found that not only did a group of this kind have an African-American member, but that he was “warmly welcomed” (ibid. p.21). Mullings (1999, p. 337) suggests that “making the wrong assumptions about the situatedness of an individual’s knowledge based on perceived identity differences may end… access to crucial informants in a research project”. This serves as a reminder that new researchers should not, therefore, make any assumptions about other’s perspectives & world-view and pigeonhole someone based on their own (mis)perceptions of them.
Reflexivity
Very little research in the social or educational field is or can be value-free (Carr, 2000). Positionality requires that both acknowledgment and allowance are made by the researcher to locate their views, values, and beliefs about the research design, conduct, and output(s). Self-reflection and a reflexive approach are both a necessary prerequisite and an ongoing process for the researcher to be able to identify, construct, critique, and articulate their positionality. Simply stated, reflexivity is the concept that researchers should acknowledge and disclose their selves in their research, seeking to understand their part in it, or influence on it (Cohen et al., 2011). Reflexivity informs positionality. It requires an explicit self-consciousness and self-assessment by the researcher about their views and positions and how these might, may, or have, directly or indirectly influenced the design, execution, and interpretation of the research data findings (Greenbank, 2003, May & Perry, 2017). Reflexivity necessarily requires sensitivity by the researcher to their cultural, political, and social context (Bryman, 2016) because the individual’s ethics, personal integrity, and social values, as well as their competency, influence the research process (Greenbank, 2003, Bourke, 2014).
As a way of researchers commencing a reflexive approach to their work Malterud (2001, p.484) suggests that Reflexivity starts by identifying preconceptions brought into the project by the researcher, representing previous personal and professional experiences, pre-study beliefs about how things are and what is to be investigated, motivation and qualifications for exploration of the field, and perspectives and theoretical foundations related to education and interests. It is important for new researchers to note that their values can, frequently, and usually do change over time. As such, the subjective contextual aspects of a researcher’s positionality or ‘situatedness’ change over time (Rowe, 2014). Through using a reflexive approach, researchers should continually be aware that their positionality is never fixed and is always situation and context-dependent. Reflexivity is an essential process for informing developing and shaping positionality, which may clearly articulated.
Positionality impacts the research process
It is essential for new researchers to acknowledge that their positionality is unique to them and that it can impact all aspects and stages of the research process. As Foote and Bartell (2011, p.46) identify “The positionality that researchers bring to their work, and the personal experiences through which positionality is shaped, may influence what researchers may bring to research encounters, their choice of processes, and their interpretation of outcomes.” Positionality, therefore, can be seen to affect the totality of the research process. It acknowledges and recognizes that researchers are part of the social world they are researching and that this world has already been interpreted by existing social actors. This is the opposite of a positivistic conception of objective reality (Cohen et al., 2011; Grix, 2019). Positionality implies that the social-historical-political location of a researcher influences their orientations, i.e., that they are not separate from the social processes they study.
Simply stated, there is no way we can escape the social world we live in to study it (Hammersley & Atkinson, 1995; Malterud, 2001). The use of a reflexive approach to inform positionality is a rejection of the idea that social research is separate from wider society and the individual researcher’s biography. A reflexive approach suggests that, rather than trying to eliminate their effect, researchers should acknowledge and disclose their selves in their work, aiming to understand their influence on and in the research process. It is important for new researchers to note here that their positionality not only shapes their work but influences their interpretation, understanding, and, ultimately, their belief in the truthfulness and validity of other’s research that they read or are exposed to. It also influences the importance given to, the extent of belief in, and their understanding of the concept of positionality.
Open and honest disclosure and exposition of positionality should show where and how the researcher believes that they have, or may have, influenced their research. The reader should then be able to make a better-informed judgment as to the researcher’s influence on the research process and how ‘truthful’ they feel the research data is. Sikes (2004, p.15) argues that It is important for all researchers to spend some time thinking about how they are paradigmatically and philosophically positioned and for them to be aware of how their positioning -and the fundamental assumptions they hold might influence their research related thinking in practice. This is about being a reflexive and reflective and, therefore, a rigorous researcher who can present their findings and interpretations in the confidence that they have thought about, acknowledged and been honest and explicit about their stance and the influence it has had upon their work. For new researchers doing this can be a complex, difficult, and sometimes extremely time-consuming process. Yet, it is essential to do so. Sultana (2007, p.380), for example, argues that it is “critical to pay attention to positionality, reflexivity, the production of knowledge… to undertake ethical research”. The clear implication being that, without reflexivity on the part of the researcher, their research may not be conducted ethically. Given that no contemporary researcher should engage in unethical research (BERA, 2018), reflexivity and clarification of one’s positionality may, therefore, be seen as essential aspects of the research process.
Finding your positionality
Savin-Baden & Major (2013) identify three primary ways that a researcher may identify and develop their positionality.
- Firstly, locating themselves about the subject (i.e., acknowledging personal positions that have the potential to influence the research.)
- Secondly, locating themselves about the participants (i.e., researchers individually considering how they view themselves, as well as how others view them, while at the same time acknowledging that as individuals they may not be fully aware of how they and others have constructed their identities, and recognizing that it may not be possible to do this without considered in-depth thought and critical analysis.)
- Thirdly, locating themselves about the research context and process. (i.e., acknowledging that research will necessarily be influenced by themselves and by the research context.
- To those, I would add a fourth component; that of time. Investigating and clarifying one’s positionality takes time. New researchers should recognize that exploring their positionality and writing a positionality statement can take considerable time and much ‘soul searching’. It is not a process that can be rushed.
Engaging in a reflexive approach should allow for a reduction of bias and partisanship (Rowe, 2014). However, it must be acknowledged by novice researchers that, no matter how reflexive they are, they can never objectively describe something as it is. We can never objectively describe reality (Dubois, 2015). It must also be borne in mind that language is a human social construct. Experiences and interpretations of language are individually constructed, and the meaning of words is individually and subjectively constructed (von-Glaserfield, 1988). Therefore, no matter how much reflexive practice a researcher engages in, there will always still be some form of bias or subjectivity. Yet, through exploring their positionality, the novice researcher increasingly becomes aware of areas where they may have potential bias and, over time, are better able to identify these so that they may then take account of them. (Ormston et al., 2014) suggest that researchers should aim to achieve ‘empathetic neutrality,’ i.e., that they should Strive to avoid obvious, conscious, or systematic bias and to be as neutral as possible in the collection, interpretation, and presentation of data…[while recognizing that] this aspiration can never be fully attained – all research will be influenced by the researcher and there is no completely ‘neutral’ or ‘objective’ knowledge.
Positionality statements
Regardless of how they are positioned in terms of their epistemological assumptions, it is crucial that researchers are clear in their minds as to the implications of their stance, that they state their position explicitly (Sikes, 2004). Positionality is often formally expressed in research papers, masters-level dissertations, and doctoral theses via a ‘positionality statement,’ essentially an explanation of how the researcher developed and how they became the researcher they are then. For most people, this will necessarily be a fluid statement that changes as they develop both through conducting a specific research project and throughout their research career.
A good strong positionality statement will typically include a description of the researcher’s lenses (such as their philosophical, personal, theoretical beliefs and perspective through which they view the research process), potential influences on the research (such as age, political beliefs, social class, race, ethnicity, gender, religious beliefs, previous career), the researcher’s chosen or pre-determined position about the participants in the project (e.g., as an insider or an outsider), the research-project context and an explanation as to how, where, when and in what way these might, may, or have, influenced the research process (Savin-Baden & Major, 2013). Producing a good positionality statement takes time, considerable thought, and critical reflection. It is particularly important for novice researchers to adopt a reflexive approach and recognize that “The inclusion of reflective accounts and the acknowledgment that educational research cannot be value-free should be included in all forms of research” (Greenbank, 2003).
Yet new researchers also need to realize that reflexivity is not a panacea that eradicates the need for awareness of the limits of self-reflexivity. Reflexivity can help to clarify and contextualize one’s position about the research process for both the researcher, the research participants, and readers of research outputs. Yet, it is not a guarantee of more honest, truthful, or ethical research. Nor is it a guarantee of good research (Delamont, 2018). No matter how critically reflective and reflexive one is, aspects of the self can be missed, not known, or deliberately hidden, see, for example, Luft and Ingham’s (1955) Johari Window – the ‘blind area’ known to others but not to oneself and the ‘hidden area,’ not known to others and not known to oneself. There are always areas of ourselves that we are not aware of, areas that only other people are aware of, and areas that no one is aware of. One may also, particularly in the early stages of reflection, not be as honest with one’s self as one needs to be (Holmes, 2019).
Novice researchers should realize that, right from the very start of the research process, that their positionality will affect their research and will impact Son their understanding, interpretation, acceptance, and belief, or non-acceptance and disbelief of other’s research findings. It will also influence their views about reflexivity and the relevance and usefulness of adopting a reflexive approach and articulating their positionality. Each researcher’s positionality affects the research process, and their outputs as well as their interpretation of other’s research. (Smith, 1999) neatly sums this up, suggesting that “Objectivity, authority and validity of knowledge is challenged as the researcher’s positionality... is inseparable from the research findings”.
Do you need lived experience to research a topic?
The position of the researcher as being an insider or an outsider to the culture being studied and, both, whether one position provides the researcher with an advantageous position compared with the other, and its effect on the research process (Hammersley 1993 and Weiner et al. 2012) has been, and remains, a key debate. One area of contention regarding the insider outsider debate is whether or not being an insider to the culture positions the researcher more, or less, advantageously than an outsider. Epistemologically this is concerned with whether and how it is possible to present information accurately and truthfully.
Merton’s long-standing definition of insiders and outsiders is that “Insiders are the members of specified groups and collectives or occupants of specified social statuses: Outsiders are non-members” (Merton, 1972). Others identify the insider as someone whose personal biography (gender, race, skin-color, class, sexual orientation and so on) gives them a ‘lived familiarity’ with and a priori knowledge of the group being researched. At the same time, the outsider is a person/researcher who does not have any prior intimate knowledge of the group being researched (Griffith, 1998, cited in Mercer, 2007). There are various lines of the argument put forward to emphasize the advantages and disadvantages of each position. In its simplest articulation, the insider perspective essentially questions the ability of outsider scholars to competently understand the experiences of those inside the culture, while the outsider perspective questions the ability of the insider scholar to sufficiently detach themselves from the culture to be able to study it without bias (Kusow, 2003).
For a more extensive discussion, see (Merton, 1972). The main arguments are outlined below. Advantages of an insider position include:
- (1) easier access to the culture being studied, as the researcher is regarded as being ‘one of us’ (Sanghera & Bjokert 2008),
- (2) the ability to ask more meaningful or insightful questions (due to possession of a priori knowledge),
- (3) the researcher may be more trusted so may secure more honest answers,
- (4) the ability to produce a more truthful, authentic or ‘thick’ description (Geertz, 1973) and understanding of the culture,
- (5) potential disorientation due to ‘culture shock’ is removed or reduced, and
- (6) the researcher is better able to understand the language, including colloquial language, and non-verbal cues.
Disadvantages of an insider position include:
- (1) the researcher may be inherently and unknowingly biased, or overly sympathetic to the culture,
- (2) they may be too close to and familiar with the culture (a myopic view), or bound by custom and code so that they are unable to raise provocative or taboo questions,
- (3) research participants may assume that because the insider is ‘one of us’ that they possess more or better insider knowledge than they do, (which they may not) and that their understandings are the same (which they may not be). Therefore information which should be ‘obvious’ to the insider, may not be articulated or explained,
- (4) an inability to bring an external perspective to the process,
- (5) ‘dumb’ questions which an outsider may legitimately ask, may not be able to be asked (Naaek et al. 2010), and
- (6) respondents may be less willing to reveal sensitive information than they would be to an outsider who they will have no future contact with.
Unfortunately, it is the case that each of the above advantages can, depending upon one’s perspective, be equally viewed as being disadvantages, and each of the disadvantages as being advantages, so that “The insider’s strengths become the outsider’s weaknesses and vice versa” (Merriam et al., 2001, p.411). Whether either position offers an advantage over the other is questionable. (Hammersley 1993) for example, argues that there are “No overwhelming advantages to being an insider or outside” but that each position has both advantages and disadvantages, which take on slightly different weights depending on the specific circumstances and the purpose of the research. Similarly, Mercer (2007) suggests that it is a ‘double-edged sword’ in that what is gained in one area may be lost in another, for example, detailed insider knowledge may mean that the ‘bigger picture’ is not seen.
There is also an argument that insider or outsider as opposites may be an artificial construct. There may be no clear dichotomy between the two positions (Herod, 1999), the researcher may not be either an insider or an outsider, but the positions can be seen as a continuum with conceptual rather than actual endpoints (Christensen & Dahl, 1997, cited in Mercer, 2007). Similarly, Mercer (ibid. p.1) suggests that The insider/outsider dichotomy is, in reality, a continuum with multiple dimensions and that all researchers constantly move back and forth along several axes, depending upon time, location, participants, and topic. I would argue that a researcher may inhabit multiple positions along that continuum at the same time. Merton (1972, p.28) argues that Sociologically speaking, there is nothing fixed about the boundaries separating Insiders from Outsiders. As situations involving different values arise, different statuses are activated, and the lines of separation shift. Traditionally emic and etic perspectives are “Often seen as being at odds - as incommensurable paradigms” (Morris et al. 1999 p.781). Yet the insider and outsider roles are essentially products of the particular situation in which research takes place (Kusow, 2003). As such, they are both researcher and context-specific, with no clearly -cut boundaries. And as such may not be a divided binary (Mullings, 1999, Chacko, 2004). Researchers may straddle both positions; they may be simultaneously and insider and an outsider (Mohammed, 2001).
For example, a mature female Saudi Ph.D. student studying undergraduate students may be an insider by being a student, yet as a doctoral student, an outsider to undergraduates. They may be regarded as being an insider by Saudi students, but an outsider by students from other countries; an insider to female students, but an outsider to male students; an insider to Muslim students, an outsider to Christian students; an insider to mature students, an outsider to younger students, and so on. Combine these with the many other insider-outsider positions, and it soon becomes clear that it is rarely a case of simply being an insider or outsider, but that of the researcher simultaneously residing in several positions. If insiderness is interpreted by the researcher as implying a single fixed status (such as sex, race, religion, etc.), then the terms insider and outsider are more likely to be seen by them as dichotomous, (because, for example, a person cannot be simultaneously both male and female, black and white, Christian and Muslim). If, on the other hand, a more pluralistic lens is used, accepting that human beings cannot be classified according to a single ascribed status, then the two terms are likely to be considered as being poles of a continuum (Mercer, 2007). The implication is that, as part of the process of reflexivity and articulating their positionality, novice researchers should consider how they perceive the concept of insider-outsiderness– as a continuum or a dichotomy, and take this into account. It has been suggested (e.g., Ritchie, et al. 2009, Kirstetter, 2012) that recent qualitative research has seen a blurring of the separation between insiderness and outsiderness and that it may be more appropriate to define a researcher’s stance by their physical and psychological distance from the research phenomenon under study rather than their paradigmatic position.
An example from the literature
To help novice researchers better understand and reflect on the insider-outsider debate, reference will be made to a paper by Herod (1999) “Reflections on interviewing foreign elites, praxis, positionality, validity and the cult of the leader”. This has been selected because it discusses the insider-outsider debate from the perspective of an experienced researcher who questions some of the assumptions frequently made about insider and outsiderness. Novice researchers who wish to explore insider-outsiderness in more detail may benefit from a thorough reading of this work along with those by Chacko (2004), and Mohammed, (2001). For more in-depth discussions of positionality, see (Clift et al. 2018).
Herod’s paper questions the epistemological assumption that an insider will necessarily produce ‘true’ knowledge, arguing that research is a social process in which the interviewer and interviewee participate jointly in knowledge creation. He posits three issues from the first-hand experience, which all deny the duality of simple insider-outsider positionality.
Firstly, the researcher’s ability to consciously manipulate their positionality, secondly that how others view the researcher may be very different from the researcher’s view, and thirdly, that positionality changes over time. In respect of the researcher’s ability to consciously manipulate their positionality he identifies that he deliberately presents himself in different ways in different situations, for example, presenting himself as “Dr.” when corresponding with Eastern European trade unions as the title conveys status, but in America presenting himself as a teacher without a title to avoid being viewed as a “disconnected academic in my ivory tower” (ibid. p.321).
Similarly, he identifies that he often ‘plays up’ his Britishness, emphasizing outsiderness because a foreign academic may, he feels, be perceived as being ‘harmless’ when compared to a domestic academic. Thus, interviewees may be more open and candid about certain issues. In respect of how others view the researcher’s positionality differently from the researcher’s view of themselves Herod identifies that his work has involved situations where objectively he is an outsider, and perceives of himself as such (i.e., is not a member of the cultural elite he is studying) but that others have not seen him as being an outsider— citing an example of research in Guyana where his permission to interview had been pre-cleared by a high-ranking government official, leading to the Guyanese trade union official who collected him from the airport to regard him as a ‘pseudo insider,’ inviting him to his house and treating him as though he were a member of the family. This, Herod indicates, made it more difficult for him to research than if he had been treated as an outsider.
Discussing how positionality may change over time, Herod argues that a researcher who is initially viewed as being an outsider will, as time progresses. More contact and discussion takes place, increasingly be viewed as an insider due to familiarity. He identifies that this particularly happens with follow-up interviews, in his case when conducting follow up interviews over three years, each a year apart in the Czech Republic; each time he went, the relationship was “more friendly and less distant” (ibid. p.324). Based on his experiences, Herod identifies that if we believe that the researcher and interviewee are co-partners in the creation of knowledge then the question as to whether it even really makes sense or is useful to talk about a dichotomy of insider and outsider remains, particularly given that the positionality of both may change through and across such categories over time or depending upon what attributes of each one’s identities are stressed(ibid. p.325).
Key Takeaways
- Positionality is integral to the process of qualitative research, as is the researcher’s awareness of the lack of stasis of our own and other’s positionality
- identifying and clearly articulating your positionality in respect of the project being undertaken may not be a simple or quick process, yet it is essential to do so.
- Pay particular attention to your multiple positions as an insider or outsider to the research participants and setting(s) where the work is conducted, acknowledging there may be both advantages and disadvantages that may have far-reaching implications for the process of data gathering and interpretation.
- While engaging in reflexive practice and articulating their positionality is not a guarantee of higher quality research, that through doing so, you will become a better researcher.
Exercises
- What is your relationship to the population in your study? (insider, outsider, both)
- How is your perspective on the topic informed by your lived experience?
- Any biases, beliefs, etc. that might influence you?
- Why do you want to answer your working question? (i.e., what is your research project's aim)
Go to Google News, YouTube or TikTok, or an internet search engine, and look for first-person narratives about your topic. Try to look for sources that include the person's own voice through quotations or video/audio recordings.
- How is your perspective on the topic different from the person in your narrative?'
- How do those differences relate to positionality?
- Look at a research article on your topic.
- How might the study have been different if the person in your narrative were part of the research team?
- What differences might there be in ethics, sampling, measures, or design?
10.4 Assessing measurement quality and fighting oppression
Learning Objectives
Learners will be able to...
- Define construct validity and construct reliability
- Apply measurement quality concepts to address issues of bias and oppression in social science
When researchers fail to account for their positionality as part of the research process, they often create or use measurements that produce biased results. In the previous chapter, we reviewed important aspects of measurement quality. For now, we want to broaden those conversations out slightly to the assumptions underlying quantitative research methods. Because quantitative methods are used as part of systems of social control, it is important to interrogate when their assumptions are violated in order to create social change.
Separating concepts from their measurement in empirical studies
Measurement in social science often involve unobservable theoretical constructs, such as socioeconomic status, teacher effectiveness, and risk of recidivism. As we discussed in Chapter 8, such constructs cannot be measured directly and must instead be inferred from measurements of observable properties (and other unobservable theoretical constructs) thought to be related to them—i.e., operationalized via a measurement model. This process, which necessarily involves making assumptions, introduces the potential for mismatches between the theoretical understanding of the construct purported to be measured and its operationalization.
Many of the harms discussed in the literature on fairness in computational systems are direct results of such mismatches. Some of these harms could have been anticipated and, in some cases, mitigated if viewed through the lens of measurement modeling. To do this, we contribute fairness oriented conceptualizations of construct reliability and construct validity that provide a set of tools for making explicit and testing assumptions about constructs and their operationalizations.
In essence, we want to make sure that the measures selected for a research project match with the conceptualization for that research project. Novice researchers and practitioners are often inclined to conflate constructs and their operationalization definitions—i.e., to collapse the distinctions between someone's anxiety and their score on the GAD-7 Anxiety inventory. But collapsing these distinctions, either colloquially or epistemically, makes it difficult to anticipate, let alone mitigate, any possible mismatches. When reading a research study, you should be able to see how the researcher's conceptualization informed what indicators and measurements were used. Collapsing the distinction between conceptual definitions and operational definitions is when fairness-related harms are most often introduced into the scientific process.
Making assumptions when measuring
Measurement modeling plays a central role in the quantitative social sciences, where many theories involve unobservable theoretical constructs—i.e., abstractions that describe phenomena of theoretical interest. For example, researchers in psychology and education have long been interested in studying intelligence, while political scientists and sociologists are often concerned with political ideology and socioeconomic status, respectively. Although these constructs do not manifest themselves directly in the world, and therefore cannot be measured directly, they are fundamental to society and thought to be related to a wide range of observable properties
A measurement model is a statistical model that links unobservable theoretical constructs, operationalized as latent variables, and observable properties—i.e., data about the world [30]. In this section, we give a brief overview of the measurement modeling process, starting with two comparatively simple examples—measuring height and measuring socioeconomic status—before moving on to three well-known examples from the literature on fairness in computational systems. We emphasize that our goal in this section is not to provide comprehensive mathematical details for each of our five examples, but instead to introduce key terminology and, more importantly, to highlight that the measurement modeling process necessarily involves making assumptions that must be made explicit and tested before the resulting measurements are used.
Assumptions of measuring height
We start by formalizing the process of measuring the height of a person—a property that is typically thought of as being observable and therefore easy to measure directly. There are many standard tools for measuring height, including rulers, tape measures, and height rods. Indeed, measurements of observable properties like height are sometimes called representational measurements because they are derived by “representing physical objects [such as people and rulers] and their relationships by numbers” [25]. Although the height of a person is not an unobservable theoretical construct, for the purpose of exposition, we refer to the abstraction of height as a construct H and then operationalize H as a latent variable h.
Despite the conceptual simplicity of height—usually understood to be the length from the bottom of a person’s feet to the top of their head when standing erect—measuring it involves making several assumptions, all of which are more or less appropriate in different contexts and can even affect different people in different ways. For example, should a person’s hair contribute to their height? What about their shoes? Neither are typically viewed as being an intrinsic part of a person’s height, yet both contribute to a person’s effective height, which may matter more in ergonomic contexts. Similarly, if a person uses a wheelchair, then their standing height may be less relevant than their sitting height. These assumptions must be made explicit and tested before using any measurements that depend upon them.
In practice, it is not possible to obtain error-free measurements of a person’s height, even when using standard tools. For example, when using a ruler, the angle of the ruler, the granularity of the marks, and human error can all result in erroneous measurements. However, if we take many measurements of a person’s height, then provided that the ruler is not statistically biased, the average will converge to the person’s “true” height h. If we were to measure them infinite times, we would be able to measure their exact height perfectly. with our probability of doing so increasing the more times we measure.
In our measurement model, we say that the person’s true height—the latent variable h—influences the measurements every time we observe it. We refer to models that formalize the relationships between measurements and their errors as measurement error models. In many contexts, it is reasonable to assume that the errors associated will not impact the consistency or accuracy of a measure as long as the error is normally distributed, statistically unbiased, and possessing small variance. However, in some contexts, the measurement error may not behave like researcher expect and may even be correlated with demographic factors, such as race or gender.
As an example, suppose that our measurements come not from a ruler but instead from self-reports on dating websites. It might initially seem reasonable to assume that the corresponding errors are well-behaved in this context. However, Toma et al. [54] found that although men and women both over-report their height on dating websites, men are more likely to over-report and to over-report by a larger amount. Toma et al. suggest this is strategic, likely representing intentional deception. However, regardless of the cause, these errors are not well-behaved and are correlated with gender. Assuming that they are well-behaved will yield inaccurate measurements.
Measuring socioeconomic status
We now consider the process of measuring a person’s socioeconomic status (SES). From a theoretical perspective, a person’s SES is understood as encompassing their social and economic position in relation to others. Unlike a person’s height, their SES is unobservable, so it cannot be measured directly and must instead be inferred from measurements of observable properties (and other unobservable theoretical constructs) thought to be related to it, such as income, wealth, education, and occupation. Measurements of phenomena like SES are sometimes called pragmatic measurements because they are designed to capture particular aspects of a phenomenon for particular purposes [25].
We refer to the abstraction of SES as a construct S and then operationalize S as a latent variable s. The simplest way to measure a person’s SES is to use an observable property—like their income—as an indicator for it. Letting the construct I represent the abstraction of income and operationalizing I as a latent variable i, this means specifying a both measurement model that links s and i and a measurement error model. For example, if we assume that s and i are linked via the identity function—i.e., that s = i—and we assume that it is possible to obtain error-free measurements of a person’s income—i.e., that ˆi = i—then s = ˆi. Like the previous example, this example highlights that the measurement modeling process necessarily involves making assumptions. Indeed, there are many other measurement models that use income as a proxy for SES but make different assumptions about the specific relationship between them.
Similarly, there are many other measurement error models that make different assumptions about the errors that occur when measuring a person’s income. For example, if we measure a person’s monthly income by totaling the wages deposited into their account over a single one-month period, then we must use a measurement error model that accounts for the possibility that the timing of the one-month period and the timings of their wage deposits may not be aligned. Using a measurement error model that does not account for this possibility—e.g., using ˆi = i—will yield inaccurate measurements.
Human Rights Watch reported exactly this scenario in the context of the Universal Credit benefits system in the U.K. [55]: The system measured a claimant’s monthly income using a one-month rolling period that began immediately after they submitted their claim without accounting for the possibility described above. This meant that the system “might detect that an individual received a £1000 paycheck on March 30 and another £1000 on April 29, but not that each £1000 salary is a monthly wage [leading it] to compute the individual’s benefit in May based on the incorrect assumption that their combined earnings for March and April (i.e., £2000) are their monthly wage,” denying them much-needed resources. Moving beyond income as a proxy for SES, there are arbitrarily many ways to operationalize SES via a measurement model, incorporating both measurements of observable properties, such as wealth, education, and occupation, as well as measurements of other unobservable theoretical constructs, such as cultural capital.
Measuring teacher effectiveness
At the risk of stating the obvious, teacher effectiveness is an unobservable theoretical construct that cannot be measured directly and must instead be inferred from measurements of observable properties (and other unobservable theoretical constructs). Many organizations have developed models that purport to measure teacher effectiveness. For instance, SAS’s Education Value-Added Assessment System (EVAAS), which is widely used across the U.S., implements two models—a multivariate response model (MRM) intended to be used when standardized tests are given to students in consecutive grades and a univariate response model intended to be used in other testing contexts. Although the models differ in terms of their mathematical details, both use changes in students’ test scores (an observable property) as a proxy for teacher effectiveness
We focus on the EVAAS MRM in this example, though we emphasize that many of the assumptions that it makes—most notably that students’ test scores are a reasonable proxy for teacher effectiveness—are common to other value-added models. When describing the MRM, the EVAAS documentation states that “each teacher is assumed to be the state or district average in a specific year, subject, and grade until the weight of evidence pulls him or her above or below that average”
As well as assuming that teacher effectiveness is fully captured by students’ test scores, this model makes several other assumptions, which we make explicit here for expository purposes: 1) that student i’s test score for subject j in grade k in year l is a function of only their current and previous teachers’ effects; 2) that the effectiveness of teacher t for subject j, grade k, and year l depends on their effects on all of their students; 3) that student i’s instructional time for subject j in grade k in year l may be shared between teachers; and 4) that a teacher may be effective in one subject but ineffective in another.
Critically evaluating the assumptions of measurement models
We now consider another well-known example from the literature on fairness in computational systems: the risk assessment models used in the U.S. justice system to measure a defendant’s risk of recidivism. There are many such models, but we focus here on Northpointe’s Correctional Offender Management Profiling for Alternative Sanctions (COMPAS), which was the subject of an investigation by Angwin et al. [4] and many academic papers [e.g., 9, 14, 34].
COMPAS draws on several criminological theories to operationalize a defendant’s risk of recidivism using measurements of a variety of observable properties (and other unobservable theoretical constructs) derived from official records and interviews. These properties and measurements span four different dimensions: prior criminal history, criminal associates, drug involvement, and early indicators of juvenile delinquency problems [19]. The measurements are combined in a regression model, which outputs a score that is converted to a number between one and ten with ten being the highest risk. Although the full mathematical details of COMPAS are not readily available, the COMPAS documentation mentions numerous assumptions, the most important of which is that recidivism is defined as “a new misdemeanor or felony arrest within two years.” We discuss the implications of this assumption after we introduce our second example.
Finally, we turn to a different type of risk assessment model, used in the U.S. healthcare system to identify the patients that will benefit the most from enrollment in high-risk care management programs— i.e., programs that provide access to additional resources for patients with complex health issues. As explained by Obermeyer et al., these models assume that “those with the greatest care needs will benefit the most from the programs” [43]. Furthermore, many of them operationalize greatest care needs as greatest care costs. This assumption—i.e., that care costs are a reasonable proxy for care needs—transforms the difficult task of measuring the extent to which a patient will benefit from a program (an unobservable theoretical construct) into the simpler task of predicting their future care costs based on their past care costs (an observable property). However, this assumption masks an important confounding factor: patients with comparable past care needs but different access to care will likely have different past care costs. As we explain in the next section, even without considering any other details of these models, this assumption can lead to fairness-related harms.
The measurement modeling process necessarily involves making assumptions. However, these assumptions must be made explicit and tested before the resulting measurements are used. Leaving them implicit or untested obscures any possible mismatches between the theoretical understanding of the construct purported to be measured and its operationalization, in turn obscuring any resulting fairness-related harms. In this section we apply and extend the measurement quality concepts from Chapter 9 to address specifically aspects of fairness and social justice.
Quantitative social scientists typically test their assumptions by assessing construct reliability and construct validity. Quinn et al. describe these concepts as follows: “The evaluation of any measurement is generally based on its reliability (can it be repeated?) and validity (is it right?). Embedded within the complex notion of validity are interpretation (what does it mean?) and application (does it ‘work?’)” [49]. We contribute fairness-oriented conceptualizations of construct reliability and construct validity that draw on the work of Quinn et al. [49], Jackman [30], Messick [40], and Loevinger [36], among others. We illustrate these conceptualizations using the five examples introduced in the previous section, arguing that they constitute a set of tools that will enable researchers and practitioners to 1) better anticipate fairness-related harms that can be obscured by focusing primarily on out-of-sample prediction, and 2) identify potential causes of fairness-related harms in ways that reveal concrete, actionable avenues for mitigating them
Construct reliability
We start by describing construct reliability—a concept that is roughly analogous to the concept of precision (i.e., the inverse of variance) in statistics [30]. Assessing construct reliability means answering the following question: do similar inputs to a measurement model, possibly presented at different points in time, yield similar outputs? If the answer to this question is no, then the model lacks reliability, meaning that we may not want to use its measurements. We note that a lack of reliability can also make it challenging to assess construct validity. Although different disciplines emphasize different aspects of construct reliability, we argue that there is one aspect— namely test–retest reliability, which we describe below—that is especially relevant in the context of fairness in computational systems.4
Test–retest reliability
Test–retest reliability refers to the extent to which measurements of an unobservable theoretical construct, obtained from a measurement model at different points in time, remain the same, assuming that the construct has not changed. For example, when measuring a person’s height, operationalized as the length from the bottom of their feet to the top of their head when standing erect, measurements that vary by several inches from one day to the next would suggest a lack of test–retest reliability. Investigating this variability might reveal its cause to be the assumption that a person’s shoes should contribute to their height.
As another example, many value-added models, including the EVAAS MRM, have been criticized for their lack of test–retest reliability. For instance, in Weapons of Math Destruction [46], O’Neil described how value-added models often produce measurements of teacher effectiveness that vary dramatically between years. In one case, she described Tim Clifford, an accomplished and respected New York City middle school teacher with over 26 years of teaching experience. For two years in a row, Clifford was evaluated using a value-added model, receiving a score of 6 out of 100 in the first year, followed by a score of 96 in the second. It is extremely unlikely that teacher effectiveness would vary so dramatically from one year to the next. Instead, this variability, which suggests a lack of test–retest reliability, points to a possible mismatch between the construct purported to be measured and its operationalization.
As a third example, had the developers of the Universal Credit benefits system described in section 2.2 assessed the test–retest reliability of their system by checking that the system’s measurements of a claimant’s income were the same no matter when their one-month rolling period began, they might have anticipated (and even mitigated) the harms revealed by Human Rights Watch [55].
Finally, we note that an apparent lack of test–retest reliability does not always point to a mismatch between the theoretical understanding of the construct purported to be measured and its operationalization. In some cases, an apparent lack of test–retest reliability can instead be the result of unexpected changes to the construct itself. For example, although we typically think of a person’s height as being something that remains relatively static over the course of their adult life, most people actually get shorter as they get older.
Construct Validity
Whereas construct reliability is roughly analogous to the concept of precision in statistics, construct validity is roughly analogous to the concept of statistical unbiasedness [30]. Establishing construct validity means demonstrating, in a variety of ways, that the measurements obtained from measurement model are both meaningful and useful: Does the operationalization capture all relevant aspects of the construct purported to be measured? Do the measurements look plausible? Do they correlate with other measurements of the same construct? Or do they vary in ways that suggest that the operationalization may be inadvertently capturing aspects of other constructs? Are the measurements predictive of measurements of any relevant observable properties (and other unobservable theoretical constructs) thought to be related to the construct, but not incorporated into the operationalization? Do the measurements support known hypotheses about the construct? What are the consequences of using the measurements—including any societal impacts [40, 52]. We emphasize that a key feature, not a bug, of construct validity is that it is not a yes/no box to be checked: construct validity is always a matter of degree, to be supported by critical reasoning [36].
Different disciplines have different conceptualizations of construct validity, each with its own rich history. For example, in some disciplines, construct validity is considered distinct from content validity and criterion validity, while in other disciplines, content validity and criterion validity are grouped under the umbrella of construct validity. Our conceptualization unites traditions from political science, education, and psychology by bringing together the seven different aspects of construct validity that we describe below. We argue that each of these aspects plays a unique and important role in understanding fairness in computational systems.
Face validity
Face validity refers to the extent to which the measurements obtained from a measurement model look plausible— a “sniff test” of sorts. This aspect of construct validity is inherently subjective, so it is often viewed with skepticism if it is not supplemented with other, less subjective evidence. However, face validity is a prerequisite for establishing construct validity: if the measurements obtained from a measurement model aren’t facially valid, then they are unlikely to possess other aspects of construct validity.
It is likely that the models described thus far would yield measurements that are, for the most part, facially valid. For example, measurements obtained by using income as a proxy for SES would most likely possess face validity. SES and income are certainly related and, in general, a person at the high end of the income distribution (e.g., a CEO) will have a different SES than a person at the low end (e.g., a barista). Similarly, given that COMPAS draws on several criminological theories to operationalize a defendant’s risk of recidivism, it is likely that the resulting scores would look plausible. One exception to this pattern is the EVAAS MRM. Some scores may look plausible—after all, students’ test scores are not unrelated to teacher effectiveness—but the dramatic variability that we described above in the context of test–retest reliability is implausible.
Content validity
Content validity refers to the extent to which an operationalization wholly and fully captures the substantive nature of the construct purported to be measured. This aspect of construct validity has three sub-aspects, which we describe below.
The first sub-aspect relates to the construct’s contestedness. If a construct is essentially contested then it has multiple context dependent, and sometimes even conflicting, theoretical understandings. Contestedness makes it inherently hard to assess content validity: if a construct has multiple theoretical understandings, then it is unlikely that a single operationalization can wholly and fully capture its substantive nature in a meaningful fashion. For this reason, some traditions make a single theoretical understanding of the construct purported to be measured a prerequisite for establishing content validity [25, 30]. However, other traditions simply require an articulation of which understanding is being operationalized [53]. We take the perspective that the latter approach is more practical because it is often the case that unobservable theoretical constructs are essentially contested, yet we still wish to measure them.
Of the models described previously, most are intended to measure unobservable theoretical constructs that are (relatively) uncontested. One possible exception is patient benefit, which can be understood in a variety of different ways. However, the understanding that is operationalized in most high-risk care management enrollment models is clearly articulated. As Obermeyer et al. explain, “[the patients] with the greatest care needs will benefit the most” from enrollment in high-risk care management programs [43].
The second sub-aspect of content validity is sometimes known as substantive validity. This sub-aspect moves beyond the theoretical understanding of the construct purported to be measured and focuses on the measurement modeling process—i.e., the assumptions made when moving from abstractions to mathematics. Establishing substantive validity means demonstrating that the operationalization incorporates measurements of those—and only those—observable properties (and other unobservable theoretical constructs, if appropriate) thought to be related to the construct. For example, although a person’s income contributes to their SES, their income is by no means the only contributing factor. Wealth, education, and occupation all affect a person’s SES, as do other unobservable theoretical constructs, such as cultural capital. For instance, an artist with significant wealth but a low income should have a higher SES than would be suggested by their income alone.
As another example, COMPAS defines recidivism as “a new misdemeanor or felony arrest within two years.” By assuming that arrests are a reasonable proxy for crimes committed, COMPAS fails to account for false arrests or crimes that do not result in arrests [50]. Indeed, no computational system can ever wholly and fully capture the substantive nature of crime by using arrest data as a proxy. Similarly, high-risk care management enrollment models assume that care costs are a reasonable proxy for care needs. However, a patient’s care needs reflect their underlying health status, while their care costs reflect both their access to care and their health status.
Finally, establishing structural validity, the third sub-aspect of content validity, means demonstrating that the operationalization captures the structure of the relationships between the incorporated observable properties (and other unobservable theoretical constructs, if appropriate) and the construct purported to be measured, as well as the interrelationships between them [36, 40].
In addition to assuming that teacher effectiveness is wholly and fully captured by students’ test scores—a clear threat to substantive validity [2]—the EVAAS MRM assumes that a student’s test score for subject j in grade k in year l is approximately equal to the sum of the state or district’s estimated mean score for subject j in grade k in year l and the student’s current and previous teachers’ effects (weighted by the fraction of the student’s instructional time attributed to each teacher). However, this assumption ignores the fact that, for many students, the relationship may be more complex.
Convergent validity
Convergent validity refers to the extent to which the measurements obtained from a measurement model correlate with other measurements of the same construct, obtained from measurement models for which construct validity has already been established. This aspect of construct validity is typically assessed using quantitative methods, though doing so can reveal qualitative differences between different operationalizations.
We note that assessing convergent validity raises an inherent challenge: “If a new measure of some construct differs from an established measure, it is generally viewed with skepticism. If a new measure captures exactly what the previous one did, then it is probably unnecessary” [49]. The measurements obtained from a new measurement model should therefore deviate only slightly from existing measurements of the same construct. Moreover, for the model to be viewed as possessing convergent validity, these deviations must be well justified and supported by critical reasoning.
Many value-added models, including the EVAAS MRM, lack convergent validity [2]. For example, in Weapons of Math Destruction [46], O’Neil described Sarah Wysocki, a fifth-grade teacher who received a low score from a value-added model despite excellent reviews from her principal, her colleagues, and her students’ parents.
As another example, measurements of SES obtained from the model described previously and measurements of SES obtained from the National Committee on Vital and Health Statistics would likely correlate somewhat because both operationalizations incorporate income. However, the latter operationalization also incorporates measurements of other observable properties, including wealth, education, occupation, economic pressure, geographic location, and family size [45]. As a result, it is also likely that there would also be significant differences between the two sets of measurements. Investigating these differences might reveal aspects of the substantive nature of SES, such as wealth or education, that are missing from the model described in section 2.2. In other words, and as we described above, assessing convergent validity can reveal qualitative differences between different operationalizations of a construct.
We emphasize that assessing the convergent validity of a measurement model using measurements obtained from measurement models that have not been sufficiently well validated can yield a false sense of security. For example, scores obtained from COMPAS would likely correlate with scores obtained from other models that similarly use arrests as a proxy for crimes committed, thereby obscuring the threat to content validity that we described above.
Discriminant validity
Discriminant validity refers to the extent to which the measurements obtained from a measurement model vary in ways that suggest that the operationalization may be inadvertently capturing aspects of other constructs. Measurements of one construct should only correlate with measurements of another to the extent that those constructs are themselves related. As a special case, if two constructs are totally unrelated, then there should be no correlation between their measurements [25].
Establishing discriminant validity can be especially challenging when a construct has relationships with many other constructs. SES, for example, is related to almost all social and economic constructs, albeit to varying extents. For instance, SES and gender are somewhat related due to labor segregation and the persistent gender wage gap, while SES and race are much more closely related due to historical racial inequalities resulting from structural racism. When assessing the discriminant validity of the model described previously, we would therefore hope to find correlations that reflect these relationships. If, however, we instead found that the resulting measurements were perfectly correlated with gender or uncorrelated with race, this would suggest a lack of discriminant validity.
As another example, Obermeyer et al. found a strong correlation between measurements of patients’ future care needs, operationalized as future care costs, and race [43]. According to their analysis of one model, only 18% of the patients identified for enrollment in highrisk care management programs were Black. This correlation contradicts expectations. Indeed, given the enormous racial health disparities in the U.S., we might even expect to see the opposite pattern. Further investigation by Obermeyer et al. revealed that this threat to discriminant validity was caused by the confounding factor that we described in section 2.5: Black and white patients with comparable past care needs had radically different past care costs—a consequence of structural racism that was then exacerbated by the model.
Predictive validity
Predictive validity refers to the extent to which the measurements obtained from a measurement model are predictive of measurements of any relevant observable properties (and other unobservable theoretical constructs) thought to be related to the construct purported to be measured, but not incorporated into the operationalization. Assessing predictive validity is therefore distinct from out-of-sample prediction [24, 41]. Predictive validity can be assessed using either qualitative or quantitative methods. We note that in contrast to the aspects of construct validity that we discussed above, predictive validity is primarily concerned with the utility of the measurements, not their meaning.
As a simple illustration of predictive validity, taller people generally weigh more than shorter people. Measurements of a person’s height should therefore be somewhat predictive of their weight. Similarly, a person’s SES is related to many observable properties— ranging from purchasing behavior to media appearances—that are not always incorporated into models for measuring SES. Measurements obtained by using income as a proxy for SES would most likely be somewhat predictive of many of these properties, at least for people at the high and low ends of the income distribution.
We note that the relevant observable properties (and other unobservable theoretical constructs) need not be “downstream” of (i.e., thought to be influenced by) the construct. Predictive validity can also be assessed using “upstream” properties and constructs, provided that they are not incorporated into the operationalization. For example, Obermeyer et al. investigated the extent to which measurements of patients’ future care needs, operationalized as future care costs, were predictive of patients’ health statuses (which were not part of the model that they analyzed) [43]. They found that Black and white patients with comparable future care costs did not have comparable health statuses—a threat to predictive validity caused (again) by the confounding factor described previously.
Hypothesis validity
Hypothesis validity refers to the extent to which the measurements obtained from a measurement model support substantively interesting hypotheses about the construct purported to be measured. Much like predictive validity, hypothesis validity is primarily concerned with the utility of the measurements. We note that the main distinction between predictive validity and hypothesis validity hinges on the definition of “substantively interesting hypotheses.” As a result, the distinction is not always clear cut. For example, is the hypothesis “People with higher SES are more likely to be mentioned in the New York Times” sufficiently substantively interesting? Or would it be more appropriate to use the hypothesized relationship to assess predictive validity? For this reason, some traditions merge predictive and hypothesis validity [e.g., 30].
Turning again to the value-added models discussed previously, it is extremely unlikely that the dramatically variable scores obtained from such models would support most substantively interesting hypotheses involving teacher effectiveness, again suggesting a possible mismatch between the theoretical understanding of the construct purported to be measured and its operationalization.
Using income as a proxy for SES would likely support some— though not all—substantively interesting hypotheses involving SES. For example, many social scientists have studied the relationship between SES and health outcomes, demonstrating that people with lower SES tend to have worse health outcomes. Measurements of SES obtained from the model described previously would likely support this hypothesis, albeit with some notable exceptions. For instance, wealthy college students often have low incomes but good access to healthcare. Combined with their young age, this means that they typically have better health outcomes than other people with comparable incomes. Examining these exceptions might reveal aspects of the substantive nature of SES, such as wealth and education, that are missing from the model described previously.
Consequential validity
Consequential validity, the final aspect in our fairness-oriented conceptualization of construct validity, is concerned with identifying and evaluating the consequences of using the measurements obtained from a measurement model, including any societal impacts. Assessing consequential validity often reveals fairness-related harms. Consequential validity was first introduced by Messick, who argued that the consequences of using the measurements obtained from a measurement model are fundamental to establishing construct validity [40]. This is because the values that are reflected in those consequences both derive from and contribute back the theoretical understanding of the construct purported to be measured. In other words, the “measurements both reflect structure in the natural world, and impose structure upon it,” [26]—i.e., the measurements shape the ways that we understand the construct itself. Assessing consequential validity therefore means answering the following questions: How is the world shaped by using the measurements? What world do we wish to live in? If there are contexts in which the consequences of using the measurements would cause us to compromise values that we wish to uphold, then the measurements should not be used in those contexts.
For example, when designing a kitchen, we might use measurements of a person’s standing height to determine the height at which to place their kitchen countertop. However, this may render the countertop inaccessible to them if they use a wheelchair. As another example, because the Universal Credit benefits system described previously assumed that measuring a person’s monthly income by totaling the wages deposited into their account over a single one-month period would yield error-free measurements, many people—especially those with irregular pay schedules— received substantially lower benefits than they were entitled to.
The consequences of using scores obtained from value-added models are well described in the literature on fairness in measurement. Many school districts have used such scores to make decisions about resource distribution and even teachers’ continued employment, often without any way to contest these decisions [2, 3]. In turn, this has caused schools to manipulate their scores and encouraged teachers to “teach to the test,” instead of designing more diverse and substantive curricula [46]. As well as the cases described above in sections 3.1.1 and 3.2.3, in which teachers were fired on the basis of low scores despite evidence suggesting that their scores might be inaccurate, Amrein-Beardsley and Geiger [3] found that EVAAS consistently gave lower scores to teachers at schools with higher proportions of non-white students, students receiving special education services, lower-SES students, and English language learners. Although it is possible that more effective teachers simply chose not to teach at those schools, it is far more likely that these lower scores reflect societal biases and structural inequalities. When scores obtained from value-added models are used to make decisions about resource distribution and teachers’ continued employment, these biases and inequalities are then exacerbated.
The consequences of using scores obtained from COMPAS are also well described in the literature on fairness in computational systems, most notably by Angwin et al. [4], who showed that COMPAS incorrectly scored Black defendants as high risk more often than white defendants, while incorrectly scoring white defendants as low risk more often than Black defendants. By defining recidivism as “a new misdemeanor or felony arrest within two years,” COMPAS fails to account for false arrests or crimes that do not result in arrests. This assumption therefore encodes and exacerbates racist policing practices, leading to the racial disparities uncovered by Angwin et al. Indeed, by using arrests as a proxy for crimes committed, COMPAS can only exacerbate racist policing practices, rather than transcending them [7, 13, 23, 37, 39]. Furthermore, the COMPAS documentation asserts that “the COMPAS risk scales are actuarial risk assessment instruments. Actuarial risk assessment is an objective method of estimating the likelihood of reoffending. An individual’s level of risk is estimated based on known recidivism rates of offenders with similar characteristics” [19]. By describing COMPAS as an “objective method,” Northpointe misrepresents the measurement modeling process, which necessarily involves making assumptions and is thus never objective. Worse yet, the label of objectiveness obscures the organizational, political, societal, and cultural values that are embedded in COMPAS and reflected in its consequences.
Finally, we return to the high-risk care management models described in section 2.5. By operationalizing greatest care needs as greatest care costs, these models fail to account for the fact that patients with comparable past care needs but different access to care will likely have different past care costs. This omission has the greatest impact on Black patients. Indeed, when analyzing one such model, Obermeyer et al. found that only 18% of the patients identified for enrollment were Black [43]. In addition, Obermeyer et al. found that Black and white patients with comparable future care costs did not have comparable health statuses. In other words, these models exacerbate the enormous racial health disparities in the U.S. as a consequence of a seemingly innocuous assumption.
Measurement: The power to create truth*
Because measurement modeling is often skipped over, researchers and practitioners may be inclined to collapse the distinctions between constructs and their operationalizations in how they talk about, think about, and study the concepts in their research question. But collapsing these distinctions removes opportunities to anticipate and mitigate fairness-related harms by eliding the space in which they are most often introduced. Further compounding this issue is the fact that measurements of unobservable theoretical constructs are often treated as if they were obtained directly and without errors—i.e., a source of ground truth. Measurements end up standing in for the constructs purported to be measured, normalizing the assumptions made during the measurement modeling process and embedding them throughout society. In other words, “measures are more than a creation of society, they create society." [1]. Collapsing the distinctions between constructs and their operationalizations is therefore not just theoretically or pedantically concerning—it is practically concerning with very real, fairness-related consequences.
We argue that measurement modeling provides a both a language for articulating the distinctions between constructs and their operationalizations and set of tools—namely construct reliability and construct validity—for surfacing possible mismatches. In section 3, we therefore proposed fairness-oriented conceptualizations of construct reliability and construct validity, uniting traditions from political science, education, and psychology. We showed how these conceptualizations can be used to 1) anticipate fairness-related harms that can be obscured by focusing primarily on out-of-sample prediction, and 2) identify potential causes of fairness-related harms in ways that reveal concrete, actionable avenues for mitigating them. We acknowledge that assessing construct reliability and construct validity can be time-consuming. However, ignoring them means that we run the risk of creating a world that we do not wish to live in.
.
Key Takeaways
- Mismatches between conceptualization and measurement are often places in which bias and systemic injustice enter the research process.
- Measurement modeling is a way of foregrounding researcher's assumptions in how they connect their conceptual definitions and operational definitions.
- Social work research consumers should critically evaluate the construct validity and reliability of measures in the studies of social work populations.
Exercises
- Examine an article that uses quantitative methods to investigate your topic area.
- Identify the conceptual definitions the authors used.
- These are usually in the introduction section.
- Identify the operational definitions the authors used.
- These are usually in the methods section in a subsection titled measures.
- List the assumptions that link the conceptual and operational definitions.
- For example, that attendance can be measured by a classroom sign-in sheet.
- Do the authors identify any limitations for their operational definitions (measures) in the limitations or methods section?
- Do you identify any limitations in how the authors operationalized their variables?
- Apply the specific subtypes of construct validity and reliability.
Chapter Outline
- Collecting your own data vs. using available data (24 minute read)
- The sampling process (25 minute read)
- Sampling approaches for quantitative research (15 minute read)
- Sample quality (24 minute read)
Content warning: examples contain references to addiction to technology, domestic violence and batterer intervention, cancer, illegal drug use, LGBTQ+ discrimination, binge drinking, intimate partner violence among college students, child abuse, neocolonialism and Western hegemony.
10.1 Collecting your own data or using someone else's
Learning Objectives
- Describe the ethical and practical considerations that impact collecting data
- Describe the strengths and limitations of secondary data analysis
- Evaluate whether data repositories or cultural artifacts may provide relevant data for your working question.
You're a researcher. Let's say you are interested in better understanding the day-to-day experiences of maximum security prisoners. This sounds fascinating, but unless you plan to commit a crime that lands you in a maximum security prison, gaining access to that particular population would be difficult for a anyone without a lot of time and credibility. For example, this study would need to get the informed consent of research participants, While the topics about which social work questions can be asked may seem limitless, there are limits to which aspects of topics we can study or at least to the ways we can study them. In this chapter, we will discuss the ethical and practical constraints under which scientists collect data for analysis.
Feasibility
Feasibility refers to whether a researcher can practically conduct the study they plan to do, given the resources and ethical obligations they have. For most student projects, you will not have to carry out any project you propose. In this case, feasibility is less of a concern because, well, you don't actually have to do anything--just write about what you might do to answer your question. So, you'll propose a project that could work in theory. However, for students who have to carry out the projects in their research proposals, feasibility is incredibly important.
In this section, we will review the important practical and ethical considerations student researchers should start thinking about from the beginning of a research project. Take the perspective of a researcher in an empirical journal article you are reading. Consider how these issues impact who gets to participate in the study, and eventually, how generalizable the results are to everyone with the issue.
Access, consent, and ethical obligations
One of the most important feasibility issues is gaining access to your target population. For example, let’s say you wanted to better understand middle-school students who engaged in self-harm behaviors. That is a topic of social importance, so why might it make for a difficult student project? Let's say you proposed to identify students from a local middle school and interview them about self-harm. Methodologically, that sounds great since you are getting data from those with the most knowledge about the topic, the students themselves. But practically, that sounds challenging. Think about the ethical obligations a social work practitioner has to adolescents who are engaging in self-harm (e.g., competence, respect). In research, we are similarly concerned mostly with the benefits and harms of what you propose to do as well as the openness and honesty with which you share your project publicly.

Gatekeepers
If you were the principal at your local middle school, would you allow an MSW student to interview kids in your schools about self-harm? What if the results of the study showed that self-harm was a big problem that your school was not addressing? What if the researcher's interviews themselves caused an increase in self-harming behaviors among the children? The principal in this situation is a gatekeeper. Gatekeepers are the individuals or organizations who control access to the population you want to study. The school board would also likely need to give consent for the research to take place at their institution. Gatekeepers must weigh their ethical questions because they have a responsibility to protect the safety of the people at their organization, just as you have an ethical obligation to protect the people in your research study.
For student projects, it can be a challenge to get consent from gatekeepers to conduct your research project. As a result, students often conduct research projects at their place of employment or field work, as they have established trust with gatekeepers in those locations. I'm still doubtful an MSW student interning at the middle school would be able to get consent for this study, but they probably have a better chance than a researcher with no relationship to the school. In the case where the population (children who self-harm) are too vulnerable, student researchers may collect data from people who have secondary knowledge about the topic. For example, the principal may be more willing to let you talk to teachers or staff, rather than children. I commonly see student projects that focus on studying practitioners rather than clients for this reason.
Stakeholders
In some cases, researchers and gatekeepers partner on a research project. When this happens, the gatekeepers become stakeholders. Stakeholders are individuals or groups who have an interest in the outcome of the study you conduct. As you think about your project, consider whether there are formal advisory groups or boards (like a school board) or advocacy organizations who already serve or work with your target population. Approach them as experts an ask for their review of your study to see if there are any perspectives or details you missed that would make your project stronger.
There are many advantages to partnering with stakeholders to complete a research project together. Continuing with our example on self-harm in schools, in order to obtain access to interview children at a middle school, you will have to consider other stakeholders' goals. School administrators also want to help students struggling with self-harm, so they may want to use the results to form new programs. But they may also need to avoid scandal and panic if the results show high levels of self-harm. Most likely, they want to provide support to students without making the problem worse. By bringing in school administrators as stakeholders, you can better understand what the school is currently doing to address the issue and get an informed perspective on your project's questions. Negotiating the boundaries of a stakeholder relationship requires strong meso-level practice skills.
Of course, partnering with administrators probably sounds quite a bit easier than bringing on board the next group of stakeholders—parents. It's not ethical to ask children to participate in a study without their parents' consent. We will review the parameters of parental and child consent in Chapter 5. Parents may be understandably skeptical of a researcher who wants to talk to their child about self-harm, and they may fear potential harms to the child and family from your study. Would you let a researcher you didn't know interview your children about a very sensitive issue?
Social work research must often satisfy multiple stakeholders. This is especially true if a researcher receives a grant to support the project, as the funder has goals it wants to accomplish by funding the research project. Your MSW program and university are also stakeholders in your project. When you conduct research, it reflects on your school. If you discover something of great importance, your school looks good. If you harm someone, they may be liable. Your university likely has opportunities for you to share your research with the campus community, and may have incentives or grant programs for student researchers. Your school also provides you with support through instruction and access to resources like the library and data analysis software.
Target population
So far, we've talked about access in terms of gatekeepers and stakeholders. Let's assume all of those people agree that your study should proceed. But what about the people in the target population? They are the most important stakeholder of all! Think about the children in our proposed study on self-harm. How open do you think they would be to talking to you about such a sensitive issue? Would they consent to talk to you at all?
Maybe you are thinking about simply asking clients on your caseload. As we talked about before, leveraging existing relationships created through field work can help with accessing your target population. However, they introduce other ethical issues for researchers. Asking clients on your caseload or at your agency to participate in your project creates a dual relationship between you and your client. What if you learn something in the research project that you want to share with your clinical team? More importantly, would your client feel uncomfortable if they do not consent to your study? Social workers have power over clients, and any dual relationship would require strict supervision in the rare case it was allowed.
Resources and scope
Let's assume everyone consented to your project and you have adequately addressed any ethical issues with gatekeepers, stakeholders, and your target population. That means everything is ready to go, right? Not quite yet. As a researcher, you will need to carry out the study you propose to do. Depending on how big or how small your proposed project is, you’ll need a little or a lot of resources. Here is a short list of the resources researchers need to in order to conduct their research projects:
- Time
- Money
- Knowledge, competence, skills, training
- Data (see next section)
Exercises
Think about how you might answer your question by collecting your own data.
- Identify any gatekeepers and stakeholders you might need to contact.
- Do you think it is likely you will get access to the people or records you need for your study?
Researchers analyze raw data
One thing that all projects need is raw data. It's extremely important to note that raw data is not just the information you read in journal articles and books. Every year, I get at least one student research proposal whose methodology is "reading articles." It's a very understandable mistake to make. Most school assignments are simply to read about a topic and write a paper. A research project involves doing that, and then using your inquiry to inform a quantitative or qualitative study.
Raw data can come in may forms. Very often in social science research, raw data includes the responses to a survey or transcripts of interviews and focus groups, but raw data can also include experimental results, diary entries, art, or other data points that social scientists use in analyzing the world.
As our feasibility examples above illustrate, it's not always possible for social work researchers to collect raw data of their own. And even when researchers do collect their own data, they are faced by the very real constrains of interacting with real people in the real world (traveling to locations, recording and transcribing interviews, etc.)
To get around some of these issues, researchers use secondary data analysis to analyze raw data that has been shared by other researchers . One common source of raw data in student projects from their internship or employer. By looking at client charts or data from previous grant reports or program evaluations, you can use raw data already collected by your agency to answer your research question. You can also use data that was not gathered by a scientist but is publicly available. For example, you might analyze blog entries, movies, YouTube videos, songs, or other pieces of media. Whether a researcher should use secondary data or collect their own raw data is an important choice which we will discuss in greater detail in section 2.4. Nevertheless, without raw data there can be no research project. Reading the literature about your topic is only the first step in a research project.

Using secondary data
Within the agency setting, there are two main sources of raw data. One option is to examine client charts. For example, if you wanted to know if substance use was related to parental reunification for youth in foster care, you could look at client files and compare how long it took for families with differing levels of substance use to be reunified. You will have to negotiate with the agency the degree to which your analysis can be public. Agencies may be okay with you using client files for a class project but less comfortable with you presenting your findings at a city council meeting. When analyzing data from your agency, you will have to manage a stakeholder relationship.
Another great example from my class this year was a student who used existing program evaluations at their agency as raw data in her student research project. If you are practicing at a grant funded agency, administrators and clinicians are likely producing data for grant reporting. Your agency may consent to have you look at the raw data and run your own analysis. Larger agencies may also conduct internal research—for example, surveying employees or clients about new initiatives. These, too, can be good sources of available data. Generally, if your agency has already collected the data, you can ask to use them. Again, it is important to be clear on the boundaries and expectations of your agency. And don't be angry if they say no!
Some agencies, usually government agencies, publish their data in formal reports. You could take a look at some of the websites for county or state agencies to see if there are any publicly available data relevant to your research topic. As an example, perhaps there are annual reports from the state department of education that show how seclusion and restraint is disproportionately applied to Black children with disabilities, as students found in Virginia. In my class last year, one student matched public data from our city's map of criminal incidents with historically redlined neighborhoods. For this project, she is using publicly available data from Mapping Inequality, which digitized historical records of redlined housing communities and the Roanoke, VA crime mapping webpage. By matching historical data on housing redlining with current crime records, she is testing whether redlining still impacts crime to this day.
Not all public data are easily accessible, though. The student in the previous example was lucky that scholars had digitized the records of how Virginia cities were redlined by race. Sources of historical data are often located in physical archives, rather than digital archives. If your project uses historical data in an archive, it would require you to physically go to the archive in order to review the data. Unless you have a travel budget, you may be limited to the archival data in your local libraries and government offices. Similarly, government data may have to be requested from an agency, which can take time. If the data are particularly sensitive or if the department would have to dedicate a lot of time to your request, you may have to file a Freedom of Information Act request. This process can be time-consuming, and in some cases, it will add financial cost to your study.
Another source of secondary data is shared by researchers as part of the publication and review process. There is a growing trend in research to publicly share data so others can verify your results and attempt to replicate your study. In more recent articles, you may notice links to data provided by the researcher. Often, these have been de-identified by eliminating some information that could lead to violations of confidentiality. You can browse through the data repositories in Table 2.1 to find raw data to analyze. Make sure that you pick a data set with thorough and easy to understand documentation. You may also want to use Google's dataset search which indexes some of the websites below as well as others in a very intuitive and easy to use way.
| Organizational home | Focus/topic | Data | Web address |
| National Opinion Research Center | General Social Survey; demographic, behavioral, attitudinal, and special interest questions; national sample | Quantitative | https://gss.norc.org/ |
| Carolina Population Center | Add Health; longitudinal social, economic, psychological, and physical well-being of cohort in grades 7–12 in 1994 | Quantitative | http://www.cpc.unc.edu/projects/addhealth |
| Center for Demography of Health and Aging | Wisconsin Longitudinal Study; life course study of cohorts who graduated from high school in 1957 | Quantitative | https://www.ssc.wisc.edu/wlsresearch/ |
| Institute for Social & Economic Research | British Household Panel Survey; longitudinal study of British lives and well- being | Quantitative | https://www.iser.essex.ac.uk/bhps |
| International Social Survey Programme | International data similar to GSS | Quantitative | http://www.issp.org/ |
| The Institute for Quantitative Social Science at Harvard University | Large archive of written data, audio, and video focused on many topics | Quantitative and qualitative | http://dvn.iq.harvard.edu/dvn/dv/mra |
| Institute for Research on Women and Gender | Global Feminisms Project; interview transcripts and oral histories on feminism and women’s activism | Qualitative | https://globalfeminisms.umich.edu/ |
| Oral History Office | Descriptions and links to numerous oral history archives | Qualitative | https://archives.lib.uconn.edu/islandora/ object/20002%3A19840025 |
| UNC Wilson Library | Digitized manuscript collection from the Southern Historical Collection | Qualitative | http://dc.lib.unc.edu/ead/archivalhome.php? CISOROOT=/ead |
| Qualitative Data Repository | A repository of qualitative data that can be downloaded and annotated collaboratively with other researchers | Qualitative | https://qdr.syr.edu/ |
Strengths and limitations of secondary data analysis
Imagine you wanted to study whether race or gender influenced what major people chose at your college. You could do your best to distribute a survey to a representative sample of students, but perhaps a better idea would be to ask your college registrar for this information. Your college already collects this information on all of its students. Wouldn’t it be better to simply ask for access to this information, rather than collecting it yourself? Maybe.
Challenges in secondary data analysis
Some of you may be thinking, “I never gave my college permission to share my information with other researchers.” Depending on the policies of your university, this may or may not be true. In any case, secondary data is usually anonymized or does not contain identifying information. In our example, students’ names, student ID numbers, home towns, and other identifying details would not be shared with a secondary researcher. Instead, just the information on the variables—race, gender, and major—would be shared. Anonymization techniques are not foolproof, and this is a challenge to secondary data analysis. Based on my limited sample of social work classrooms I have taught, there are usually only two or three men in the room. While privacy may not be a big deal for a study about choice of major, imagine if our example study included final grades, income, or whether your parents attended college. If I were a researcher using secondary data, I could probably figure out which data belonged to which men because there are so few men in the major. This is a problem in real-world research, as well. Anonymized data from credit card companies, Netflix, AOL, and online advertising companies have been “unmasked,” allowing researchers to identify nearly all individuals in a data set (Bode, K. 2017; de Montjoy, Radaelli, Singh, & Pentland, 2015) [1]

Another challenge with secondary data stems from the lack of control over the data collection process. Perhaps your university made a mistake on their forms or they entered data incorrectly. You certainly would not have made such a mistake if this were your data, but if you did make a mistake, you could correct it right away. Using secondary data, you are less able to correct for errors made by the original source during data collection. More importantly, you may not know these errors exist and reach erroneous conclusions as a result. Researchers using secondary data should evaluate data collection procedures wherever possible, and they should treat data that lacks procedural documentation with caution.
It is also important to attend to how the original researchers dealt with missing or incomplete data. Researchers may have simply used the mean score for a piece of missing data or excluded them from analysis entirely. The primary researchers made that choice for a reason, and secondary researchers should understand their decision-making process before proceeding with analysis. Finally, secondary researchers must have access to the codebook for quantitative data and coding scheme for qualitative data. A quantitative dataset often contains shorthand for question numbers, variables, and attributes. A qualitative data analysis contains as a coding scheme explaining definitions and relationships for all codes. Without these, the data would be difficult to comprehend for a secondary researcher.
Secondary researchers, particularly those conducting quantitative research, must also ensure that their conceptualization and operationalization of variables matches that of the primary researchers. If your secondary analysis focuses on a variable that was not a major part of the original analysis, you may not have enough information about that variable to conduct a thorough analysis. For example, let’s say you wanted to study whether depression is associated with income for students and you found a dataset that included those variables. If depression was not a focus of the dataset, researchers may only have included a question like, “Have you ever been diagnosed with major depressive disorder?” While answers to this question will give you some information about depression, it will not provide the same depth of a scale like Beck’s Depression Inventory or the Hamilton Rating Scale for Depression. It would also fail to provide information about severity of symptoms like hospitalization or suicide attempts. Without this level of depth, your analysis may lack validity. Even when the variables are thoroughly operationalized, researchers may conceptualize variables differently than you do. Perhaps they are interested in whether a person was diagnosed with depression in their life, but you are concerned with current symptoms of depression. For these reasons, reading research reports and other documentation is a requirement for secondary data analysis.
The lack of control over the data collection process also hamstrings the research process itself. While some studies are created perfectly, most are refined through pilot testing and feedback before the full study is conducted (Engel & Schutt, 2016). [2] Secondary data analysis does not allow you to engage in this process. For qualitative researchers in particular, this is an important challenge. Qualitative research, particularly from the interpretivist paradigm, uses emergent processes in which research questions, conceptualization of terms, and measures develop and change over the course of the study. Secondary data analysis inhibits this process because the data are already collected. Qualitative methods often involve analyzing the context in which data are collected, therefore secondary researchers may not know enough to represent the original data authentically and accurately in a new analysis.
Returning to our example on race, gender, and major, let’s assume you are reasonably certain the data do not contain errors and you are comfortable with having no control over the data collection process. Getting access to the data is not as simple as walking into the registrar’s office with a smile. Researchers seeking access to data collected by universities (or hospitals, health insurers, human service agencies, etc.) must have the support of the administration. In some cases, a researcher may only have to demonstrate that they are competent to complete the analysis, share their data analysis plan, and receive ethical approval from an IRB. Administrators of data that are often accessed by researchers, such as Medicaid or Census data, may fall into this category.
Your school administration may not be used to partnering with researchers to analyze their students. In fact, administrators may be quite sensitive to how their school is perceived as a result of your study. If your study found that women or Latinos are excluded from engineering and science degrees, that would reflect poorly on the university and the administration. It may be important for researchers to form a partnership with the agency or university whose data is included in the secondary data analysis. Administrators will trust people who they perceive as competent, reputable, and objective. They must trust you to engage in rigorous and conscientious research. A disreputable researcher may seek to raise their reputation by finding shocking results (real or fake) in your university’s data, while damaging the reputation of the university.
On the other hand, if your secondary data analysis paints the university in a glowing and rosy light, other researchers may be skeptical of your findings. This problem concerned Steven Levitt, an economist who worked with Uber to estimate how much consumers saved by using its service versus traditional taxis. Levitt knew that he would have to partner with Uber in order to gain access to their data but was careful to secure written permission to publish his results, regardless of whether his results were positive or negative for Uber (Huggins, 2016). [3] Researchers using secondary data must be careful to build trust with gatekeepers in administration while not compromising their objectivity through conflicts of interest.
Strengths of secondary data analysis
While the challenges associated with secondary data analysis are important, the strengths of this method often outweigh these limitations. Most importantly, secondary data analysis is quicker and cheaper than a traditional study because the data are already collected. Once a researcher gains access to the data, it is simply a matter of analyzing it and writing up the results to complete the project. Data can take a long time to gather and be quite resource-intensive. So, avoiding this step is a significant strength of secondary data analysis. If the primary researchers had access to more resources, they may also be able to engage in data collection that is more rigorous than a secondary researcher could. In this way, outsourcing the data collection to someone with more resources may make your design stronger, not weaker. Finally, secondary researchers ask new questions that the primary researchers may not have considered. In this way, secondary data analysis deepens our understanding of existing data in the field.

Secondary data analysis also provides researchers with access to data that would otherwise be unavailable or unknown to the public. A good example of this is historical research, in which researchers analyze data from primary sources of historical events and proceedings. Netting and O’Connor (2016) [4] were interested in understanding what impact religious organizations had on the development of human services in Richmond, Virginia. Using documents from the Valentine History Center, Virginia Historical Society, and other sources, the researchers were able to discover the origins of social welfare in the city—traveler’s assistance programs in the 1700s. In their study, they also uncovered the important role women played in social welfare agencies, a surprising finding given the historical disenfranchisement of women in American society. Secondary data analysis provides the researcher with the opportunity to answer questions like these without a time machine. Table 14.3 summarizes the strengths and limitations of existing data.
| Strengths | Limitations |
| Reduces the time needed to complete the project | Anonymous data may not be truly anonymous |
| Cheaper to conduct, in many cases | No control over data collection process |
| Primary researcher may have more resources to conduct a rigorous data collection than you | Cannot refine questions, measures, or procedure based on feedback or pilot tests |
| Helps us deepen our understanding of data already in the literature | May operationalize or conceptualize concepts differently than primary researcher |
| Useful for historical research | Missing qualitative context |
| Barriers to access and conflicts of interest |
Ultimately, you will have to weigh the strengths and limitations of using secondary data on your own. Engel and Schutt (2016, p. 327)[61] propose six questions to ask before using secondary data:
- What were the agency’s or researcher’s goals in collecting the data?
- What data were collected, and what were they intended to measure?
- When was the information collected?
- What methods were used for data collection? Who was responsible for data collection, and what were their qualifications? Are they available to answer questions about the data?
- How is the information organized (by date, individual, family, event, etc.)? Are identifiers used to indicate different types of data available?
- What is known about the success of the data collection effort? How are missing data indicated and treated? What kind of documentation is available? How consistent are the data with data available from other sources?
In this section, we've talked about data as though it is always collected by scientists and professionals. But that's definitely not the case! Think more broadly about sources of data that are already out there in the world. Perhaps you want to examine the different topics mentioned in the past 10 State of the Union addresses by the President. One of my students this past semester is examining whether the websites and public information about local health and mental health agencies use gender-inclusive language. People share their experiences through blogs, social media posts, videos, performances, among countless other sources of data. When you think broadly about data, you'll be surprised how much you can answer with available data.
Collecting your own raw data
The primary benefit of collecting your own data is that it allows you to collect and analyze the specific data you are looking for, rather than relying on what other people have shared. You can make sure the right questions are asked to the right people to answer your exact research question. Because we are seeking to establish generalizable truths, we try to make sampling decisions that increase our level of control over how the data is collected, and therefore, can be more confident that the results reflect objective truth.
Key Takeaways
- All research projects require analyzing raw data.
- Student projects often analyze available data from agencies, government, or public sources. Doing so allows students to avoid the process of recruiting people to participate in their study. This makes projects more feasible but limits what you can study to the data that are already available to you.
- Student projects should avoid potentially harmful or sensitive topics when surveying or interviewing clients and other vulnerable populations. Since many social work topics are sensitive, students often collect data from less-vulnerable populations such as practitioners and administrators.
Exercises
- Describe the difference between raw data and the results of research articles.
- Identify potential sources of secondary data that might help you answer your working question.
- Consider browsing around the data repositories in Table 2.1.
10.2 The sampling process
Learning Objectives
Learners will be able to...
- Decide where to get your data and who you might need to talk to
- Evaluate whether it is feasible for you to collect first-hand data from your target population
- Describe the process of sampling
- Apply population, sampling frame, and other sampling terminology to sampling people your project's target population
One of the things that surprised me most as a research methods professor is how much my students struggle with understanding sampling. It is surprising because people engage in sampling all the time. How do you learn whether you like a particular food, like BBQ ribs? You sample them from different restaurants! Obviously, social scientists put a bit more effort and thought into the process than that, but the underlying logic is the same. By sampling a small group of BBQ ribs from different restaurants and liking most of them, you can conclude that when you encounter BBQ ribs again, you will probably like them. You don't need to eat all of the BBQ ribs in the world to come to that conclusion, just a small sample.[62] Part of the difficulty my students face is learning sampling terminology, which is the focus of this section.

Who is your study about and who should you talk to?
At this point in the research process, you know what your research question is. Our goal in this chapter is to help you understand how to find the people (or documents) you need to study in order to find the answer to your research question. It may be helpful at this point to distinguish between two concepts. Your unit of analysis is the entity that you wish to be able to say something about at the end of your study (probably what you’d consider to be the main focus of your study). Your unit of observation is the entity (or entities) that you actually observe, measure, or collect in the course of trying to learn something about your unit of analysis.
It is often the case that your unit of analysis and unit of observation are the same. For example, we may want to say something about social work students (unit of analysis), so we ask social work students at our university to complete a survey for our study (unit of observation). In this case, we are observing individuals, i.e. students, so we can make conclusions about individuals.
On the other hand, our unit of analysis and observation can differ. We could sample social work students to draw conclusions about organizations or universities. Perhaps we are comparing students at historically Black colleges and universities (HBCUs) and primarily white institutions (PWIs). Even though our sample was made up of individual students from various colleges (our unit of observation), our unit of analysis was the university as an organization. Conclusions we made from individual-level data were used to understand larger organizations.
Similarly, we could adjust our sampling approach to target specific student cohorts. Perhaps we wanted to understand the experiences of Black social work students in PWIs. We could choose either an individual unit of observation by selecting students, or a group unit of observation by studying the National Association of Black Social Workers.
Sometimes the units of analysis and observation differ due to pragmatic reasons. If we wanted to study whether being a social work student impacted family relationships, we may choose to study family members of students in social work programs who could give us information about how they behaved in the home. In this case, we would be observing family members to draw conclusions about individual students.
In sum, there are many potential units of analysis that a social worker might examine, but some of the most common include individuals, groups, and organizations. Table 10.1 details examples identifying the units of observation and analysis in a hypothetical study of student addiction to electronic gadgets.
| Research question | Unit of analysis | Data collection | Unit of observation | Statement of findings |
| Which students are most likely to be addicted to their electronic gadgets? | Individuals | Survey of students on campus | Individuals | New Media majors, men, and students with high socioeconomic status are all more likely than other students to become addicted to their electronic gadgets. |
| Do certain types of social clubs have more gadget-addicted members than other sorts of clubs? | Groups | Survey of students on campus | Individuals | Clubs with a scholarly focus, such as social work club and the math club, have more gadget-addicted members than clubs with a social focus, such as the 100-bottles-of- beer-on-the-wall club and the knitting club. |
| How do different colleges address the problem of electronic gadget addiction? | Organizations | Content analysis of policies | Documents | Campuses without strong computer science programs are more likely than those with such programs to expel students who have been found to have addictions to their electronic gadgets. |
| Note: Please remember that the findings described here are hypothetical. There is no reason to think that any of the hypothetical findings described here would actually bear out if empirically tested. | ||||
First-hand vs. second-hand knowledge
Your unit of analysis will be determined by your research question. Specifically, it should relate to your target population. Your unit of observation, on the other hand, is determined largely by the method of data collection you use to answer that research question. Let's consider a common issue in social work research: understanding the effectiveness of different social work interventions. Who has first-hand knowledge and who has second-hand knowledge? Well, practitioners would have first-hand knowledge about implementing the intervention. For example, they might discuss with you the unique language they use help clients understand the intervention. Clients, on the other hand, have first-hand knowledge about the impact of those interventions on their lives. If you want to know if an intervention is effective, you need to ask people who have received it!
Unfortunately, student projects run into pragmatic limitations with sampling from client groups. Clients are often diagnosed with severe mental health issues or have other ongoing issues that render them a vulnerable population at greater risk of harm. Asking a person who was recently experiencing suicidal ideation about that experience may interfere with ongoing treatment. Client records are also confidential and cannot be shared with researchers unless clients give explicit permission. Asking one's own clients to participate in the study creates a dual relationship with the client, as both clinician and researcher, and dual relationship have conflicting responsibilities and boundaries.
Obviously, studies are done with social work clients all the time. But for student projects in the classroom, it is often required to get second-hand information from a population that is less vulnerable. Students may instead choose to study clinicians and how they perceive the effectiveness of different interventions. While clinicians can provide an informed perspective, they have less knowledge about personally receiving the intervention. In general, researchers prefer to sample the people who have first-hand knowledge about their topic, though feasibility often forces them to analyze second-hand information instead.
Population: Who do you want to study?
In social scientific research, a population is the cluster of people you are most interested in. It is often the “who” that you want to be able to say something about at the end of your study. While populations in research may be rather large, such as “the American people,” they are more typically more specific than that. For example, a large study for which the population of interest is the American people will likely specify which American people, such as adults over the age of 18 or citizens or legal permanent residents. Based on your work in Chapter 2, you should have a target population identified in your working question. That might be something like "people with developmental disabilities" or "students in a social work program."
It is almost impossible for a researcher to gather data from their entire population of interest. This might sound surprising or disappointing until you think about the kinds of research questions that social workers typically ask. For example, let’s say we wish to answer the following question: “How does gender impact attendance in a batterer intervention program?” Would you expect to be able to collect data from all people in batterer intervention programs across all nations from all historical time periods? Unless you plan to make answering this research question your entire life’s work (and then some), I’m guessing your answer is a resounding no. So, what to do? Does not having the time or resources to gather data from every single person of interest mean having to give up your research interest?
Exercises
Let's think about who could possibly be in your study.
- What is your population, the people you want to make conclusions about?
- Do your unit of analysis and unit of observation differ or are they the same?
- Can you ethically and practically get first-hand information from the people most knowledgeable about the topic, or will you rely on second-hand information from less vulnerable populations?
Setting: Where will you go to get your data?
While you can't gather data from everyone, you can find some people from your target population to study. The first rule of sampling is: go where your participants are. You will need to figure out where you will go to get your data. For many student researchers, it is their agency, their peers, their family and friends, or whoever comes across students' social media posts or emails asking people to participate in their study.
Each setting (agency, social media) limits your reach to only a small segment of your target population who has the opportunity to be a part of your study. This intermediate point between the overall population and the sample of people who actually participate in the researcher's study is called a sampling frame. A sampling frame is a list of people from which you will draw your sample.
But where do you find a sampling frame? Answering this question is the first step in conducting human subjects research. Social work researchers must think about locations or groups in which your target population gathers or interacts. For example, a study on quality of care in nursing homes may choose a local nursing home because it’s easy to access. The sampling frame could be all of the residents of the nursing home. You would select your participants for your study from the list of residents. Note that this is a real list. That is, an administrator at the nursing home would give you a list with every resident’s name or ID number from which you would select your participants. If you decided to include more nursing homes in your study, then your sampling frame could be all the residents at all the nursing homes who agreed to participate in your study.
Let’s consider some more examples. Unlike nursing home patients, cancer survivors do not live in an enclosed location and may no longer receive treatment at a hospital or clinic. For social work researchers to reach participants, they may consider partnering with a support group that services this population. Perhaps there is a support group at a local church survivors may attend. Without a set list of people, your sampling frame would simply be the people who showed up to the support group on the nights you were there. Similarly, if you posted an advertisement in an online peer-support group for people with cancer, your sampling frame is the people in that group.
More challenging still is recruiting people who are homeless, those with very low income, or those who belong to stigmatized groups. For example, a research study by Johnson and Johnson (2014)[63] attempted to learn usage patterns of “bath salts,” or synthetic stimulants that are marketed as “legal highs.” Users of “bath salts” don’t often gather for meetings, and reaching out to individual treatment centers is unlikely to produce enough participants for a study, as the use of bath salts is rare. To reach participants, these researchers ingeniously used online discussion boards in which users of these drugs communicate. Their sampling frame included everyone who participated in the online discussion boards during the time they collected data. Another example might include using a flyer to let people know about your study, in which case your sampling frame would be anyone who walks past your flyer wherever you hang it—usually in a strategic location where you know your population will be.
In conclusion, sampling frames can be a real list of people like the list of faculty and their ID numbers in a university department, which allows you to clearly identify who is in your study and what chance they have of being selected. However, not all sampling frames allow you to be so specific. It is also important to remember that accessing your sampling frame must be practical and ethical, as we discussed in Chapter 2 and Chapter 6. For studies that present risks to participants, approval from gatekeepers and the university's institutional review board (IRB) is needed.
Criteria: What characteristics must your participants have/not have?
Your sampling frame is not just everyone in the setting you identified. For example, if you were studying MSW students who are first-generation college students, you might select your university as the setting, but not everyone in your program is a first-generation student. You need to be more specific about which characteristics or attributes individuals either must have or cannot have before they participate in the study. These are known as inclusion and exclusion criteria, respectively.
Inclusion criteria are the characteristics a person must possess in order to be included in your sample. If you were conducting a survey on LGBTQ+ discrimination at your agency, you might want to sample only clients who identify as LGBTQ+. In that case, your inclusion criteria for your sample would be that individuals have to identify as LGBTQ+.
Comparably, exclusion criteria are characteristics that disqualify a person from being included in your sample. In the previous example, you could think of cisgenderism and heterosexuality as your exclusion criteria because no person who identifies as heterosexual or cisgender would be included in your sample. Exclusion criteria are often the mirror image of inclusion criteria. However, there may be other criteria by which we want to exclude people from our sample. For example, we may exclude clients who were recently discharged or those who have just begun to receive services.

Recruitment: How will you ask people to participate in your study?
Once you have a location and list of people from which to select, all that is left is to reach out to your participants. Recruitment refers to the process by which the researcher informs potential participants about the study and asks them to participate in the research project. Recruitment comes in many different forms. If you have ever received a phone call asking for you to participate in a survey, someone has attempted to recruit you for their study. Perhaps you’ve seen print advertisements on buses, in student centers, or in a newspaper. I’ve received many emails that were passed around my school asking for participants, usually for a graduate student project. As we learn more about specific types of sampling, make sure your recruitment strategy makes sense with your sampling approach. For example, if you put up a flyer in the student health office to recruit student athletes for your study, you may not be targeting your recruitment efforts to settings where your target population is likely to see your recruitment materials.
Recruiting human participants
Sampling is the first time in which you will contact potential study participants. Before you start this process, it is important to make sure you have approval from your university's institutional review board as well as any gatekeepers at the locations in which you plan to conduct your study. As we discussed in section 10.1, the first rule of sampling is to go where your participants are. If you are studying domestic violence, reach out to local shelters, advocates, or service agencies. Gatekeepers will be necessary to gain access to your participants. For example, a gatekeeper can forward your recruitment email across their employee email list. Review our discussion of gatekeepers in Chapter 2 before proceeding with contacting potential participants as part of recruitment.
Recruitment can take many forms. You may show up at a staff meeting to ask for volunteers. You may send a company-wide email. Each step of this process should be vetted by the IRB as well as other stakeholders and gatekeepers. You will also need to set reasonable expectations for how many reminders you will send to the person before moving on. Generally, it is a good idea to give people a little while to respond, though reminders are often accompanied by an increase in participation. Pragmatically, it is a good idea for you to think through each step of the recruitment process and how much time it will take to complete it.
For example, as a graduate student, I conducted a study of state-level disabilities administrators in which I was recruiting a sample of very busy people and had no financial incentives to offer them for participating in my study. It helped for my research team to bring on board a well-known agency as a research partner, allowing them to review and offer suggestions on our survey and interview questions. This collaborative process took time and had to be completed before sampling could start. Once sampling commenced, I pulled contact names from my collaborator's database and public websites, and set a weekly schedule of email and phone contacts. I would contact the director once via email. Ten days later, I would follow up via email and by leaving a voicemail with their administrative support staff. Ten days after that, I would reach out to state administrators in a different office via email and then again via phone, if needed. The process took months to complete and required a complex Excel tracking document.
Recruitment will also expose your participants to the informed consent information you prepared. For students going through the IRB, there are templates you will have to follow in order to get your study approved. For students whose projects unfold under the supervision of their department, rather than the IRB, you should check with your professor on what the expectations are for getting participant consent. In the aforementioned study, I used our IRB's template to create a consent form but did not include a signature line. The IRB allowed me to collect my data without a signature, as there was little risk of harm from the study. It was imperative to review consent information before completing the survey and interview with participants. Only when the participant is totally clear on the purpose, risks and benefits, confidentiality protections, and other information detailed in Chapter 6, can you ethically move forward with including them in your sample.
Sampling available documents
As with sampling humans, sampling documents centers around the question: which documents are the most relevant to your research question, in that which will provide you first-hand knowledge. Common documents analyzed in student research projects include client files, popular media like film and music lyrics, and policies from service agencies. In a case record review, the student would create exclusion and inclusion criteria based on their research question. Once a suitable sampling frame of potential documents exists, the researcher can use probability or non-probability sampling to select which client files are ultimately analyzed.
Sampling documents must also come with consent and buy-in from stakeholders and gatekeepers. Assuming you have approval to conduct your study and access to the documents you need, the process of recruitment is much easier than in studies sampling humans. There is no informed consent process with documents, though research with confidential health or education records must be done in accordance with privacy laws such as the Health Insurance Portability and Accountability Act and the Family Educational Rights and Privacy Act. Barring any technical or policy obstacles, the gathering of documents should be easier and less time consuming than sampling humans.
Sample: Who actually participates in your study?
Once you find a sampling frame from which you can recruit your participants and decide which characteristics you will include and exclude, you will recruit people using a specific sampling approach, which we will cover in Section 10.2. At the end, you're left with the group of people you successfully recruited from your sampling frame to participate in your study, your sample. If you are a participant in a research project—answering survey questions, participating in interviews, etc.—you are part of the sample in that research project.
Visualizing sampling terms
Sampling terms can be a bit daunting at first. However, with some practice, they will become second nature. Let’s walk through an example from a research project of mine. I collected data for a research project related to how much it costs to become a licensed clinical social worker (LCSW) in each state. Becoming an LCSW is necessary to work in private clinical practice and is used by supervisors in human service organizations to sign off on clinical charts from less credentialed employees, and to provide clinical supervision. If you are interested in providing clinical services as a social worker, you should become familiar with the licensing laws in your state.
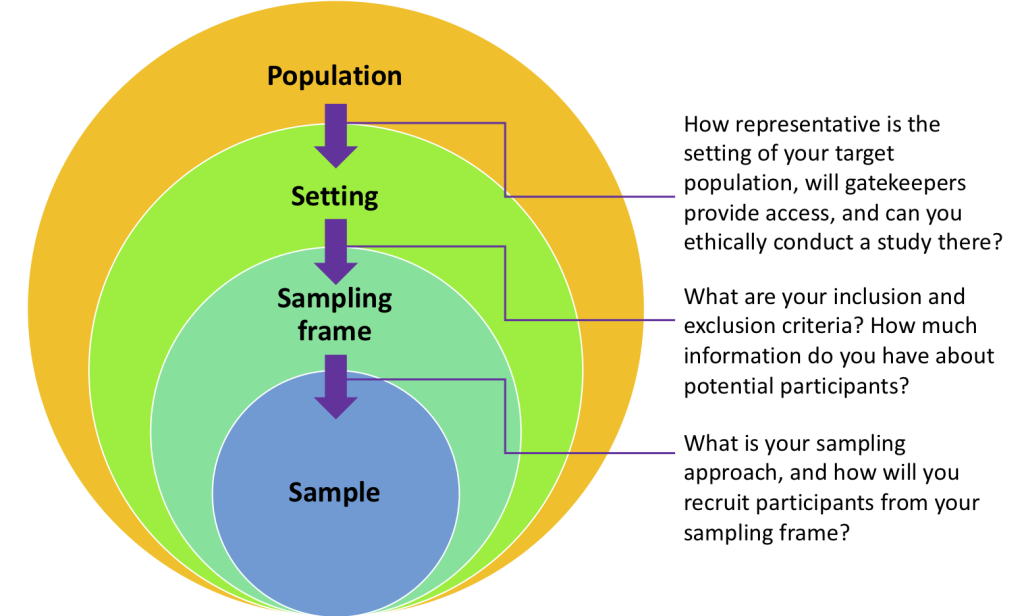
Using Figure 10.1 as a guide, my population is clearly clinical social workers, as these are the people about whom I want to draw conclusions. The next step inward would be a sampling frame. Unfortunately, there is no list of every licensed clinical social worker in the United States. I could write to each state’s social work licensing board and ask for a list of names and addresses, perhaps even using a Freedom of Information Act request if they were unwilling to share the information. That option sounds time-consuming and has a low likelihood of success. Instead, I tried to figure out a convenient setting social workers are likely to congregate. I considered setting up a booth at a National Association of Social Workers (NASW) conference and asking people to participate in my survey. Ultimately, this would prove too costly, and the people who gather at an NASW conference may not be representative of the general population of clinical social workers. I finally discovered the NASW membership email list, which is available to advertisers, including researchers advertising for research projects. While the NASW list does not contain every clinical social worker, it reaches over one hundred thousand social workers regularly through its monthly e-newsletter, a large proportion of social workers in practice, so the setting was likely to draw a representative sample. To gain access to this setting from gatekeepers, I had to provide paperwork showing my study had undergone IRB review and submit my measures for approval by the mailing list administrator.
Once I gained access from gatekeepers, my setting became the members of the NASW membership list. I decided to recruit 5,000 participants because I knew that people sometimes do not read or respond to email advertisements, and I figured maybe 20% would respond, which would give me around 1,000 responses. Figuring out my sample size was a challenge, because I had to balance the costs associated with using the NASW newsletter. As you can see on their pricing page, it would cost money to learn personal information about my potential participants, which I would need to check later in order to determine if my population was representative of the overall population of social workers. For example, I could see if my sample was comparable in race, age, gender, or state of residence to the broader population of social workers by comparing my sample with information about all social workers published by NASW. I presented my options to my external funder as:
- I could send an email advertisement to a lot of people (5,000), but I would know very little about them and they would get only one advertisement.
- I could send multiple advertisements to fewer people (1,000) reminding them to participate, but I would also know more about them by purchasing access to personal information.
- I could send multiple advertisements to fewer people (2,500), but not purchase access to personal information to minimize costs.
In your project, there is no expectation you purchase access to anything, and if you plan on using email advertisements, consider places that are free to access like employee or student listservs. At the same time, you will need to consider what you can know or not know about the people who will potentially be in your study, and I could collect any personal information we wanted to check representativeness in the study itself. For this reason, we decided to go with option #1. When I sent my email recruiting participants for the study, I specified that I only wanted to hear from social workers who were either currently receiving or recently received clinical supervision for licensure—my inclusion criteria. This was important because many of the people on the NASW membership list may not be licensed or license-seeking social workers. So, my sampling frame was the email addresses on the NASW mailing list who fit the inclusion criteria for the study, which I figured would be at least a few thousand people. Unfortunately, only 150 licensed or license-seeking clinical social workers responded to my recruitment email and completed the survey. You will learn in Section 10.3 why this did not make for a very good sample.
From this example, you can see that sampling is a process. The process flows sequentially from figuring out your target population, to thinking about where to find people from your target population, to figuring out how much information you know about potential participants, and finally to selecting recruiting people from that list to be a part of your sample. Through the sampling process, you must consider where people in your target population are likely to be and how best to get their attention for your study. Sampling can be an easy process, like calling every 100th name from the phone book, or challenging, like standing every day for a few weeks in an area in which people who are homeless gather for shelter. In either case, your goal is to recruit enough people who will participate in your study so you can learn about your population.
What about sampling non-humans?
Many student projects do not involve recruiting and sampling human subjects. Instead, many research projects will sample objects like client charts, movies, or books. The same terms apply, but the process is a bit easier because there are no humans involved. If a research project involves analyzing client files, it is unlikely you will look at every client file that your agency has. You will need to figure out which client files are important to your research question. Perhaps you want to sample clients who have a diagnosis of reactive attachment disorder. You would have to create a list of all clients at your agency (setting) who have reactive attachment disorder (your inclusion criteria) then use your sampling approach (which we will discuss in the next section) to select which client files you will actually analyze for your study (your sample). Recruitment is a lot easier because, well, there's no one to convince but your gatekeepers, the managers of your agency. However, researchers who publish chart reviews must obtain IRB permission before doing so.
Key Takeaways
- The first rule of sampling is to go where your participants are. Think about virtual or in-person settings in which your target population gathers. Remember that you may have to engage gatekeepers and stakeholders in accessing many settings, and that you will need to assess the pragmatic challenges and ethical risks and benefits of your study.
- Consider whether you can sample documents like agency files to answer your research question. Documents are much easier to "recruit" than people!
- Researchers must consider which characteristics are necessary for people to have (inclusion criteria) or not have (exclusion criteria), as well as how to recruit participants into the sample.
- Social workers can sample individuals, groups, or organizations.
- Sometimes the unit of analysis and the unit of observation in the study differ. In student projects, this is often true as target populations may be too vulnerable to expose to research whose potential harms may outweigh the benefits.
- One's recruitment method has to match one's sampling approach, as will be explained in the next chapter.
Exercises
Once you have identified who may be a part of your study, the next step is to think about where those people gather. Are there in-person locations in your community or on the internet that are easily accessible. List at least one potential setting for your project. Describe for each potential setting:
- Based on what you know right now, how representative of your population are potential participants in the setting?
- How much information can you reasonably know about potential participants before you recruit them?
- Are there gatekeepers and what kinds of concerns might they have?
- Are there any stakeholders that may be beneficial to bring on board as part of your research team for the project?
- What interests might stakeholders and gatekeepers bring to the project and would they align with your vision for the project?
- What ethical issues might you encounter if you sampled people in this setting.
Even though you may not be 100% sure about your setting yet, let's think about the next steps.
- For the settings you've identified, how might you recruit participants?
- Identify your inclusion criteria and exclusion criteria, and assess whether you have enough information on whether people in each setting will meet them.
10.2 Sampling approaches for quantitative research
Learning Objectives
Learners will be able to...
- Determine whether you will use probability or non-probability sampling, given the strengths and limitations of each specific sampling approach
- Distinguish between approaches to probability sampling and detail the reasons to use each approach
Sampling in quantitative research projects is done because it is not feasible to study the whole population, and researchers hope to take what we learn about a small group of people (your sample) and apply it to a larger population. There are many ways to approach this process, and they can be grouped into two categories—probability sampling and non-probability sampling. Sampling approaches are inextricably linked with recruitment, and researchers should ensure that their proposal's recruitment strategy matches the sampling approach.
Probability sampling approaches use a random process, usually a computer program, to select participants from the sampling frame so that everyone has an equal chance of being included. It's important to note that random means the researcher used a process that is truly random. In a project sampling college students, standing outside of the building in which your social work department is housed and surveying everyone who walks past is not random. Because of the location, you are likely to recruit a disproportionately large number of social work students and fewer from other disciplines. Depending on the time of day, you may recruit more traditional undergraduate students, who take classes during the day, or more graduate students, who take classes in the evenings.
In this example, you are actually using non-probability sampling. Another way to say this is that you are using the most common sampling approach for student projects, availability sampling. Also called convenience sampling, this approach simply recruits people who are convenient or easily available to the researcher. If you have ever been asked by a friend to participate in their research study for their class or seen an advertisement for a study on a bulletin board or social media, you were being recruited using an availability sampling approach.
There are a number of benefits to the availability sampling approach. First and foremost, it is less costly and time-consuming for the researcher. As long as the person you are attempting to recruit has knowledge of the topic you are studying, the information you get from the sample you recruit will be relevant to your topic (although your sample may not necessarily be representative of a larger population). Availability samples can also be helpful when random sampling isn't practical. If you are planning to survey students in an LGBTQ+ support group on campus but attendance varies from meeting to meeting, you may show up at a meeting and ask anyone present to participate in your study. A support group with varied membership makes it impossible to have a real list—or sampling frame—from which to randomly select individuals. Availability sampling would help you reach that population.
Availability sampling is appropriate for student and smaller-scale projects, but it comes with significant limitations. The purpose of sampling in quantitative research is to generalize from a small sample to a larger population. Because availability sampling does not use a random process to select participants, the researcher cannot be sure their sample is representative of the population they hope to generalize to. Instead, the recruitment processes may have been structured by other factors that may bias the sample to be different in some way than the overall population.
So, for instance, if we asked social work students about their level of satisfaction with the services at the student health center, and we sampled in the evenings, we would get most likely get a biased perspective of the issue. Students taking only night classes are much more likely to commute to school, spend less time on campus, and use fewer campus services. Our results would not represent what all social work students feel about the topic. We might get the impression that no social work student had ever visited the health center, when that is not actually true at all. Sampling bias will be discussed in detail in Section 10.3.

Approaches to probability sampling
What might be a better strategy is getting a list of all email addresses of social work students and randomly selecting email addresses of students to whom you can send your survey. This would be an example of simple random sampling. It's important to note that you need a real list of people in your sampling frame from which to select your email addresses. For projects where the people who could potentially participate is not known by the researcher, probability sampling is not possible. It is likely that administrators at your school's registrar would be reluctant to share the list of students' names and email addresses. Always remember to consider the feasibility and ethical implications of the sampling approach you choose.
Usually, simple random sampling is accomplished by assigning each person, or element, in your sampling frame a number and selecting your participants using a random number generator. You would follow an identical process if you were sampling records or documents as your elements, rather than people. True randomness is difficult to achieve, and it takes complex computational calculations to do so. Although you think you can select things at random, human-generated randomness is actually quite predictable, as it falls into patterns called heuristics. To truly randomly select elements, researchers must rely on computer-generated help. Many free websites have good pseudo-random number generators. A good example is the website Random.org, which contains a random number generator that can also randomize lists of participants. Sometimes, researchers use a table of numbers that have been generated randomly. There are several possible sources for obtaining a random number table. Some statistics and research methods textbooks provide such tables in an appendix.
Though simple, this approach to sampling can be tedious since the researcher must assign a number to each person in a sampling frame. Systematic sampling techniques are somewhat less tedious but offer the benefits of a random sample. As with simple random samples, you must possess a list of everyone in your sampling frame. Once you’ve done that, to draw a systematic sample you’d simply select every kth element on your list. But what is k, and where on the list of population elements does one begin the selection process?
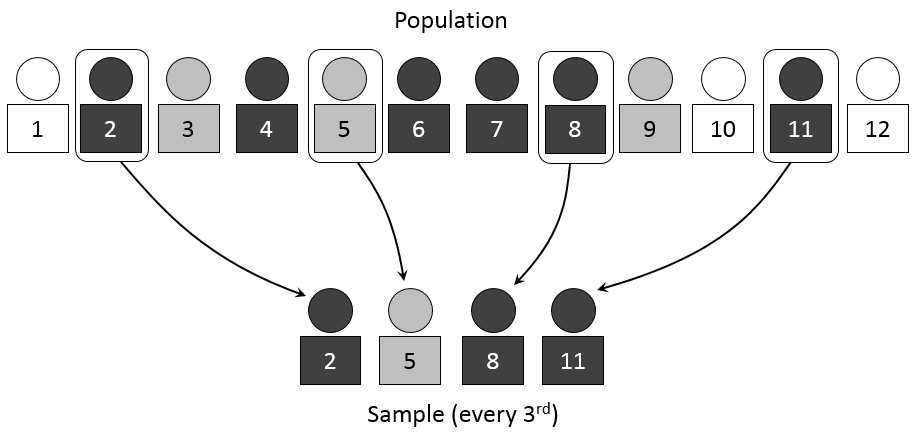
k is your selection interval or the distance between the elements you select for inclusion in your study. To begin the selection process, you’ll need to figure out how many elements you wish to include in your sample. Let’s say you want to survey 25 social work students and there are 100 social work students on your campus. In this case, your selection interval, or k, is 4. To get your selection interval, simply divide the total number of population elements by your desired sample size. Systematic sampling starts by randomly selecting a number between 1 and k to start from, and then recruiting every kth person. In our example, we may start at number 3 and then select the 7th, 11th, 15th (and so forth) person on our list of email addresses. In Figure 10.2, you can see the researcher starts at number 2 and then selects every third person for inclusion in the sample.
There is one clear instance in which systematic sampling should not be employed. If your sampling frame has any pattern to it, you could inadvertently introduce bias into your sample by using a systemic sampling strategy. (Bias will be discussed in more depth in section 10.3.) This is sometimes referred to as the problem of periodicity. Periodicity refers to the tendency for a pattern to occur at regular intervals.
To stray a bit from our example, imagine we were sampling client charts based on the date they entered a health center and recording the reason for their visit. We may expect more admissions for issues related to alcohol consumption on the weekend than we would during the week. The periodicity of alcohol intoxication may bias our sample towards either overrepresenting or underrepresenting this issue, depending on our sampling interval and whether we collected data on a weekday or weekend.
Advanced probability sampling techniques
Returning again to our idea of sampling student email addresses, one of the challenges in our study will be the different types of students. If we are interested in all social work students, it may be helpful to divide our sampling frame, or list of students, into three lists—one for traditional, full-time undergraduate students, another for part-time undergraduate students, and one more for full-time graduate students—and then randomly select from these lists. This is particularly important if we wanted to make sure our sample had the same proportion of each type of student compared with the general population.
This approach is called stratified random sampling. In stratified random sampling, a researcher will divide the study population into relevant subgroups or strata and then draw a sample from each subgroup, or stratum. Strata is the plural of stratum, so it refers to all of the groups while stratum refers to each group. This can be used to make sure your sample has the same proportion of people from each stratum. If, for example, our sample had many more graduate students than undergraduate students, we may draw incorrect conclusions that do not represent what all social work students experience.
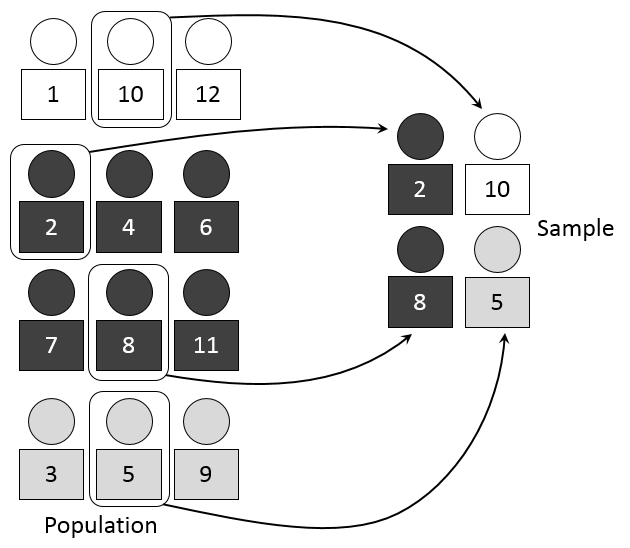
Generally, the goal of stratified random sampling is to recruit a sample that makes sure all elements of the population are included sufficiently that conclusions can be drawn about them. Usually, the purpose is to create a sample that is identical to the overall population along whatever strata you've identified. In our sample, it would be graduate and undergraduate students. Stratified random sampling is also useful when a subgroup of interest makes up a relatively small proportion of the overall sample. For example, if your social work program contained relatively few Asian students but you wanted to make sure you recruited enough Asian students to conduct statistical analysis, you could use race to divide people into subgroups or strata and then disproportionately sample from the Asian students to make sure enough of them were in your sample to draw meaningful conclusions. Statistical tests may have a minimum number
Up to this point in our discussion of probability samples, we’ve assumed that researchers will be able to access a list of population elements in order to create a sampling frame. This, as you might imagine, is not always the case. Let’s say, for example, that you wish to conduct a study of health center usage across students at each social work program in your state. Just imagine trying to create a list of every single social work student in the state. Even if you could find a way to generate such a list, attempting to do so might not be the most practical use of your time or resources. When this is the case, researchers turn to cluster sampling. Cluster sampling occurs when a researcher begins by sampling groups (or clusters) of population elements and then selects elements from within those groups.
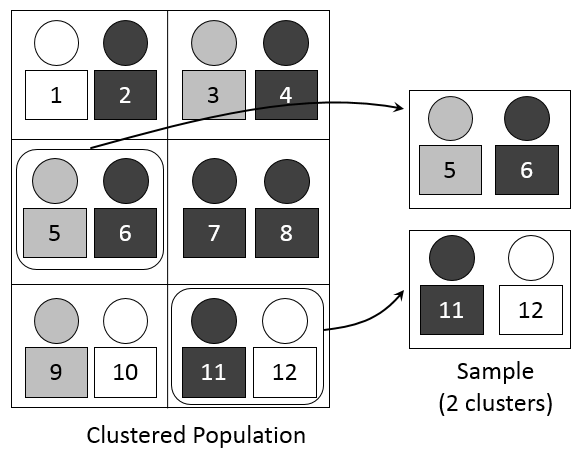
Let’s work through how we might use cluster sampling. While creating a list of all social work students in your state would be next to impossible, you could easily create a list of all social work programs in your state. Then, you could draw a random sample of social work programs (your cluster) and then draw another random sample of elements (in this case, social work students) from each of the programs you randomly selected from the list of all programs.
Cluster sampling often works in stages. In this example, we sampled in two stages—(1) social work programs and (2) social work students at each program we selected. However, we could add another stage if it made sense to do so. We could randomly select (1) states in the United States (2) social work programs in that state and (3) individual social work students. As you might have guessed, sampling in multiple stages does introduce a greater possibility of error. Each stage is subject to its own sampling problems. But, cluster sampling is nevertheless a highly efficient method.
Jessica Holt and Wayne Gillespie (2008)[64] used cluster sampling in their study of students’ experiences with violence in intimate relationships. Specifically, the researchers randomly selected 14 classes on their campus and then drew a random sub-sample of students from those classes. But you probably know from your experience with college classes that not all classes are the same size. So, if Holt and Gillespie had simply randomly selected 14 classes and then selected the same number of students from each class to complete their survey, then students in the smaller of those classes would have had a greater chance of being selected for the study than students in the larger classes. Keep in mind, with random sampling the goal is to make sure that each element has the same chance of being selected. When clusters are of different sizes, as in the example of sampling college classes, researchers often use a method called probability proportionate to size (PPS). This means that they take into account that their clusters are of different sizes. They do this by giving clusters different chances of being selected based on their size so that each element within those clusters winds up having an equal chance of being selected.
To summarize, probability samples allow a researcher to make conclusions about larger groups. Probability samples require a sampling frame from which elements, usually human beings, can be selected at random from a list. The use of random selection reduces the error and bias present in non-probability samples, which we will discuss in greater detail in section 10.3, though some error will always remain. In relying on a random number table or generator, researchers can more accurately state that their sample represents the population from which it was drawn. This strength is common to all probability sampling approaches summarized in Table 10.2.
| Sample type | Description |
| Simple random | Researcher randomly selects elements from sampling frame. |
| Systematic | Researcher selects every kth element from sampling frame. |
| Stratified | Researcher creates subgroups then randomly selects elements from each subgroup. |
| Cluster | Researcher randomly selects clusters then randomly selects elements from selected clusters. |
In determining which probability sampling approach makes the most sense for your project, it helps to know more about your population. A simple random sample and systematic sample are relatively similar to carry out. They both require a list all elements in your sampling frame. Systematic sampling is slightly easier in that it does not require you to use a random number generator, instead using a sampling interval that is easy to calculate by hand.
However, the relative simplicity of both approaches is counterweighted by their lack of sensitivity to characteristics of your population. Stratified samples can better account for periodicity by creating strata that reduce or eliminate its effects. Stratified sampling also ensure that smaller subgroups are included in your sample, thereby making your sample more representative of the overall population. While these benefits are important, creating strata for this purpose requires having information about your population before beginning the sampling process. In our social work student example, we would need to know which students are full-time or part-time, graduate or undergraduate, in order to make sure our sample contained the same proportions. Would you know if someone was a graduate student or part-time student, just based on their email address? If the true population parameters are unknown, stratified sampling becomes significantly more challenging.
Common to each of the previous probability sampling approaches is the necessity of using a real list of all elements in your sampling frame. Cluster sampling is different. It allows a researcher to perform probability sampling in cases for which a list of elements is not available or feasible to create. Cluster sampling is also useful for making claims about a larger population (in our previous example, all social work students within a state). However, because sampling occurs at multiple stages in the process, (in our previous example, at the university and student level), sampling error increases. For many researchers, the benefits of cluster sampling outweigh this weaknesses.
Matching recruitment and sampling approach
Recruitment must match the sampling approach you choose in section 10.2. For many students, that will mean using recruitment techniques most relevant to availability sampling. These may include public postings such as flyers, mass emails, or social media posts. However, these methods would not make sense for a study using probability sampling. Probability sampling requires a list of names or other identifying information so you can use a random process to generate a list of people to recruit into your sample. Posting a flyer or social media message means you don't know who is looking at the flyer, and thus, your sample could not be randomly drawn. Probability sampling often requires knowing how to contact specific participants. For example, you may do as I did, and contact potential participants via phone and email. Even then, it's important to note that not everyone you contact will enter your study. We will discuss more about evaluating the quality of your sample in section 10.3.
Key Takeaways
- Probability sampling approaches are more accurate when the researcher wants to generalize from a smaller sample to a larger population. However, non-probability sampling approaches are often more feasible. You will have to weigh advantages and disadvantages of each when designing your project.
- There are many kinds of probability sampling approaches, though each require you know some information about people who potentially would participate in your study.
- Probability sampling also requires that you assign people within the sampling frame a number and select using a truly random process.
Exercises
Building on the step-by-step sampling plan from the exercises in section 10.1:
- Identify one of the sampling approaches listed in this chapter that might be appropriate to answering your question and list the strengths and limitations of it.
- Describe how you will recruit your participants and how your plan makes sense with the sampling approach you identified.
Examine one of the empirical articles from your literature review.
- Identify what sampling approach they used and how they carried it out from start to finish.
10.3 Sample quality
Learning Objectives
Learners will be able to...
- Assess whether your sampling plan is likely to produce a sample that is representative of the population you want to draw conclusions about
- Identify the considerations that go into producing a representative sample and determining sample size
- Distinguish between error and bias in a sample and explain the factors that lead to each
Okay, so you've chosen where you're going to get your data (setting), what characteristics you want and don't want in your sample (inclusion/exclusion criteria), and how you will select and recruit participants (sampling approach and recruitment). That means you are done, right? (I mean, there's an entire section here, so probably not.) Even if you make good choices and do everything the way you're supposed to, you can still draw a poor sample. If you are investigating a research question using quantitative methods, the best choice is some kind of probability sampling, but aside from that, how do you know a good sample from a bad sample? As an example, we'll use a bad sample I collected as part of a research project that didn't go so well. Hopefully, your sampling will go much better than mine did, but we can always learn from what didn't work.

Representativeness
A representative sample is, "a sample that looks like the population from which it was selected in all respects that are potentially relevant to the study" (Engel & Schutt, 2011).[65] For my study on how much it costs to get an LCSW in each state, I did not get a sample that looked like the overall population to which I wanted to generalize. My sample had a few states with more than ten responses and most states with no responses. That does not look like the true distribution of social workers across the country. I could compare the number of social workers in each state, based on data from the National Association of Social Workers, or the number of recent clinical MSW graduates from the Council on Social Work Education. More than that, I could see whether my sample matched the overall population of clinical social workers in gender, race, age, or any other important characteristics. Sadly, it wasn't even close. So, I wasn't able to use the data to publish a report.
Exercises
Critique the representativeness of the sample you are planning to gather.
- Will the sample of people (or documents) look like the population to which you want to generalize?
- Specifically, what characteristics are important in determining whether a sample is representative of the population? How do these characteristics relate to your research question?
Consider returning to this question once you have completed the sampling process and evaluate whether the sample in your study was similar to what you designed in this section.
Many of my students erroneously assume that using a probability sampling technique will guarantee a representative sample. This is not true. Engel and Schutt (2011) identify that probability sampling increases the chance of representativeness; however, it does not guarantee that the sample will be representative. If a representative sample is important to your study, it would be best to use a sampling approach that allows you to control the proportion of specific characteristics in your sample. For instance, stratified random sampling allows you to control the distribution of specific variables of interest within your sample. However, that requires knowing information about your participants before you hand them surveys or expose them to an experiment.
In my study, if I wanted to make sure I had a certain number of people from each state (state being the strata), making the proportion of social workers from each state in my sample similar to the overall population, I would need to know which email addresses were from which states. That was not information I had. So, instead I conducted simple random sampling and randomly selected 5,000 of 100,000 email addresses on the NASW list. There was less of a guarantee of representativeness, but whatever variation existed between my sample and the population would be due to random chance. This would not be true for an availability or convenience sample. While these sampling approaches are common for student projects, they come with significant limitations in that variation between the sample and population is due to factors other than chance. We will discuss these non-random differences later in the chapter when we talk about bias. For now, just remember that the representativeness of a sample is helped by using random sampling, though it is not a guarantee.
Exercises
- Before you start sampling, do you know enough about your sampling frame to use stratified random sampling, which increases the potential of getting a representative sample?
- Do you have enough information about your sampling frame to use another probability sampling approach like simple random sampling or cluster sampling?
- If little information is available on which to select people, are you using availability sampling? Remember that availability sampling is okay if it is the only approach that is feasible for the researcher, but it comes with significant limitations when drawing conclusions about a larger population.
Assessing representativeness should start prior to data collection. I mentioned that I drew my sample from the NASW email list, which (like most organizations) they sell to advertisers when companies or researchers need to advertise to social workers. How representative of my population is my sampling frame? Well, the first question to ask is what proportion of my sampling frame would actually meet my exclusion and inclusion criteria. Since my study focused specifically on clinical social workers, my sampling frame likely included social workers who were not clinical social workers, like macro social workers or social work managers. However, I knew, based on the information from NASW marketers, that many people who received my recruitment email would be clinical social workers or those working towards licensure, so I was satisfied with that. Anyone who didn't meet my inclusion criteria and opened the survey would be greeted with clear instructions that this survey did not apply to them.
At the same time, I should have assessed whether the demographics of the NASW email list and the demographics of clinical social workers more broadly were similar. Unfortunately, this was not information I could gather. I had to trust that this was likely to going to be the best sample I could draw and the most representative of all social workers.
Exercises
- Before you start, what do you know about your setting and potential participants?
- Are there likely to be enough people in the setting of your study who meet the inclusion criteria?
You want to avoid throwing out half of the surveys you get back because the respondents aren't a part of your target population. This is a common error I see in student proposals.
Many of you will sample people from your agency, like clients or staff. Let's say you work for a children's mental health agency, and you wanted to study children who have experienced abuse. Walking through the steps here might proceed like this:
- Think about or ask your coworkers how many of the clients at your agency have experienced this issue. If it's common, then clients at your agency would probably make a good sampling frame for your study. If not, then you may want to adjust your research question or consider a different agency to sample. You could also change your target population to be more representative with your sample. For example, while your agency's clients may not be representative of all children who have survived abuse, they may be more representative of abuse survivors in your state, region, or county. In this way, you can draw conclusions about a smaller population, rather than everyone in the world who is a victim of child abuse.
- Think about those characteristics that are important for individuals in your sample to have or not have. Obviously, the variables in your research question are important, but so are the variables related to it. Take a look at the empirical literature on your topic. Are there different demographic characteristics or covariates that are relevant to your topic?
- All of this assumes that you can actually access information about your sampling frame prior to collecting data. This is a challenge in the real world. Even if you ask around your office about client characteristics, there is no way for you to know for sure until you complete your study whether it was the most representative sampling frame you could find. When in doubt, go with whatever is feasible and address any shortcomings in sampling within the limitations section of your research report. A good project is a done project.
- While using a probability sampling approach helps with sample representativeness, it does not guarantee it. Due to random variation, samples may differ across important characteristics. If you can feasibly use a probability sampling approach, particularly stratified random sampling, it will help make your sample more representative of the population.
- Even if you choose a sampling frame that is representative of your population and use a probability sampling approach, there is no guarantee that the sample you are able to collect will be representative. Sometimes, people don't respond to your recruitment efforts. Other times, random chance will mean people differ on important characteristics from your target population. ¯\_(ツ)_/¯
In agency-based samples, the small size of the pool of potential participants makes it very likely that your sample will not be representative of a broader target population. Sometimes, researchers look for specific outcomes connected with sub-populations for that reason. Not all agency-based research is concerned with representativeness, and it is still worthwhile to pursue research that is relevant to only one location as its purpose is often to improve social work practice.

Sample size
Let's assume you have found a representative sampling frame, and that you are using one of the probability sampling approaches we reviewed in section 10.2. That should help you recruit a representative sample, but how many people do you need to recruit into your sample? As with many questions about sample quality, students should keep feasibility in mind. The easiest answer I've given as a professor is, "as many as you can, without hurting yourself." While your quantitative research question would likely benefit from hundreds or thousands of respondents, that is not likely to be feasible for a student who is working full-time, interning part-time, and in school full-time. Don't feel like your study has to be perfect, but make sure you note any limitations in your final report.
To the extent possible, you should gather as many people as you can in your sample who meet your criteria. But why? Let's think about an example you probably know well. Have you ever watched the TV show Family Feud? Each question the host reads off starts with, "we asked 100 people..." Believe it or not, Family Feud uses simple random sampling to conduct their surveys the American public. Part of the challenge on Family Feud is that people can usually guess the most popular answers, but those answers that only a few people chose are much harder. They seem bizarre, and are more difficult to guess. That's because 100 people is not a lot of people to sample. Essentially, Family Feud is trying to measure what the answer is for all 327 million people in the United States by asking 100 of them. As a result, the weird and idiosyncratic responses of a few people are likely to remain on the board as answers, and contestants have to guess answers fewer and fewer people in the sample provided. In a larger sample, the oddball answers would likely fade away and only the most popular answers would be represented on the game show's board.
In my ill-fated study of clinical social workers, I received 87 complete responses. That is far below the hundred thousand licensed or license-eligible clinical social workers. Moreover, since I wanted to conduct state-by-state estimates, there was no way I had enough people in each state to do so. For student projects, samples of 50-100 participants are more than enough to write a paper (or start a game show), but for projects in the real world with real-world consequences, it is important to recruit the appropriate number of participants. For example, if your agency conducts a community scan of people in your service area on what services they need, the results will inform the direction of your agency, which grants they apply for, who they hire, and its mission for the next several years. Being overly confident in your sample could result in wasted resources for clients.
So what is the right number? Theoretically, we could gradually increase the sample size so that the sample approaches closer and closer to the total size of the population (Bhattacherjeee, 2012).[66] But as we've talked about, it is not feasible to sample everyone. How do we find that middle ground? To answer this, we need to understand the sampling distribution. Imagine in your agency's survey of the community, you took three different probability samples from your community, and for each sample, you measured whether people experienced domestic violence. If each random sample was truly representative of the population, then your rate of domestic violence from the three random samples would be about the same and equal to the true value in the population.
But this is extremely unlikely, given that each random sample will likely constitute a different subset of the population, and hence, the rate of domestic violence you measure may be slightly different from sample to sample. Think about the sample you collect as existing on a distribution of infinite possible samples. Most samples you collect will be close to the population mean but many will not be. The degree to which they differ is associated with how much the subject you are sampling about varies in the population. In our example, samples will vary based on how varied the incidence of domestic violence is from person to person. The difference between the domestic violence rate we find and the rate for our overall population is called the sampling error.
An easy way to minimize sampling error is to increase the number of participants in your sample, but in actuality, minimizing sampling error relies on a number of factors outside of the scope of a basic student project. You can see this online textbook for more examples on sampling distributions or take an advanced methods course at your university, particularly if you are considering becoming a social work researcher. Increasing the number of people in your sample also increases your study's power, or the odds you will detect a significant relationship between variables when one is truly present in your sample. If you intend on publishing the findings of your student project, it is worth using a power analysis to determine the appropriate sample size for your project. You can follow this excellent video series from the Center for Open Science on how to conduct power analyses using free statistics software. A faculty members who teaches research or statistics could check your work. You may be surprised to find out that there is a point at which you adding more people to your sample will not make your study any better.
Honestly, I did not do a power analysis for my study. Instead, I asked for 5,000 surveys with the hope that 1,000 would come back. Given that only 87 came back, a power analysis conducted after the survey was complete would likely to reveal that I did not have enough statistical power to answer my research questions. For your projects, try to get as many respondents as you feasibly can, but don't worry too much about not reaching the optimal amount of people to maximize the power of your study unless you goal is to publish something that is generalizable to a large population.
A final consideration is which statistical test you plan to use to analyze your data. We have not covered statistics yet, though we will provide a brief introduction to basic statistics in this textbook. For now, remember that some statistical tests have a minimum number of people that must be present in the sample in order to conduct the analysis. You will complete a data analysis plan before you begin your project and start sampling, so you can always increase the number of participants you plan to recruit based on what you learn in the next few chapters.
Exercises
- How many people can you feasibly sample in the time you have to complete your project?

Bias
One of the interesting things about surveying professionals is that sometimes, they email you about what they perceive to be a problem with your study. I got an email from a well-meaning participant in my LCSW study saying that my results were going to be biased! She pointed out that respondents who had been in practice a long time, before clinical supervision was required, would not have paid anything for supervision. This would lead me to draw conclusions that supervision was cheap, when in fact, it was expensive. My email back to her explained that she hit on one of my hypotheses, that social workers in practice for a longer period of time faced fewer costs to becoming licensed. Her email reinforced that I needed to account for the impact of length of practice on the costs of licensure I found across the sample. She was right to be on the lookout for bias in the sample.
One of the key questions you can ask is if there is something about your process that makes it more likely you will select a certain type of person for your sample, making it less representative of the overall population. In my project, it's worth thinking more about who is more likely to respond to an email advertisement for a research study. I know that my work email and personal email filter out advertisements, so it's unlikely I would even see the recruitment for my own study (probably something I should have thought about before using grant funds to sample the NASW email list). Perhaps an older demographic that does not screen advertisements as closely, or those whose NASW account was linked to a personal email with fewer junk filters would be more likely to respond. To the extent I made conclusions about clinical social workers of all ages based on a sample that was biased towards older social workers, my results would be biased. This is called selection bias, or the degree to which people in my sample differ from the overall population.
Another potential source of bias here is nonresponse bias. Because people do not often respond to email advertisements (no matter how well-written they are), my sample is likely to be representative of people with characteristics that make them more likely to respond. They may have more time on their hands to take surveys and respond to their junk mail. To the extent that the sample is comprised of social workers with a lot of time on their hands (who are those people?) my sample will be biased and not representative of the overall population.
It's important to note that both bias and error describe how samples differ from the overall population. Error describes random variations between samples, due to chance. Using a random process to recruit participants into a sample means you will have random variation between the sample and the population. Bias creates variance between the sample and population in a specific direction, such as towards those who have time to check their junk mail. Bias may be introduced by the sampling method used or due to conscious or unconscious bias introduced by the researcher (Rubin & Babbie, 2017).[67] A researcher might select people who “look like good research participants,” in the process transferring their unconscious biases to their sample. They might exclude people from the sampling from who "would not do well with the intervention." Careful researchers can avoid these, but unconscious and structural biases can be challenging to root out.
Exercises
- Identify potential sources of bias in your sample and brainstorm ways you can minimize them, if possible.
Critical considerations
Think back to you undergraduate degree. Did you ever participate in a research project as part of an introductory psychology or sociology course? Social science researchers on college campuses have a luxury that researchers elsewhere may not share—they have access to a whole bunch of (presumably) willing and able human guinea pigs. But that luxury comes at a cost—sample representativeness. One study of top academic journals in psychology found that over two-thirds (68%) of participants in studies published by those journals were based on samples drawn in the United States (Arnett, 2008).[68] Further, the study found that two-thirds of the work that derived from US samples published in the Journal of Personality and Social Psychology was based on samples made up entirely of American undergraduate students taking psychology courses.
These findings certainly raise the question: What do we actually learn from social science studies and about whom do we learn it? That is exactly the concern raised by Joseph Henrich and colleagues (Henrich, Heine, & Norenzayan, 2010),[69] authors of the article “The Weirdest People in the World?” In their piece, Henrich and colleagues point out that behavioral scientists very commonly make sweeping claims about human nature based on samples drawn only from WEIRD (Western, Educated, Industrialized, Rich, and Democratic) societies, and often based on even narrower samples, as is the case with many studies relying on samples drawn from college classrooms. As it turns out, robust findings about the nature of human behavior when it comes to fairness, cooperation, visual perception, trust, and other behaviors are based on studies that excluded participants from outside the United States and sometimes excluded anyone outside the college classroom (Begley, 2010).[70] This certainly raises questions about what we really know about human behavior as opposed to US resident or US undergraduate behavior. Of course, not all research findings are based on samples of WEIRD folks like college students. But even then, it would behoove us to pay attention to the population on which studies are based and the claims being made about those to whom the studies apply.
Another thing to keep in mind is that just because a sample may be representative in all respects that a researcher thinks are relevant, there may be relevant aspects that didn’t occur to the researcher when she was drawing her sample. You might not think that a person’s phone would have much to do with their voting preferences, for example. But had pollsters making predictions about the results of the 2008 presidential election not been careful to include both cell phone-only and landline households in their surveys, it is possible that their predictions would have underestimated Barack Obama’s lead over John McCain because Obama was much more popular among cell phone-only users than McCain (Keeter, Dimock, & Christian, 2008).[71] This is another example of bias.

Putting it all together
So how do we know how good our sample is or how good the samples gathered by other researchers are? While there might not be any magic or always-true rules we can apply, there are a couple of things we can keep in mind as we read the claims researchers make about their findings.
First, remember that sample quality is determined only by the sample actually obtained, not by the sampling method itself. A researcher may set out to administer a survey to a representative sample by correctly employing a random sampling approach with impeccable recruitment materials. But, if only a handful of the people sampled actually respond to the survey, the researcher should not make claims like their sample went according to plan.
Another thing to keep in mind, as demonstrated by the preceding discussion, is that researchers may be drawn to talking about implications of their findings as though they apply to some group other than the population actually sampled. Whether the sampling frame does not match the population or the sample and population differ on important criteria, the resulting sampling error can lead to bad science.
We've talked previously about the perils of generalizing social science findings from graduate students in the United States and other Western countries to all cultures in the world, imposing a Western view as the right and correct view of the social world. As consumers of theory and research, it is our responsibility to be attentive to this sort of (likely unintentional) bait and switch. And as researchers, it is our responsibility to make sure that we only make conclusions from samples that are representative. A larger sample size and probability sampling can improve the representativeness and generalizability of the study's findings to larger populations, though neither are guarantees.
Finally, keep in mind that a sample allowing for comparisons of theoretically important concepts or variables is certainly better than one that does not allow for such comparisons. In a study based on a nonrepresentative sample, for example, we can learn about the strength of our social theories by comparing relevant aspects of social processes. We talked about this as theory-testing in Chapter 8.
At their core, questions about sample quality should address who has been sampled, how they were sampled, and for what purpose they were sampled. Being able to answer those questions will help you better understand, and more responsibly interpret, research results. For your study, keep the following questions in mind.
- Are your sample size and your sampling approach appropriate for your research question?
- How much do you know about your sampling frame ahead of time? How will that impact the feasibility of different sampling approaches?
- What gatekeepers and stakeholders are necessary to engage in order to access your sampling frame?
- Are there any ethical issues that may make it difficult to sample those who have first-hand knowledge about your topic?
- Does your sampling frame look like your population along important characteristics? Once you get your data, ask the same question of the sample you successfully recruit.
- What about your population might make it more difficult or easier to sample?
- How many people can you feasibly sample in the time you have to complete your project?
- Are there steps in your sampling procedure that may bias your sample to render it not representative of the population?
- If you want to skip sampling altogether, are there sources of secondary data you can use? Or might you be able to answer you questions by sampling documents or media, rather than people?
Key Takeaways
- The sampling plan you implement should have a reasonable likelihood of producing a representative sample. Student projects are given more leeway with nonrepresentative samples, and this limitation should be discussed in the student's research report.
- Researchers should conduct a power analysis to determine sample size, though quantitative student projects should endeavor to recruit as many participants as possible. Sample size impacts representativeness of the sample, its power, and which statistical tests can be conducted.
- The sample you collect is one of an infinite number of potential samples that could have been drawn. To the extent the data in your sample varies from the data in the entire population, it includes some error or bias. Error is the result of random variations. Bias is systematic error that pushes the data in a given direction.
- Even if you do everything right, there is no guarantee that you will draw a good sample. Flawed samples are okay to use as examples in the classroom, but the results of your research would have limited generalizability beyond your specific participants.
- Historically, samples were drawn from dominant groups and generalized to all people. This shortcoming is a limitation of some social science literature and should be considered a colonialist scientific practice.
Chapter Outline
- What is a survey, and when should you use one? (14 minute read)
- Collecting data using surveys (29 minute read)
- Bias and cultural considerations (22 minute read)
Content warning: examples in this chapter contain references to drug use, racism in politics, COVD-19, undocumented immigration, basic needs insecurity in higher education, school discipline, drunk driving, poverty, child sexual abuse, colonization and Global North/West hegemony, and ethnocentrism in science.
12.1 What is a survey, and when should you use one?
Learning Objectives
Learners will be able to...
- Distinguish between survey as a research design and questionnaires used to measure concepts
- Identify the strengths and weaknesses of surveys
- Evaluate whether survey design fits with their research question
Students in my research methods classes often feel that surveys are self-explanatory. This feeling is understandable. Surveys are part of our everyday lives. Every time you call customer service, purchase a meal, or participate in a program, someone is handing you a survey to complete. Survey results are often discussed in the news, and perhaps you've even carried our a survey yourself. What could be so hard? Ask people a few quick questions about your research question and you're done, right?
Students quickly learn that there is more to constructing a good survey than meets the eye. Survey design takes a great deal of thoughtful planning and often many rounds of revision, but it is worth the effort. As we’ll learn in this section, there are many benefits to choosing survey research as your data collection method particularly for student projects. We’ll discuss what a survey is, its potential benefits and drawbacks, and what research projects are the best fit for survey design.
Is survey research right for your project?
To answer this question, the first thing we need to do is distinguish between a survey and a questionnaire. They might seem like they are the same thing, and in normal non-research contexts, they are used interchangeably. In this textbook, we define a survey as a research design in which a researcher poses a set of predetermined questions to an entire group, or sample, of individuals. That set of questions is the questionnaire, a research instrument consisting of a set of questions (items) intended to capture responses from participants in a standardized manner. Basically, researchers use questionnaires as part of survey research. Questionnaires are the tool. Surveys are one research design for using that tool.
Let's contrast how survey research uses questionnaires with the other quantitative design we will discuss in this book—experimental design. Questionnaires in experiments are called pretests and posttests and they measure how participants change over time as a result of an intervention (e.g., a group therapy session) or a stimulus (e.g., watching a video of a political speech) introduced by the researcher. We will discuss experiments in greater detail in Chapter 13, but if testing an intervention or measuring how people react to something you do sounds like what you want to do with your project, experiments might be the best fit for you.

Surveys, on the other hand, do not measure the impact of an intervention or stimulus introduced by the researcher. Instead, surveys look for patterns that already exist in the world based on how people self-report on a questionnaire. Self-report simply means that the participants in your research study are answering questions about themselves, regardless of whether they are presented on paper, electronically, or read aloud by the researcher. Questionnaires structure self-report data into a standardized format—with everyone receiving the exact same questions and answer choices in the same order[72]—which makes comparing data across participants much easier. Researchers using surveys try to influence their participants as little as possible because they want honest answers.
Questionnaires are completed by individual people, so the unit of observation is almost always individuals, rather than groups or organizations. Generally speaking, individuals provide the most informed data about their own lives and experiences, so surveys often also use individuals as the unit of analysis. Surveys are also helpful in analyzing dyads, families, groups, organizations, and communities, but regardless of the unit of analysis, the unit of observation for surveys is usually individuals. Keep this in mind as you think about sampling for your project.
In some cases, getting the most-informed person to complete your questionnaire may not be feasible. As we discussed in Chapter 2 and Chapter 6, ethical duties to protect clients and vulnerable community members mean student research projects often study practitioners and other less-vulnerable populations rather than clients and community members. The ethical supervision needed via the IRB to complete projects that pose significant risks to participants takes time and effort, and as a result, student projects often rely on key informants like clinicians, teachers, and administrators who are less likely to be harmed by the survey. Key informants are people who are especially knowledgeable about your topic. If your study is about nursing, you should probably survey nurses. These considerations are more thoroughly addressed in Chapter 10. Sometimes, participants complete surveys on behalf of people in your target population who are infeasible to survey for some reason. Some examples of key informants include a head of household completing a survey about family finances or an administrator completing a survey about staff morale on behalf of their employees. In this case, the survey respondent is a proxy, providing their best informed guess about the responses other people might have chosen if they were able to complete the survey independently. You are relying on an individual unit of observation (one person filling out a self-report questionnaire) and group or organization unit of analysis (the family or organization the researcher wants to make conclusions about). Proxies are commonly used when the target population is not capable of providing consent or appropriate answers, as in young children and people with disabilities.
Proxies are relying on their best judgment of another person's experiences, and while that is valuable information, it may introduce bias and error into the research process. Student research projects, due to time and resource constraints, often include sampling people with second-hand knowledge, and this is simply one of many common limitations of their findings. Remember, every project has limitations. Social work researchers look for the most favorable choices in design and methodology, as there are no perfect projects. If you are planning to conduct a survey of people with second-hand knowledge of your topic, consider reworking your research question to be about something they have more direct knowledge about and can answer easily. One common missed opportunity I see is student researchers who want to understand client outcomes (unit of analysis) by surveying practitioners (unit of observation). If a practitioner has a caseload of 30 clients, it's not really possible to answer a question like "how much progress have your clients made?" on a survey. Would they just average all 30 clients together? Instead, design a survey that asks them about their education, professional experience, and other things they know about first-hand. By making your unit of analysis and unit of observation the same, you can ensure the people completing your survey are able to provide informed answers.
Researchers may introduce measurement error if the person completing the questionnaire does not have adequate knowledge or has a biased opinion about the phenomenon of interest. For instance, many schools of social work market themselves based on the rankings of social work programs published by US News and World Report. Last updated in 2019, the methodology for these rankings is simply to send out a survey to deans, directors, and administrators at schools of social work. No graduation rates, teacher evaluations, licensure pass rates, accreditation data, or other considerations are a part of these rankings. It's literally a popularity contest in which each school is asked to rank the others on a scale of 1-5, and ranked by highest average score. What if an informant is unfamiliar with a school or has a personal bias against a school?[73] This could significantly skew results. One might also question the validity of such a questionnaire in assessing something as important and economically impactful as the quality of social work education. We might envision how students might demand and create more authentic measures of school quality.
In summary, survey design best fits with research projects that have the following attributes:
- Researchers plan to collect their own raw data, rather than secondary analysis of existing data.
- Researchers have access to the most knowledgeable people (that you can feasibly and ethically sample) to complete the questionnaire.
- Research question is best answered with quantitative methods.
- Individuals are the unit of observation, and in many cases, the unit of analysis.
- Researchers will try to observe things objectively and try not to influence participants to respond differently.
- Research questions asks about indirect observables—things participants can self-report on a questionnaire.
- There are valid, reliable, and commonly used scales (or other self-report measures) for the variables in the research question.

Strengths of survey methods
Researchers employing survey research as a research design enjoy a number of benefits. First, surveys are an excellent way to gather lots of information from many people. In a study by Blackstone (2013)[74] on older people’s experiences in the workplace, researchers were able to mail a written questionnaire to around 500 people who lived throughout the state of Maine at a cost of just over $1,000. This cost included printing copies of a seven-page survey, printing a cover letter, addressing and stuffing envelopes, mailing the survey, and buying return postage for the survey. We realize that $1,000 is nothing to sneeze at, but just imagine what it might have cost to visit each of those people individually to interview them in person. You would have to dedicate a few weeks of your life at least, drive around the state, and pay for meals and lodging to interview each person individually. Researchers can double, triple, or even quadruple their costs pretty quickly by opting for an in-person method of data collection over a mailed survey. Thus, surveys are relatively cost-effective.
Related to the benefit of cost-effectiveness is a survey’s potential for generalizability. Because surveys allow researchers to collect data from very large samples for a relatively low cost, survey methods lend themselves to probability sampling techniques, which we discussed in Chapter 10. When used with probability sampling approaches, survey research is the best method to use when one hopes to gain a representative picture of the attitudes and characteristics of a large group. Unfortunately, student projects are quite often not able to take advantage of the generalizability of surveys because they use availability sampling rather than the more costly and time-intensive random sampling approaches that are more likely to elicit a representative sample. While the conclusions drawn from availability samples have far less generalizability, surveys are still a great choice for student projects and they provide data that can be followed up on by well-funded researchers to generate generalizable research.
Survey research is particularly adept at investigating indirect observables. Indirect observables are things we have to ask someone to self-report because we cannot observe them directly, such as people’s preferences (e.g., political orientation), traits (e.g., self-esteem), attitudes (e.g., toward immigrants), beliefs (e.g., about a new law), behaviors (e.g., smoking or drinking), or factual information (e.g., income). Unlike qualitative studies in which these beliefs and attitudes would be detailed in unstructured conversations, surveys seek to systematize answers so researchers can make apples-to-apples comparisons across participants. Surveys are so flexible because you can ask about anything, and the variety of questions allows you to expand social science knowledge beyond what is naturally observable.
Survey research also tends to be a reliable method of inquiry. This is because surveys are standardized in that the same questions, phrased in exactly the same way, as they are posed to participants. Other methods, such as qualitative interviewing, which we’ll learn about in Chapter 18, do not offer the same consistency that a quantitative survey offers. This is not to say that all surveys are always reliable. A poorly phrased question can cause respondents to interpret its meaning differently, which can reduce that question’s reliability. Assuming well-constructed questions and survey design, one strength of this methodology is its potential to produce reliable results.
The versatility of survey research is also an asset. Surveys are used by all kinds of people in all kinds of professions. They can measure anything that people can self-report. Surveys are also appropriate for exploratory, descriptive, and explanatory research questions (though exploratory projects may benefit more from qualitative methods). Moreover, they can be delivered in a number of flexible ways, including via email, mail, text, and phone. We will describe the many ways to implement a survey later on in this chapter.
In sum, the following are benefits of survey research:
- Cost-effectiveness
- Generalizability
- Variety
- Reliability
- Versatility

Weaknesses of survey methods
As with all methods of data collection, survey research also comes with a few drawbacks. First, while one might argue that surveys are flexible in the sense that you can ask any kind of question about any topic we want, once the survey is given to the first participant, there is nothing you can do to change the survey without biasing your results. Because surveys want to minimize the amount of influence that a researcher has on the participants, everyone gets the same questionnaire. Let’s say you mail a questionnaire out to 1,000 people and then discover, as responses start coming in, that your phrasing on a particular question seems to be confusing a number of respondents. At this stage, it’s too late for a do-over or to change the question for the respondents who haven’t yet returned their questionnaires. When conducting qualitative interviews or focus groups, on the other hand, a researcher can provide respondents further explanation if they’re confused by a question and can tweak their questions as they learn more about how respondents seem to understand them. Survey researchers often ask colleagues, students, and others to pilot test their questionnaire and catch any errors prior to sending it to participants; however, once researchers distribute the survey to participants, there is little they can do to change anything.
Depth can also be a problem with surveys. Survey questions are standardized; thus, it can be difficult to ask anything other than very general questions that a broad range of people will understand. Because of this, survey results may not provide as detailed of an understanding as results obtained using methods of data collection that allow a researcher to more comprehensively examine whatever topic is being studied. Let’s say, for example, that you want to learn something about voters’ willingness to elect an African American president. General Social Survey respondents were asked, “If your party nominated an African American for president, would you vote for him if he were qualified for the job?” (Smith, 2009).[75] Respondents were then asked to respond either yes or no to the question. But what if someone’s opinion was more complex than could be answered with a simple yes or no? What if, for example, a person was willing to vote for an African American man, but only if that person was a conservative, moderate, anti-abortion, antiwar, etc. Then we would miss out on that additional detail when the participant responded "yes," to our question. Of course, you could add a question to your survey about moderate vs. radical candidates, but could you do that for all of the relevant attributes of candidates for all people? Moreover, how do you know that moderate or antiwar means the same thing to everyone who participates in your survey? Without having a conversation with someone and asking them follow up questions, survey research can lack enough detail to understand how people truly think.
In sum, potential drawbacks to survey research include the following:
- Inflexibility
- Lack of depth
- Problems specific to cross-sectional surveys, which we will address in the next section.
Secondary analysis of survey data
This chapter is designed to help you conduct your own survey, but that is not the only option for social work researchers. Look back to Chapter 2 and recall our discussion of secondary data analysis. As we talked about previously, using data collected by another researcher can have a number of benefits. Well-funded researchers have the resources to recruit a large representative sample and ensure their measures are valid and reliable prior to sending them to participants. Before you get too far into designing your own data collection, make sure there are no existing data sets out there that you can use to answer your question. We refer you to Chapter 2 for all full discussion of the strengths and challenges of using secondary analysis of survey data.
Key Takeaways
- Strengths of survey research include its cost effectiveness, generalizability, variety, reliability, and versatility.
- Weaknesses of survey research include inflexibility and lack of potential depth. There are also weaknesses specific to cross-sectional surveys, the most common type of survey.
Exercises
If you are using quantitative methods in a student project, it is very likely that you are going to use survey design to collect your data.
- Check to make sure that your research question and study fit best with survey design using the criteria in this section
- Remind yourself of any limitations to generalizability based on your sampling frame.
- Refresh your memory on the operational definitions you will use for your dependent and independent variables.
12.2 Collecting data using surveys
Learning Objectives
Learners will be able to...
- Distinguish between cross-sectional and longitudinal surveys
- Identify the strengths and limitations of each approach to collecting survey data, including the timing of data collection and how the questionnaire is delivered to participants
As we discussed in the previous chapter, surveys are versatile and can be shaped and suited to most topics of inquiry. While that makes surveys a great research tool, it also means there are many options to consider when designing your survey. The two main considerations for designing surveys is how many times researchers will collect data from participants and how researchers contact participants and record responses to the questionnaire.
![]()
Cross-sectional surveys: A snapshot in time
Think back to the last survey you took. Did you respond to the questionnaire once or did you respond to it multiple times over a long period? Cross-sectional surveys are administered only one time. Chances are the last survey you took was a cross-sectional survey—a one-shot measure of a sample using a questionnaire. And chances are if you are conducting a survey to collect data for your project, it will be cross-sectional simply because it is more feasible to collect data once than multiple times.
Let's take a very recent example, the COVID-19 pandemic. Enriquez and colleagues (2021)[76] wanted to understand the impact of the pandemic on undocumented college students' academic performance, attention to academics, financial stability, mental and physical health, and other factors. In cooperation with offices of undocumented student support at eighteen campuses in California, the researchers emailed undocumented students a few times from March through June of 2020 and asked them to participate in their survey via an online questionnaire. Their survey presents an compelling look at how COVID-19 worsened existing economic inequities in this population.
Strengths and weaknesses of cross-sectional surveys
Cross-sectional surveys are great. They take advantage of many of the strengths of survey design. They are easy to administer since you only need to measure your participants once, which makes them highly suitable for student projects. Keeping track of participants for multiple measures takes time and energy, two resources always under constraint in student projects. Conducting a cross-sectional survey simply requires collecting a sample of people and getting them to fill out your questionnaire—nothing more.
That convenience comes with a tradeoff. When you only measure people at one point in time, you can miss a lot. The events, opinions, behaviors, and other phenomena that such surveys are designed to assess don’t generally remain the same over time. Because nomothetic causal explanations seek a general, universal truth, surveys conducted a decade ago do not represent what people think and feel today or twenty years ago. In student research projects, this weakness is often compounded by the use of availability sampling, which further limits the generalizability of the results in student research projects to other places and times beyond the sample collected by the researcher. Imagine generalizing results on the use of telehealth in social work prior to the COVID-19 pandemic or managers' willingness to allow employees to telecommute. Both as a result of shocks to the system—like COVID-19—and the linear progression of cultural, economic and social change—like human rights movements—cross-sectional surveys can never truly give us a timeless causal explanation. In our example about undocumented students during COVID-19, you can say something about the way things were in the moment that you administered your survey, but it is difficult to know whether things remained that way for long after you administered your survey or describe patterns that go back far in time.
Of course, just as society changes over time, so do people. Because cross-sectional surveys only measure people at one point in time, they have difficulty establishing cause-and-effect relationships for individuals because they cannot clearly establish whether the cause came before the effect. If your research question were about how school discipline (our independent variable) impacts substance use (our dependent variable), you would want to make that any changes in our dependent variable, substance use, came after changes in school discipline. That is, if your hypothesis is that says school discipline causes increases in substance use, you must establish that school discipline came first and increases in substance use came afterwards. However, it is perhaps just as likely that increased substance use might cause increases in school discipline. If you sent a cross-sectional survey to students asking them about their substance use and disciplinary record, you would get back something like "tried drugs or alcohol 6 times" and "has been suspended 5 times." You could see whether similar patterns existed in other students, but you wouldn't be able to tell which was the cause or the effect.
Because of these limitations, cross-sectional surveys are limited in how well they can establish whether a nomothetic causal relationship is true or not. Surveys are still a key part of establishing causality. But they need additional help and support to make causal arguments. That might come from combining data across surveys in meta-analyses and systematic reviews, integrating survey findings with theories that explain causal relationships among variables in the study, as well as corroboration from research using other designs, theories, and paradigms. Scientists can establish causal explanations, in part, based on survey research. However, in keeping with the assumptions of postpositivism, the picture of reality that emerges from survey research is only our best approximation of what is objectively true about human beings in the social world. Science requires a multi-disciplinary conversation among scholars to continually improve our understanding.

Longitudinal surveys: Measuring change over time
One way to overcome this sometimes-problematic aspect of cross-sectional surveys is to administer a longitudinal survey. Longitudinal surveys enable a researcher to make observations over some extended period of time. There are several types of longitudinal surveys, including trend, panel, and cohort surveys. We’ll discuss all three types here, along with retrospective surveys, which fall somewhere in between cross-sectional and longitudinal surveys.
The first type of longitudinal survey is called a trend survey. The main focus of a trend survey is, perhaps not surprisingly, trends. Researchers conducting trend surveys are interested in how people in a specific group change over time. Each time researchers gather data, they survey different people from the identified group because they are interested in the trends of the whole group, rather than changes in specific individuals. Let’s look at an example.
The Monitoring the Future Study is a trend study that described the substance use of high school children in the United States. It’s conducted annually by the National Institute on Drug Abuse (NIDA). Each year, the NIDA distributes surveys to children in high schools around the country to understand how substance use and abuse in that population changes over time. Perhaps surprisingly, fewer high school children reported using alcohol in the past month than at any point over the last 20 years—a fact that often surprises people because it cuts against the stereotype of adolescents engaging in ever-riskier behaviors. Nevertheless, recent data also reflected an increased use of e-cigarettes and the popularity of e-cigarettes with no nicotine over those with nicotine. By tracking these data points over time, we can better target substance abuse prevention programs towards the current issues facing the high school population.
Unlike trend surveys, panel surveys require the same people participate in the survey each time it is administered. As you might imagine, panel studies can be difficult and costly. Imagine trying to administer a survey to the same 100 people every year, for 5 years in a row. Keeping track of where respondents live, when they move, and when they change phone numbers takes resources that researchers often don’t have. However, when the researchers do have the resources to carry out a panel survey, the results can be quite powerful. The Youth Development Study (YDS), administered from the University of Minnesota, offers an excellent example of a panel study.
Since 1988, YDS researchers have administered an annual survey to the same 1,000 people. Study participants were in ninth grade when the study began, and they are now in their thirties. Several hundred papers, articles, and books have been written using data from the YDS. One of the major lessons learned from this panel study is that work has a largely positive impact on young people (Mortimer, 2003).[77] Contrary to popular beliefs about the impact of work on adolescents’ school performance and transition to adulthood, work increases confidence, enhances academic success, and prepares students for success in their future careers. Without this panel study, we may not be aware of the positive impact that working can have on young people.
Another type of longitudinal survey is a cohort survey. In a cohort survey, the participants have a defining characteristic that the researcher is interested in studying. The same people don’t necessarily participate from year to year, but all participants must meet whatever categorical criteria fulfill the researcher’s primary interest. Common cohorts that researchers study include people of particular generations or people born around the same time period, graduating classes, people who began work in a given industry at the same time, or perhaps people who have some specific historical experience in common. An example of this sort of research can be seen in Lindert and colleagues (2020)[78] work on healthy aging in men. Their article is a secondary analysis of longitudinal data collected as part of the Veterans Affairs Normative Aging Study conducted in 1985, 1988, and 1991.

Strengths and weaknesses of longitudinal surveys
All three types of longitudinal surveys share the strength that they permit a researcher to make observations over time. Whether a major world event takes place or participants mature, researchers can effectively capture the subsequent potential changes in the phenomenon or behavior of interest. This is the key strength of longitudinal surveys—their ability to establish temporality needed for nomothetic causal explanations. Whether your project investigates changes in society, communities, or individuals, longitudinal designs improve on cross-sectional designs by providing data at multiple points in time that better establish causality.
Of course, all of that extra data comes at a high cost. If a panel survey takes place over ten years, the research team must keep track of every individual in the study for those ten years, ensuring they have current contact information for their sample the whole time. Consider this study which followed people convicted of driving under the influence of drugs or alcohol (Kleschinsky et al., 2009).[79] It took an average of 8.6 contacts for participants to complete follow-up surveys, and while this was a difficult-to-reach population, researchers engaging in longitudinal research must prepare for considerable time and expense in tracking participants. Keeping in touch with a participant for a prolonged period of time likely requires building participant motivation to stay in the study, maintaining contact at regular intervals, and providing monetary compensation. Panel studies are not the only costly longitudinal design. Trend studies need to recruit a new sample every time they collect a new wave of data at additional cost and time.
In my years as a research methods instructor, I have never seen a longitudinal survey design used in a student research project because students do not have enough time to complete them. Cross-sectional surveys are simply the most convenient and feasible option. Nevertheless, social work researchers with more time to complete their studies use longitudinal surveys to understand causal relationships that they cannot manipulate themselves. A researcher could not ethically experiment on participants by assigning a jail sentence or relapse, but longitudinal surveys allow us to systematically investigate such sensitive phenomena ethically. Indeed, because longitudinal surveys observe people in everyday life, outside of the artificial environment of the laboratory (as in experiments), the generalizability of longitudinal survey results to real-world situations may make them superior to experiments, in some cases.
Table 12.1 summarizes these three types of longitudinal surveys.
| Sample type | Description |
| Trend | Researcher examines changes in trends over time; the same people do not necessarily participate in the survey more than once. |
| Panel | Researcher surveys the exact same sample several times over a period of time. |
| Cohort | Researcher identifies a defining characteristic and then regularly surveys people who have that characteristic. |
Retrospective surveys: Good, but not the best of both worlds
Retrospective surveys try to strike a middle ground between the two types of surveys. They are similar to other longitudinal studies in that they deal with changes over time, but like a cross-sectional study, data are collected only once. In a retrospective survey, participants are asked to report events from the past. By having respondents report past behaviors, beliefs, or experiences, researchers are able to gather longitudinal-like data without actually incurring the time or expense of a longitudinal survey. Of course, this benefit must be weighed against the possibility that people’s recollections of their pasts may be faulty. Imagine that you are participating in a survey that asks you to respond to questions about your feelings on Valentine’s Day. As last Valentine’s Day can’t be more than 12 months ago, there is a good chance that you are able to provide a pretty accurate response of how you felt. Now let’s imagine that the researcher wants to know how last Valentine’s Day compares to previous Valentine’s Days, so the survey asks you to report on the preceding six Valentine’s Days. How likely is it that you will remember how you felt at each one? Will your responses be as accurate as they might have been if your data were collected via survey once a year rather reporting the past few years today? The main limitation with retrospective surveys are that they are not as reliable as cross-section or longitudinal surveys. That said, retrospective surveys are a feasible way to collect longitudinal data when the researcher only has access to the population once, and for this reason, they may be worth the drawback of greater risk of bias and error in the measurement process.
Because quantitative research seeks to build nomothetic causal explanations, it is important to determine the order in which things happen. When using survey design to investigate causal relationships between variables in a research question, longitudinal surveys are certainly preferable because they can track changes over time and therefore provide stronger evidence for cause-and-effect relationships. As we discussed, the time and cost required to administer a longitudinal survey can be prohibitive, and most survey research in the scholarly literature is cross-sectional because it is more feasible to collect data once. Well designed cross-sectional surveys provide can provide important evidence for a causal relationship, even if it is imperfect. Once you decide how many times you will collect data from your participants, the next step is to figure out how to get your questionnaire in front of participants.

Self-administered questionnaires
If you are planning to conduct a survey for your research project, chances are you have thought about how you might deliver your survey to participants. If you don't have a clear picture yet, look back at your work from Chapter 11 on the sampling approach for your project. How are you planning to recruit participants from your sampling frame? If you are considering contacting potential participants via phone or email, perhaps you want to collect your data using a phone or email survey attached to your recruitment materials. If you are planning to collect data from students, colleagues, or other people you most commonly interact with in-person, maybe you want to consider a pen-and-paper survey to collect your data conveniently. As you review the different approaches to administering surveys below, consider how each one matches with your sampling approach and the contact information you have for study participants. Ensure that your sampling approach is feasible conduct before building your survey design from it. For example, if you are planning to administer an online survey, make sure you have email addresses to send your questionnaire or permission to post your survey to an online forum.
Surveys are a versatile research approach. Survey designs vary not only in terms of when they are administered but also in terms of how they are administered. One common way to collect data is in the form of self-administered questionnaires. Self-administered means that the research participant completes the questions independently, usually in writing. Paper questionnaires can be delivered to participants via mail or in person whenever you see your participants. Generally, student projects use in-person collection of paper questionnaires, as mail surveys require physical addresses, spending money, and waiting for the mail. It is common for academic researchers to administer surveys in large social science classes, so perhaps you have taken a survey that was given to you in-person during undergraduate classes. These professors were taking advantage of the same convenience sampling approach that student projects often do. If everyone in your sampling frame is in one room, going into that room and giving them a quick paper survey to fill out is a feasible and convenient way to collect data. Availability sampling may involve asking your sampling frame to complete your study during when they naturally meet—colleagues at a staff meeting, students in the student lounge, professors in a faculty meeting—and self-administered questionnaires are one way to take advantage of this natural grouping of your target population. Try to pick a time and situation when people have the downtime needed to complete your questionnaire, and you can maximize the likelihood that people will participate in your in-person survey. Of course, this convenience may come at the cost of privacy and confidentiality. If your survey addresses sensitive topics, participants may alter their responses because they are in close proximity to other participants while they complete the survey. Regardless of whether participants feel self-conscious or talk about their answers with one another, by potentially altering the participants' honest response you may have introduced bias or error into your measurement of the variables in your research question.
Because student research projects often rely on availability sampling, collecting data using paper surveys from whoever in your sampling frame is convenient makes sense because the results will be of limited generalizability. But for researchers who aim to generalize (and students who want to publish their study!), self-administered surveys may be better distributed via the mail or electronically. While is very unusual for a student project to send a questionnaire via the mail, this method is used quite often in the scholarly literature and for good reason. Survey researchers who deliver their surveys via postal mail often provide some advance notice to respondents about the survey to get people thinking and preparing to complete it. They may also follow up with their sample a few weeks after their survey has been sent out. This can be done not only to remind those who have not yet completed the survey to please do so but also to thank those who have already returned the survey. Most survey researchers agree that this sort of follow-up is essential for improving mailed surveys’ return rates (Babbie, 2010). [6] Other helpful tools to increase response rate are to create an attractive and professional survey, offer monetary incentives, and provide a pre-addressed, stamped return envelope. These are also effective for other types of surveys.
While snail mail may not be feasible for student project, it is increasingly common for student projects and social science projects to use email and other modes of online delivery like social media to collect responses to a questionnaire. Researchers like online delivery for many reasons. It's quicker than knocking on doors in a neighborhood for an in-person survey or waiting for mailed surveys to be returned. It's cheap, too. There are many free tools like Google Forms and Survey Monkey (which includes a premium option). While you are affiliated with a university, you may have access to commercial research software like Redcap or Qualtrics which provide much more advanced tools for collecting survey data than free options. Online surveys can take advantage of the advantages of computer-mediated data collection by playing a video before asking a question, tracking how long participants take to answer each question, and making sure participants don't fill out the survey more than once (to name a few examples. Moreover, survey data collected via online forms can be exported for analysis in spreadsheet software like Google Sheets or Microsoft Excel or statistics software like SPSS or JASP, a free and open-source alternative to SPSS. While the exported data still need to be checked before analysis, online distribution saves you the trouble of manually inputting every response a participant writes down on a paper survey into a computer to analyze.
The process of collecting data online depends on your sampling frame and approach to recruitment. If your project plans to reach out to people via email to ask them to participate in your study, you should attach your survey to your recruitment email. You already have their attention, and you may not get it again (even if you remind them). Think pragmatically. You will need access to the email addresses of people in your sampling frame. You may be able to piece together a list of email addresses based on public information (e.g., faculty email addresses are on their university webpage, practitioner emails are in marketing materials). In other cases, you may know of a pre-existing list of email addresses to which your target population subscribes (e.g., all undergraduate students in a social work program, all therapists at an agency), and you will need to gain the permission of the list's administrator recruit using the email platform. Other projects will identify an online forum in which their target population congregates and recruit participants there. For example, your project might identify a Facebook group used by students in your social work program or practitioners in your local area to distribute your survey. Of course, you can post a survey to your personal social media account (or one you create for the survey), but depending on your question, you will need a detailed plan on how to reach participants with enough relevant knowledge about your topic to provide informed answers to your questionnaire.
Many of the suggestions that were provided earlier to improve the response rate of hard copy questionnaires also apply to online questionnaires, including the development of an attractive survey and sending reminder emails. One challenge not present in mail surveys is the spam filter or junk mail box. While people will at least glance at recruitment materials send via mail, email programs may automatically filter out recruitment emails so participants never see them at all. While the financial incentives that can be provided online differ from those that can be given in person or by mail, online survey researchers can still offer completion incentives to their respondents. Over the years, I’ve taken numerous online surveys. Often, they did not come with any incentive other than the joy of knowing that I’d helped a fellow social scientist do their job. However, some surveys have their perks. One survey offered a coupon code to use for $30 off any order at a major online retailer and another allowed the opportunity to be entered into a lottery with other study participants to win a larger gift, such as a $50 gift card or a tablet computer. Student projects should not pay participants unless they have grant funding to cover that cost, and there should be no expectations of any out-of-pocket costs for students to complete their research project.
One area in which online surveys are less suitable than mail or in-person surveys is when your target population includes individuals with limited, unreliable, or no access to the internet or individuals with limited computer skills. For these groups, an online survey is inaccessible. At the same time, online surveys offer the most feasible way to collect data anonymously. By posting recruitment materials to a Facebook group or list of practitioners at an agency, you can avoid collecting identifying information from people who participated in your study. For studies that address sensitive topics, online surveys also offer the opportunity to complete the survey privately (again, assuming participants have access to a phone or personal computer). If you have the person's email address, physical address, or met them in-person, your participants are not anonymous, but if you need to collect data anonymously, online tools offer a feasible way to do so.
The best way to collect data using self-administered questionnaires depends on numerous factors. The strengths and weaknesses of in-person, mail, and electronic self-administered surveys are reviewed in Table 12.2. Ultimately, you must make the best decision based on its congruence with your sampling approach and what you can feasibly do. Decisions about survey design should be done with a deep appreciation for your study's target population and how your design choices may impact their responses to your survey.
| In-person | Electronic | ||
| Cost | Depends: it's easy if your participants congregate in an accessible location; but costly to go door-to-door to collect surveys | Depends: it's too expensive for unfunded projects but a cost-effective option for funded projects | Strength: it's free and easy to use online survey tools |
| Time | Depends: it's easy if your participants congregate in an accessible location; but time-consuming to go door-to-door to collect surveys | Weakness: it can take a while for mail to travel | Strength: delivery is instantaneous |
| Response rate | Strength: it can be harder to ignore someone in person | Weakness: it is easy to ignore junk mail, solicitations | Weakness: it's easy to ignore junk mail; spam filter may block you |
| Privacy | Weakness: it is very difficult to provide anonymity and people may have to respond in a public place, rather than privately in a safe place | Depends: it cannot provide true anonymity as other household members may see participants' mail, but people can likely respond privately in a safe place | Strength: can collect data anonymously and respond privately in a safe place |
| Reaching difficult populations | Strength: by going where your participants already gather, you increase your likelihood of getting responses | Depends: it reaches those without internet, but misses those who change addresses often (e.g., college students) | Depends: it misses those who change phone or emails often or don’t use the internet; but reaches online communities |
| Interactivity | Weakness: paper questionnaires are not interactive | Weakness: paper questionnaires are not interactive | Strength: electronic questionnaires can include multimedia elements, interactive questions and response options |
| Data input | Weakness: researcher inputs data manually | Weakness: researcher inputs data manually | Strength: survey software inputs data automatically |

Quantitative interviews: Researcher-administered questionnaires
There are some cases in which it is not feasible to provide a written questionnaire to participants, either on paper or digitally. In this case, the questionnaire can be administered verbally by the researcher to respondents. Rather than the participant reading questions independently on paper or digital screen, the researcher reads questions and answer choices aloud to participants and records their responses for analysis. Another word for this kind of questionnaire is an interview schedule. It's called a schedule because each question and answer is posed in the exact same way each time.
Consistency is key in quantitative interviews. By presenting each question and answer option in exactly the same manner to each interviewee, the researcher minimizes the potential for the interviewer effect, which encompasses any possible changes in interviewee responses based on how or when the researcher presents question-and-answer options. Additionally, in-person surveys may be video recorded and you can typically take notes without distracting the interviewee due to the closed-ended nature of survey questions, making them helpful for identifying how participants respond to the survey or which questions might be confusing.
Quantitative interviews can take place over the phone or in-person. Phone surveys are often conducted by political polling firms to understand how the electorate feels about certain candidates or policies. In both cases, researchers verbally pose questions to participants. For many years, live-caller polls (a live human being calling participants in a phone survey) were the gold-standard in political polling. Indeed, phone surveys were excellent for drawing representative samples prior to mobile phones. Unlike landlines, cell phone numbers are portable across carriers, associated with individuals as opposed to households, and do not change their first three numbers when people move to a new geographical area. For this reason, many political pollsters have moved away from random-digit phone dialing and toward a mix of data collection strategies like texting-based surveys or online panels to recruit a representative sample and generalizable results for the target population (Silver, 2021).[80]
I guess I should admit that I often decline to participate in phone studies when I am called. In my defense, it's usually just a customer service survey! My point is that it is easy and even socially acceptable to abruptly hang up on an unwanted caller asking you to participate in a survey, and given the high incidence of spam calls, many people do not pick up the phone for numbers they do not know. We will discuss response rates in greater detail at the end of the chapter. One of the benefits of phone surveys is that a person can complete them in their home or a safe place. At the same time, a distracted participant who is cooking dinner, tending to children, or driving may not provide accurate answers to your questions. Phone surveys make it difficult to control the environment in which a person answers your survey. When administering a phone survey, the researcher can record responses on a paper questionnaire or directly into a computer program. For large projects in which many interviews must be conducted by research staff, computer-assisted telephone interviewing (CATI) ensures that each question and answer option are presented the same way and input into the computer for analysis. For student projects, you can read from a digital or paper copy of your questionnaire and record participants responses into a spreadsheet program like Excel or Google Sheets.
Interview schedules must be administered in such a way that the researcher asks the same question the same way each time. While questions on self-administered questionnaires may create an impression based on the way they are presented, having a researcher pose the questions verbally introduces additional variables that might influence a respondent. Controlling one's wording, tone of voice, and pacing can be difficult over the phone, but it is even more challenging in-person because the researcher must also control their non-verbal expressions and behaviors that may bias survey respondents. Even a slight shift in emphasis or wording may bias the respondent to answer differently. As we've mentioned earlier, consistency is key with quantitative data collection—and human beings are not necessarily known for their consistency. But what happens if a participant asks a question of the researcher? Unlike self-administered questionnaires, quantitative interviews allow the participant to speak directly with the researcher if they need more information about a question. While this can help participants respond accurately, it can also introduce inconsistencies between how the survey administered to each participant. Ideally, the researcher should draft sample responses researchers might provide to participants if they are confused on certain survey items. The strengths and weaknesses of phone and in-person quantitative interviews are summarized in Table 12.3 below.
| In-person | Phone | |
| Cost | Depends: it's easy if your participants congregate in an accessible location; but costly to go door-to-door to collect surveys | Strength: phone calls are free or low-cost |
| Time | Weakness: quantitative interviews take a long time because each question must be read aloud to each participant | Weakness: quantitative interviews take a long time because each question must be read aloud to each participant |
| Response rate | Strength: it can be harder to ignore someone in person | Weakness: it is easy to ignore unwanted or unexpected calls |
| Privacy | Weakness: it is very difficult to provide anonymity and people will have to respond in a public place, rather than privately in a safe place | Depends: it is difficult for the researcher to control the context in which the participant responds, which might be private or public, safe or unsafe |
| Reaching difficult populations | Strength: by going where your participants already gather, you increase your likelihood of getting responses | Weakness: it is easy to ignore unwanted or unexpected calls |
| Interactivity | Weakness: interview schedules are kept simple because questions are read aloud | Weakness: interview schedules are kept simple because questions are read aloud |
| Data input | Weakness: researcher inputs data manually | Weakness: researcher inputs data manually |
Students using survey design should settle on a delivery method that presents the most favorable tradeoff between strengths and challenges for their unique context. One key consideration is your sampling approach. If you already have the participant on the phone and they agree to be a part of your sample...you may as well ask them your survey questions right then if the participant can do so. These feasibility concerns make in-person quantitative interviews a poor fit for student projects. It is far easier and quicker to distribute paper surveys to a group of people it is to administer the survey verbally to each participant individually. Ultimately, you are the one who has to carry out your research design. Make sure you can actually follow your plan!
Key Takeaways
- Time is a factor in determining what type of survey a researcher administers; cross-sectional surveys are administered at one time, and longitudinal surveys are at multiple points in time.
- Retrospective surveys offer some of the benefits of longitudinal research while only collecting data once but may be less reliable.
- Self-administered questionnaires may be delivered in-person, online, or via mail.
- Interview schedules are used with in-person or phone surveys (a.k.a. quantitative interviews).
- Each way to administer surveys comes with benefits and drawbacks.
Exercises
In this section, we assume that you are using a cross-sectional survey design. But how will you deliver your survey? Recall your sampling approach you developed in Chapter 10. Consider the following questions when evaluating delivery methods for surveys.
- Can you attach your survey to your recruitment emails, calls, or other contacts with potential participants?
- What contact information (e.g., phone number, email address) do you need to deliver your survey?
- Do you need to maintain participant anonymity?
- Is there anything unique about your target population or sampling frame that may impact survey research?
Imagine you are a participant in your survey.
- Beginning with the first contact for recruitment into your study and ending with a completed survey, describe each step of the data collection process from the perspective of a person responding to your survey. You should be able to provide a pretty clear timeline of how your survey will proceed at this point, even if some of the details eventually change.
12.3 Bias and cultural considerations
Learning Objectives
Learners will be able to...
- Identify the logic behind survey design as it relates to nomothetic causal explanations and quantitative methods.
- Discuss sources of bias and error in surveys.
- Apply criticisms of survey design to ensure more equitable research.
The logic of survey design
As you may have noticed with survey designs, everything about them is intentional—from the delivery method, to question wording, to what response options are offered. It's helpful to spell out the underlying logic behind survey design and how well it meets the criteria for nomothetic causal explanations. Because we are trying to isolate the causal relationship between our dependent and independent variable, we must try to control for as many possible confounding factors as possible. Researchers using survey design do this in multiple ways:
- Using well-established, valid, and reliable measures of key variables, including triangulating variables using multiple measures
- Measuring control variables and including them in their statistical analysis
- Avoiding biased wording, presentation, or procedures that might influence the sample to respond differently
- Pilot testing questionnaires, preferably with people similar to the sample
In other words, survey researchers go through a lot of trouble to make sure they are not the ones causing the changes they observe in their study. Of course, every study falls a little short of this ideal bias-free design, and some studies fall far short of it. This section is all about how bias and error can inhibit the ability of survey results to meaningfully tell us about causal relationships in the real world.
Bias in questionnaires, questions, and response options
The use of surveys is based on methodological assumptions common to research in the postpositivist paradigm. Figure 12.5 presents a model the methodological assumptions behind survey design—what researchers assume is the cognitive processes that people engage in when responding to a survey item (Sudman, Bradburn, & Schwarz, 1996).[81] Respondents must interpret the question, retrieve relevant information from memory, form a tentative judgment, convert the tentative judgment into one of the response options provided (e.g., a rating on a 1-to-7 scale), and finally edit their response as necessary.

Consider, for example, the following questionnaire item:
- How many alcoholic drinks do you consume in a typical day?
-
- a lot more than average
- somewhat more than average
- average
- somewhat fewer than average
- a lot fewer than average
Although this item at first seems straightforward, it poses several difficulties for respondents. First, they must interpret the question. For example, they must decide whether “alcoholic drinks” include beer and wine (as opposed to just hard liquor) and whether a “typical day” is a typical weekday, typical weekend day, or both. Even though Chang and Krosnick (2003)[82] found that asking about “typical” behavior has been shown to be more valid than asking about “past” behavior, their study compared “typical week” to “past week” and may be different when considering typical weekdays or weekend days).
Once respondents have interpreted the question, they must retrieve relevant information from memory to answer it. But what information should they retrieve, and how should they go about retrieving it? They might think vaguely about some recent occasions on which they drank alcohol, they might carefully try to recall and count the number of alcoholic drinks they consumed last week, or they might retrieve some existing beliefs that they have about themselves (e.g., “I am not much of a drinker”). Then they must use this information to arrive at a tentative judgment about how many alcoholic drinks they consume in a typical day. For example, this mental calculation might mean dividing the number of alcoholic drinks they consumed last week by seven to come up with an average number per day. Then they must format this tentative answer in terms of the response options actually provided. In this case, the options pose additional problems of interpretation. For example, what does “average” mean, and what would count as “somewhat more” than average? Finally, they must decide whether they want to report the response they have come up with or whether they want to edit it in some way. For example, if they believe that they drink a lot more than average, they might not want to report that for fear of looking bad in the eyes of the researcher, so instead, they may opt to select the “somewhat more than average” response option.
At first glance, this question is clearly worded and includes a set of mutually exclusive, exhaustive, and balanced response options. However, it is difficult to follow the logic of what is truly being asked. Again, this complexity can lead to unintended influences on respondents’ answers. Confounds like this are often referred to as context effects because they are not related to the content of the item but to the context in which the item appears (Schwarz & Strack, 1990).[83] For example, there is an item-order effect when the order in which the items are presented affects people’s responses. One item can change how participants interpret a later item or change the information that they retrieve to respond to later items. For example, researcher Fritz Strack and his colleagues asked college students about both their general life satisfaction and their dating frequency (Strack, Martin, & Schwarz, 1988).[84] When the life satisfaction item came first, the correlation between the two was only −.12, suggesting that the two variables are only weakly related. But when the dating frequency item came first, the correlation between the two was +.66, suggesting that those who date more have a strong tendency to be more satisfied with their lives. Reporting the dating frequency first made that information more accessible in memory so that they were more likely to base their life satisfaction rating on it.
The response options provided can also have unintended effects on people’s responses (Schwarz, 1999).[85] For example, when people are asked how often they are “really irritated” and given response options ranging from “less than once a year” to “more than once a month,” they tend to think of major irritations and report being irritated infrequently. But when they are given response options ranging from “less than once a day” to “several times a month,” they tend to think of minor irritations and report being irritated frequently. People also tend to assume that middle response options represent what is normal or typical. So if they think of themselves as normal or typical, they tend to choose middle response options (i.e., fence-sitting). For example, people are likely to report watching more television when the response options are centered on a middle option of 4 hours than when centered on a middle option of 2 hours. To mitigate against order effects, rotate questions and response items when there is no natural order. Counterbalancing or randomizing the order of presentation of the questions in online surveys are good practices for survey questions and can reduce response order effects that show that among undecided voters, the first candidate listed in a ballot receives a 2.5% boost simply by virtue of being listed first![86]
Other context effects that can confound the causal relationship under examination in a survey include social desirability bias, recall bias, and common method bias. As we discussed in Chapter 11, social desirability bias occurs when we create questions that lead respondents to answer in ways that don't reflect their genuine thoughts or feelings to avoid being perceived negatively. With negative questions such as, "do you think that your project team is dysfunctional?", "is there a lot of office politics in your workplace?", or "have you ever illegally downloaded music files from the Internet?", the researcher may not get truthful responses. This tendency among respondents to “spin the truth” in order to portray themselves in a socially desirable manner is called social desirability bias, which hurts the validity of responses obtained from survey research. There is practically no way of overcoming social desirability bias in a questionnaire survey outside of wording questions using nonjudgmental language. However, in a quantitative interview, a researcher may be able to spot inconsistent answers and ask probing questions or use personal observations to supplement respondents’ comments.
As you can see, participants' responses to survey questions often depend on their motivation, memory, and ability to respond. Particularly when dealing with events that happened in the distant past, respondents may not adequately remember their own motivations or behaviors, or perhaps their memory of such events may have evolved with time and are no longer retrievable. This phenomenon is know as recall bias. For instance, if a respondent is asked to describe their utilization of computer technology one year ago, their response may not be accurate due to difficulties with recall. One possible way of overcoming the recall bias is by anchoring the respondent’s memory in specific events as they happened, rather than asking them to recall their perceptions and motivations from memory.
Cross-sectional and retrospective surveys are particularly vulnerable to recall bias as well as common method bias. Common method bias can occur when measuring both independent and dependent variables at the same time (like a cross-section survey) and using the same instrument (like a questionnaire). In such cases, the phenomenon under investigation may not be adequately separated from measurement artifacts. Standard statistical tests are available to test for common method bias, such as Harmon’s single-factor test (Podsakoff et al. 2003),[87], Lindell and Whitney’s (2001)[88] market variable technique, and so forth. This bias can be potentially avoided if the independent and dependent variables are measured at different points in time, using a longitudinal survey design, or if these variables are measured using different data sources, such as medical or student records rather than self-report questionnaires.

Bias in recruitment and response to surveys
So far, we have discussed errors that researchers make when they design questionnaires that accidentally influence participants to respond one way or another. However, even well designed questionnaires can produce biased results when administered to survey respondents because of the biases in who actually responds to your survey.
Survey research is notorious for its low response rates. A response rate of 15-20% is typical in a mail survey, even after two or three reminders. If the majority of the targeted respondents fail to respond to a survey, then a legitimate concern is whether non-respondents are not responding due to a systematic reason, which may raise questions about the validity and generalizability of the study’s results, especially as this relates to the representativeness of the sample. This is known as non-response bias. For instance, dissatisfied customers tend to be more vocal about their experience than satisfied customers, and are therefore more likely to respond to satisfaction questionnaires. Hence, any respondent sample is likely to have a higher proportion of dissatisfied customers than the underlying population from which it is drawn.[89] In this instance, the results would not be generalizable beyond this one biased sample. Here are several strategies for addressing non-response bias:
- Advance notification: A short letter sent in advance to the targeted respondents soliciting their participation in an upcoming survey can prepare them and improve likelihood of response. The letter should state the purpose and importance of the study, mode of data collection (e.g., via a phone call, a survey form in the mail, etc.), and appreciation for their cooperation. A variation of this technique may request the respondent to return a postage-paid postcard indicating whether or not they are willing to participate in the study.
- Ensuring that content is relevant: If a survey examines issues of relevance or importance to respondents, then they are more likely to respond.
- Creating a respondent-friendly questionnaire: Shorter survey questionnaires tend to elicit higher response rates than longer questionnaires. Furthermore, questions that are clear, inoffensive, and easy to respond to tend to get higher response rates.
- Having the project endorsed: For organizational surveys, it helps to gain endorsement from a senior executive attesting to the importance of the study to the organization. Such endorsements can be in the form of a cover letter or a letter of introduction, which can improve the researcher’s credibility in the eyes of the respondents.
- Providing follow-up requests: Multiple follow-up requests may coax some non-respondents to respond, even if their responses are late.
- Ensuring that interviewers are properly trained: Response rates for interviews can be improved with skilled interviewers trained on how to request interviews, use computerized dialing techniques to identify potential respondents, and schedule callbacks for respondents who could not be reached.
- Providing incentives: Response rates, at least with certain populations, may increase with the use of incentives in the form of cash or gift cards, giveaways such as pens or stress balls, entry into a lottery, draw or contest, discount coupons, the promise of contribution to charity, and so forth.
- Providing non-monetary incentives: Organizations in particular are more prone to respond to non-monetary incentives than financial incentives. An example of such a non-monetary incentive sharing trainings and other resources based on the results of a project with a key stakeholder.
- Making participants fully aware of confidentiality and privacy: Finally, assurances that respondents’ private data or responses will not fall into the hands of any third party may help improve response rates.
Nonresponse bias impairs the ability of the researcher to generalize from the total number of respondents in the sample to the overall sampling frame. Of course, this assumes that the sampling frame is itself representative and generalizable to the larger target population. Sampling bias is present when the people in our sampling frame or the approach we use to sample them results in a sample that does not represent our population in some way. Telephone surveys conducted by calling a random sample of publicly available telephone numbers will systematically exclude people with unlisted telephone numbers, mobile phone numbers, and will include a disproportionate number of respondents who have land-line telephone service and stay home during much of the day, such as people who are unemployed, disabled, or of advanced age. Likewise, online surveys tend to include a disproportionate number of students and younger people who are more digitally connected, and systematically exclude people with limited or no access to computers or the Internet, such as the poor and the elderly. A different kind of sampling bias relates to generalizing from key informants to a target population, such as asking teachers (or parents) about the academic learning of their students (or children) or asking CEOs about operational details in their company. These sampling frames may provide a clearer picture of what key informants think and feel, rather than the target population.

Cultural bias
The acknowledgement that most research in social work and other adjacent fields is overwhelmingly based on so-called WEIRD (Western, educated, industrialized, rich and democratic) populations—a topic we discussed in Chapter 10—has given way to intensified research funding, publication, and visibility of collaborative cross-cultural studies across the social sciences that expand the geographical range of study populations. Many of the so-called non-WEIRD communities who increasingly participate in research are Indigenous, from low- and middle-income countries in the global South, live in post-colonial contexts, and/or are marginalized within their political systems, revealing and reproducing power differentials between researchers and researched (Whiteford & Trotter, 2008).[90] Cross-cultural research has historically been rooted in racist, capitalist ideas and motivations (Gordon, 1991).[91] Scholars have long debated whether research aiming to standardize cross-cultural measurements and analysis is tacitly engaged and/or continues to be rooted in colonial and imperialist practices (Kline et al., 2018; Stearman, 1984).[92] Given this history, it is critical that scientists reflect upon these issues and be accountable to their participants and colleagues for their research practices. We argue that cross-cultural research be grounded in the recognition of the historical, political, sociological and cultural forces acting on the communities and individuals of focus. These perspectives are often contrasted with ‘science’; here we argue that they are necessary as a foundation for the study of human behavior.
We stress that our goal is not to review the literature on colonial or neo-colonial research practices, to provide a comprehensive primer on decolonizing approaches to field research, nor to identify or admonish past harms in these respects—harms to which many of the authors of this piece would readily admit. Furthermore, we acknowledge that we ourselves are writing from a place of privilege as researchers educated and trained in disciplines with colonial pasts. Our goal is simply to help students understand the broader issues in cross-cultural studies for appropriate consideration of diverse communities and culturally appropriate methodologies for student research projects.
Equivalence of measures across cultures
Data collection methods largely stemming from WEIRD intellectual traditions are being exported to a range of cultural contexts. This is often done with insufficient consideration of the translatability (e.g. equivalence or applicability) or implementation of such concepts and methods in different contexts, as already well documented (e.g., Hruschka et al., 2018).[93] For example, in a developmental psychology study conducted by Broesch and colleagues (2011),[94] the research team exported a task to examine the development and variability of self-recognition in children across cultures. Typically, this milestone is measured by surreptitiously placing a mark on a child's forehead and allowing them to discover their reflective image and the mark in a mirror. While self-recognition in WEIRD contexts typically manifests in children by 18 months of age, the authors tested found that only 2 out of 82 children (aged 1–6 years) ‘passed’ the test by removing the mark using the reflected image. The authors' interpretation of these results was that the test produced false negatives and instead measured implicit compliance to the local authority figure who placed the mark on the child. This raises the possibility that the mirror test may lack construct validity in cross-cultural contexts—in other words, that it may not measure the theoretical construct it was designed to measure.
As we discussed previously, survey researchers want to make sure everyone receives the same questionnaire, but how can we be sure everyone understands the questionnaire in the same way? Cultural equivalence means that a measure produces comparable data when employed in different cultural populations (Van de Vijver & Poortinga, 1992).[95] If concepts differ in meaning across cultures, cultural bias may better explain what is going on with your key variables better than your hypotheses. Cultural bias may result because of poor item translation, inappropriate content of items, and unstandardized procedures (Waltz et al., 2010).[96] Of particular importance is construct bias, or "when the construct measured is not identical across cultures or when behaviors that characterize the construct are not identical across cultures" (Meiring et al., 2005, p. 2)[97] Construct bias emerges when there is: a) disagreement about the appropriateness of content, b) inadequate sampling, c) underrepresentation of the construct, and d) incomplete overlap of the construct across cultures (Van de Vijver & Poortinga, 1992).[98]
Addressing cultural bias
To address these issues, we propose that careful scrutiny of (a) study site selection, (b) community involvement and (c) culturally appropriate research methods. Particularly for those initiating collaborative cross-cultural projects, we focus here on pragmatic and implementable steps. For student researchers, it is important to be aware of these issues and assess for them in the strengths and limitations of your own study, though the degree to which you can feasibly implement some of these measures will be impaired by a lack of resources.
Study site selection
Researchers are increasingly interested in cross-cultural research applicable outside of WEIRD contexts., but this has sometimes led to an uncritical and haphazard inclusion of ‘non-WEIRD’ populations in cross-cultural research without further regard for why specific populations should be included (Barrett, 2020).[99] One particularly egregious example is the grouping of all non-Western populations as a comparative sample to the cultural West (i.e. the ‘West versus rest’ approach) is often unwittingly adopted by researchers performing cross-cultural research (Henrich, 2010).[100] Other researcher errors include the exoticization of particular cultures or viewing non-Western cultures as a window into the past rather than cultures that have co-evolved over time.
Thus, some of the cultural biases in survey research emerge when researchers fail to identify a clear theoretical justification for inclusion of any subpopulation—WEIRD or not—based on knowledge of the relevant cultural and/or environmental context (see Tucker, 2017[101] for a good example). For example, a researcher asking about satisfaction with daycare must acquire the relevant cultural and environmental knowledge about a daycare that caters exclusively to Orthodox Jewish families. Simply including this study site without doing appropriate background research and identifying a specific aspect of this cultural group that is of theoretical interest in your study (e.g., spirituality and parenthood) indicates a lack of rigor in research. It undercuts the validity and generalizability of your findings by introducing sources of cultural bias that are unexamined in your study.
Sampling decisions are also important as they involve unique ethical and social challenges. For example, foreign researchers (as sources of power, information and resources) represent both opportunities for and threats to community members. These relationships are often complicated by power differentials due to unequal access to wealth, education and historical legacies of colonization. As such, it is important that investigators are alert to the possible bias among individuals who initially interact with researchers, to the potential negative consequences for those excluded, and to the (often unspoken) power dynamics between the researcher and their study participants (as well as among and between study participants).
We suggest that a necessary first step is to carefully consult existing resources outlining best practices for ethical principles of research before engaging in cross-cultural research. Many of these resources have been developed over years of dialogue in various academic and professional societies (e.g. American Anthropological Association, International Association for Cross Cultural Psychology, International Union of Psychological Science). Furthermore, communities themselves are developing and launching research-based codes of ethics and providing carefully curated open-access materials such as those from the Indigenous Peoples' Health Research Centre, often written in consultation with ethicists in low- to middle-income countries (see Schroeder et al., 2019).[102]
Community involvement
Too often researchers engage in ‘extractive’ research, whereby a researcher selects a study community and collects the necessary data to exclusively further their own scientific and/or professional goals without benefiting the community. This reflects a long history of colonialism in social science. Extractive methods lead to methodological flaws and alienate participants from the scientific process, poisoning the well of scientific knowledge on a macro level. Many researchers are associated with institutions tainted with colonial, racist and sexist histories, sentiments and in some instances perpetuating into the present. Much cross-cultural research is carried out in former or contemporary colonies, and in the colonial language. Explicit and implicit power differentials create ethical challenges that can be acknowledged by researchers and in the design of their study (see Schuller, 2010[103] for an example in which the power and politics of various roles played by researchers).
An understanding of cultural norms may ensure that data collection and questionnaire design are culturally and linguistically relevant. This can be achieved by implementing several complementary strategies. A first step may be to collaborate with members of the study community to check the relevance of the instruments being used. Incorporating perspectives from the study community from the outset can reduce the likelihood of making scientific errors in measurement and inference (First Nations Information Governance Centre, 2014).[104]
An additional approach is to use mixed methods in data collection, such that each method ‘checks’ the data collected using the other methods. A recent paper by Fisher and Poortinga (2018)[105] provides suggestions for a rigorous methodological approach to conducting cross-cultural comparative psychology, underscoring the importance of using multiple methods with an eye towards a convergence of evidence. A mixed-method approach can incorporate a variety of qualitative methods over and on top of a quantitative survey including open-ended questions, focus groups, and interviews.
Research design and methods
It is critical that researchers translate the language, technological references and stimuli as well as examine the underlying cultural context of the original method for assumptions that rely upon WEIRD epistemologies (Hrushcka, 2020).[106] This extends to non-complex visual aids, attempting to ensure that even scales measure what the researcher is intending (see Purzycki and Lang, 2019[107] for discussion on the use of a popular economic experiment in small-scale societies).
For more information on assessing cultural equivalence, consult this free training from RTI International, a well-regarded non-profit research firm, entitled “The essential role of language in survey design” and this free training from the Center for Capacity Building in Survey Methods and Statistics entitled “Questionnaire design: For surveys in 3MC (multinational, multiregional, and multi cultural) contexts. These trainings guide researchers using survey design through the details of evaluating and writing survey questions using culturally sensitive language. Moreover, if you are planning to conduct cross-cultural research, you should consult this guide for assessing measurement equivalency and bias across cultures, as well.
Key Takeaways
- Bias can come from both how questionnaire items are presented to participants as well as how participants are recruited and respond to surveys.
- Cultural bias emerges from the differences in how people think and behave across cultures.
- Cross-cultural research requires a theoretically-informed sampling approach, evaluating measurement equivalency across cultures, and generalizing findings with caution.
Exercises
Review your questionnaire and assess it for potential sources of bias.
- Include the results of pilot testing from the previous exercise.
- Make any changes to your questionnaire (or sampling approach) you think would reduce the potential for bias in your study.
Create a first draft of your limitations section by identifying sources of bias in your survey.
- Write a bulleted list or paragraph or the potential sources of bias in your study.
- Remember that all studies, especially student-led studies, have limitations. To the extent you can address these limitations now and feasibly make changes, do so. But keep in mind that your goal should be more to correctly describe the bias in your study than to collect bias-free results. Ultimately, your study needs to get done!
